LABOR-LLM: Language-Based Occupational Representations with Large Language Models
作者: Susan Athey, Herman Brunborg, Tianyu Du, Ayush Kanodia, Keyon Vafa
分类: cs.LG, cs.CL, econ.EM
发布日期: 2024-06-25 (更新: 2026-01-02)
💡 一句话要点
LABOR-LLM:利用大型语言模型进行基于语言的职业表征,预测职业变迁。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 职业预测 劳动力市场 序列预测 迁移学习 文本挖掘 职业变迁
📋 核心要点
- 现有方法难以有效处理高维职业序列数据,并准确预测工人的职业变迁,尤其是在离散职业选择众多的情况下。
- 利用大型语言模型(LLM)的强大文本处理能力,将职业历史转化为文本,并通过微调LLM来预测下一个职业。
- 实验表明,该方法在预测职业变迁方面优于现有模型,并且微调较小的LLM在添加更多数据后可以超越微调较大的LLM。
📝 摘要(中文)
本文构建了一个经验模型,该模型将工人的职业历史作为函数,来预测工人的下一个职业。由于职业历史是职业的序列,因此协变量空间是高维的,而且结果(下一个职业)是一个离散选择,可以取许多值。为了估计模型的参数,我们利用了生成式人工智能的方法。估计从在非代表性数据上训练的“基础模型”开始,然后使用来自代表性调查的职业数据“微调”估计。我们将来自调查的表格数据转换为类似于简历的文本文件,并使用这些文本文件微调基础模型(大型语言模型,LLM)的参数,目标是预测下一个token(单词)。由此产生的微调LLM用于计算工人转移概率的估计值。其预测性能超过了所有先前的模型,无论是用于精细地预测下一个职业,还是用于预测工人是否改变职业或留在劳动力市场等特定任务。我们量化了微调的价值,并进一步表明,通过添加来自不同人群的更多职业数据,微调较小的LLM(较少的参数)超过了微调较大模型的性能。当我们省略英语职业名称并将其替换为唯一代码时,预测性能会下降。
🔬 方法详解
问题定义:论文旨在解决基于工人的职业历史预测其未来职业的问题。现有方法在高维职业序列数据处理和离散职业选择预测方面存在不足,难以准确捕捉职业变迁的复杂模式。传统的统计模型和机器学习方法难以有效处理这种复杂性,并且泛化能力有限。
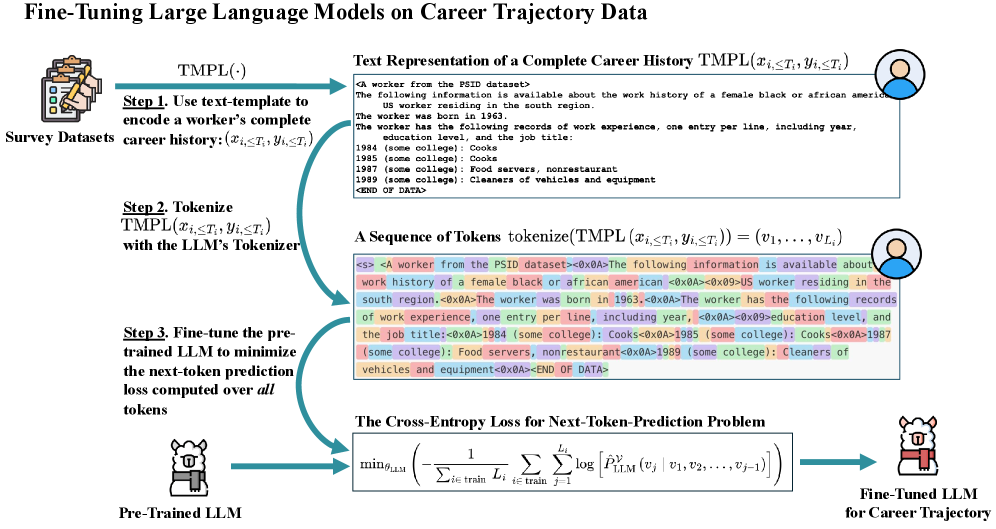
核心思路:论文的核心思路是将职业历史视为文本序列,并利用大型语言模型(LLM)的强大文本处理能力来学习职业之间的关系。通过将职业历史转换为类似于简历的文本格式,可以利用LLM的预训练知识和微调能力,从而更有效地预测未来的职业变迁。这种方法借鉴了自然语言处理领域的成功经验,将职业预测问题转化为序列预测问题。
技术框架:整体框架包括以下几个主要阶段:1) 数据准备:将来自调查的表格数据转换为文本文件,模拟简历格式,包含职业历史信息。2) 模型选择:选择一个预训练的大型语言模型作为基础模型。3) 模型微调:使用转换后的职业数据微调LLM,目标是预测序列中的下一个token(即下一个职业)。4) 预测:使用微调后的LLM计算工人转移概率,并预测未来的职业。
关键创新:最重要的技术创新点在于将大型语言模型应用于职业预测领域,并利用其强大的文本处理能力来学习职业之间的复杂关系。与传统方法相比,该方法能够更好地捕捉职业变迁的模式,并提高预测的准确性。此外,论文还发现,通过添加更多数据,微调较小的LLM可以超越微调较大的LLM的性能,这为资源有限的研究人员提供了一种更经济有效的解决方案。
关键设计:论文的关键设计包括:1) 将表格数据转换为文本格式,以便LLM能够处理。2) 使用交叉熵损失函数来训练LLM,目标是最大化预测下一个职业的概率。3) 探索不同大小的LLM,并研究数据量对模型性能的影响。4) 通过实验验证了微调的价值,并量化了不同因素对预测性能的影响。
🖼️ 关键图片


📊 实验亮点
实验结果表明,基于LLM的职业预测模型在预测下一个职业以及预测工人是否改变职业或留在劳动力市场等特定任务上,均优于所有先前的模型。研究还发现,通过添加来自不同人群的更多职业数据,微调较小的LLM(参数较少)可以超越微调较大模型的性能。当省略英语职业名称并将其替换为唯一代码时,预测性能会下降,突出了语言信息的重要性。
🎯 应用场景
该研究成果可应用于劳动力市场分析、职业规划、人才推荐等领域。政府和企业可以利用该模型预测劳动力市场的变化趋势,制定更有效的就业政策和人才发展战略。个人可以利用该模型进行职业规划,了解不同职业之间的转移概率,并做出更明智的职业选择。此外,该模型还可以用于构建智能招聘系统,提高人才匹配的效率。
📄 摘要(原文)
This paper builds an empirical model that predicts a worker's next occupation as a function of the worker's occupational history. Because histories are sequences of occupations, the covariate space is high-dimensional, and further, the outcome (the next occupation) is a discrete choice that can take on many values. To estimate the parameters of the model, we leverage an approach from generative artificial intelligence. Estimation begins from a
foundation model'' trained on non-representative data and thenfine-tunes'' the estimation using data about careers from a representative survey. We convert tabular data from the survey into text files that resemble resumes and fine-tune the parameters of the foundation model, a large language model (LLM), using these text files with the objective of predicting the next token (word). The resulting fine-tuned LLM is used to calculate estimates of worker transition probabilities. Its predictive performance surpasses all prior models, both for the task of granularly predicting the next occupation as well as for specific tasks such as predicting whether the worker changes occupations or stays in the labor force. We quantify the value of fine-tuning and further show that by adding more career data from a different population, fine-tuning smaller LLMs (fewer parameters) surpasses the performance of fine-tuning larger models. When we omit the English language occupational title and replace it with a unique code, predictive performance declines.