CREMA: A Contrastive Regularized Masked Autoencoder for Robust ECG Diagnostics across Clinical Domains
作者: Junho Song, Jong-Hwan Jang, DongGyun Hong, Joon-myoung Kwon, Yong-Yeon Jo
分类: cs.LG, cs.AI, eess.SP
发布日期: 2024-06-26 (更新: 2025-08-21)
备注: 10 pages
💡 一句话要点
CREMA:一种对比正则化掩码自编码器,用于跨临床领域的稳健心电图诊断
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 心电图诊断 自监督学习 掩码自编码器 对比学习 Transformer 时间序列分析 医疗人工智能
📋 核心要点
- 心电图诊断面临标注数据不足和需捕捉细微临床变化的挑战,现有方法泛化性有限。
- CREMA通过对比正则化掩码自编码器学习心电图通用表示,结合生成学习和对比学习。
- 实验表明,CREMA在基准数据集和真实临床环境中均优于现有模型,展现了其稳健性。
📝 摘要(中文)
心电图(ECG)诊断面临着标注数据有限以及需要捕捉节律和形态中细微但具有临床意义的变化的挑战。我们提出了CREMA(对比正则化掩码自编码器),这是一个为12导联心电图设计的基础模型,旨在通过自监督预训练学习可泛化的表示。CREMA结合了生成学习和对比正则化,通过对比正则化MAE损失实现,并采用信号Transformer (SiT)架构来捕获局部波形细节和全局时间依赖性。我们在基准数据集和真实临床环境中评估了CREMA,包括具有显著分布偏移的部署场景。在线性探测和微调评估中,CREMA优于监督基线和现有的自监督模型。值得注意的是,它在急诊护理等不同临床领域保持了卓越的性能,突显了其在真实条件下的稳健性。这些结果表明,CREMA可以作为心电图诊断的可扩展且可靠的基础模型,支持异构和高风险临床环境中的下游应用。
🔬 方法详解
问题定义:心电图诊断面临着标注数据稀缺和模型泛化能力不足的问题,尤其是在不同临床领域和存在数据分布偏移的情况下。现有方法难以有效捕捉心电信号中细微但具有临床意义的特征,导致诊断准确率下降。
核心思路:CREMA的核心思路是利用自监督学习,通过掩码自编码器(MAE)进行预训练,学习心电信号的通用表示。同时,引入对比正则化,促使模型学习对数据分布变化更鲁棒的特征。这种结合生成学习和对比学习的方式,旨在提高模型在不同临床环境下的泛化能力。
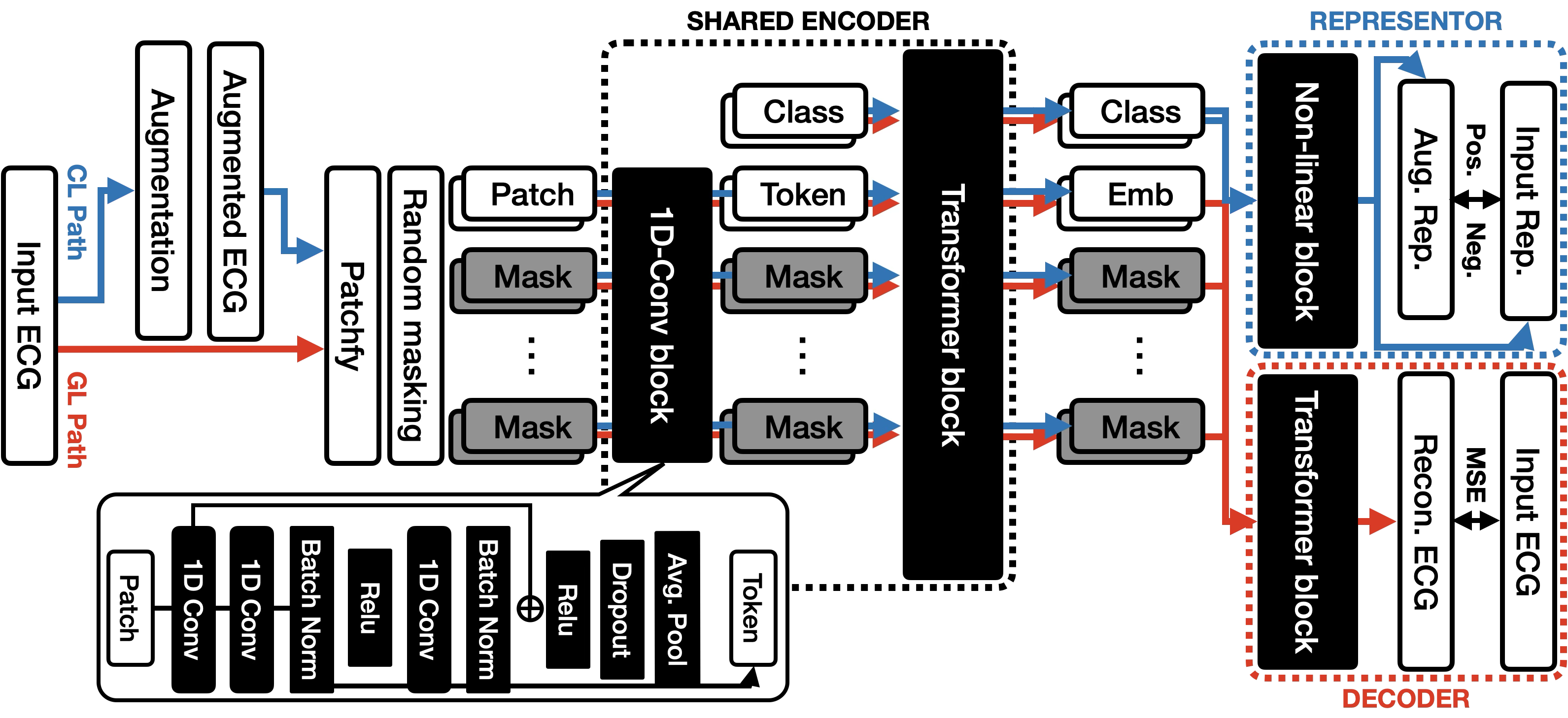
技术框架:CREMA的技术框架主要包括三个部分:1)信号Transformer (SiT) 编码器,用于提取心电信号的特征;2)掩码机制,随机掩盖部分输入信号,迫使模型学习从上下文重建被掩盖的部分;3)对比正则化模块,通过对比学习,拉近同一心电信号的不同增强视图,推开不同信号的表示。整个框架通过对比正则化MAE损失进行训练。
关键创新:CREMA的关键创新在于将对比学习和掩码自编码器相结合,提出了对比正则化MAE损失。这种结合方式既能利用MAE的生成能力学习信号的内在结构,又能通过对比学习提高模型对数据分布变化的鲁棒性。此外,SiT架构的设计也考虑了心电信号的特点,能够有效捕捉局部波形细节和全局时间依赖性。
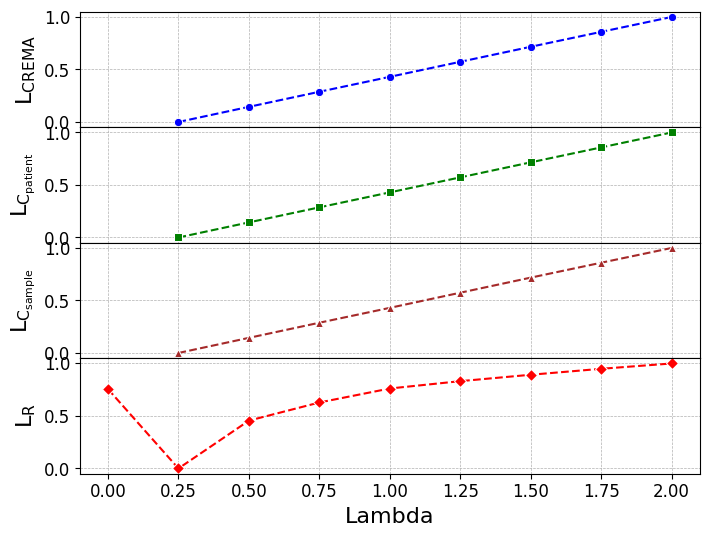
关键设计:CREMA的关键设计包括:1)掩码比例的选择,需要平衡重建任务的难度和模型的学习效率;2)对比学习中的正负样本选择策略,需要保证正样本具有相似的语义信息,负样本具有足够的区分度;3)SiT架构中Transformer块的层数和隐藏层大小,需要根据数据集的大小和复杂度进行调整;4)对比正则化损失的权重,需要平衡生成学习和对比学习的贡献。
🖼️ 关键图片
📊 实验亮点
CREMA在多个心电图数据集上进行了评估,包括基准数据集和真实临床环境数据。实验结果表明,CREMA在线性探测和微调任务中均优于监督学习方法和现有的自监督学习模型。尤其是在具有显著数据分布偏移的临床环境中,CREMA的性能优势更加明显,验证了其在真实世界应用中的稳健性。
🎯 应用场景
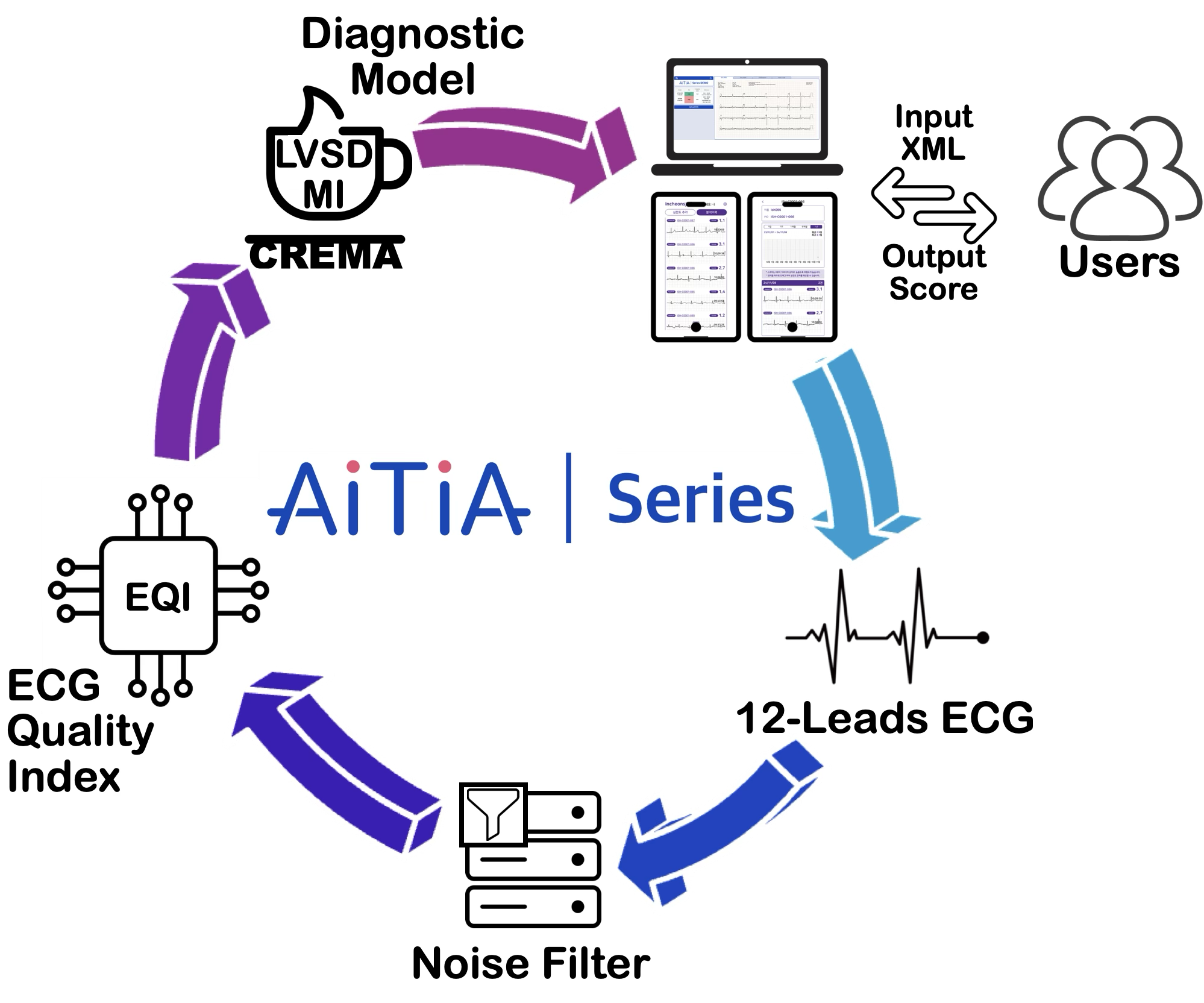
CREMA作为心电图诊断的基础模型,可广泛应用于远程医疗、急诊护理、术后监护等场景。它能够提高心电图诊断的准确性和效率,辅助医生进行疾病筛查和风险评估,尤其是在资源有限或缺乏专业医生的地区具有重要价值。未来,CREMA有望与其他医疗数据(如影像、病历)相结合,构建更全面的智能诊断系统。
📄 摘要(原文)
Electrocardiogram (ECG) diagnosis remains challenging due to limited labeled data and the need to capture subtle yet clinically meaningful variations in rhythm and morphology. We present CREMA (Contrastive Regularized Masked Autoencoder), a foundation model for 12-lead ECGs designed to learn generalizable representations through self-supervised pretraining. CREMA combines generative learning and contrastive regularization via a Contrastive Regularized MAE loss, and employs a Signal Transformer (SiT) architecture to capture both local waveform details and global temporal dependencies. We evaluate CREMA on benchmark datasets and real-world clinical environments, including deployment scenarios with significant distribution shifts. CREMA outperforms supervised baselines and existing self-supervised models in both linear probing and fine-tuning evaluations. Notably, it maintains superior performance across diverse clinical domains, such as emergency care, highlighting its robustness under real-world conditions. These results demonstrate that CREMA serves as a scalable and reliable foundation model for ECG diagnostics, supporting downstream applications across heterogeneous and high-risk clinical settings.