Are Language Models Actually Useful for Time Series Forecasting?
作者: Mingtian Tan, Mike A. Merrill, Vinayak Gupta, Tim Althoff, Thomas Hartvigsen
分类: cs.LG, cs.AI
发布日期: 2024-06-22 (更新: 2024-10-26)
备注: Accepted to NeurIPS 2024 (Spotlight)
💡 一句话要点
研究表明:大型语言模型在时间序列预测中可能并非必要组件
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列预测 大型语言模型 消融研究 注意力机制 模型评估
📋 核心要点
- 现有基于LLM的时间序列预测方法计算成本高昂,但其有效性缺乏充分验证。
- 该研究通过消融实验,探究LLM在时间序列预测中的实际作用,并寻找更高效的替代方案。
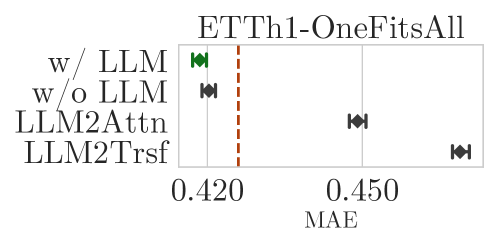
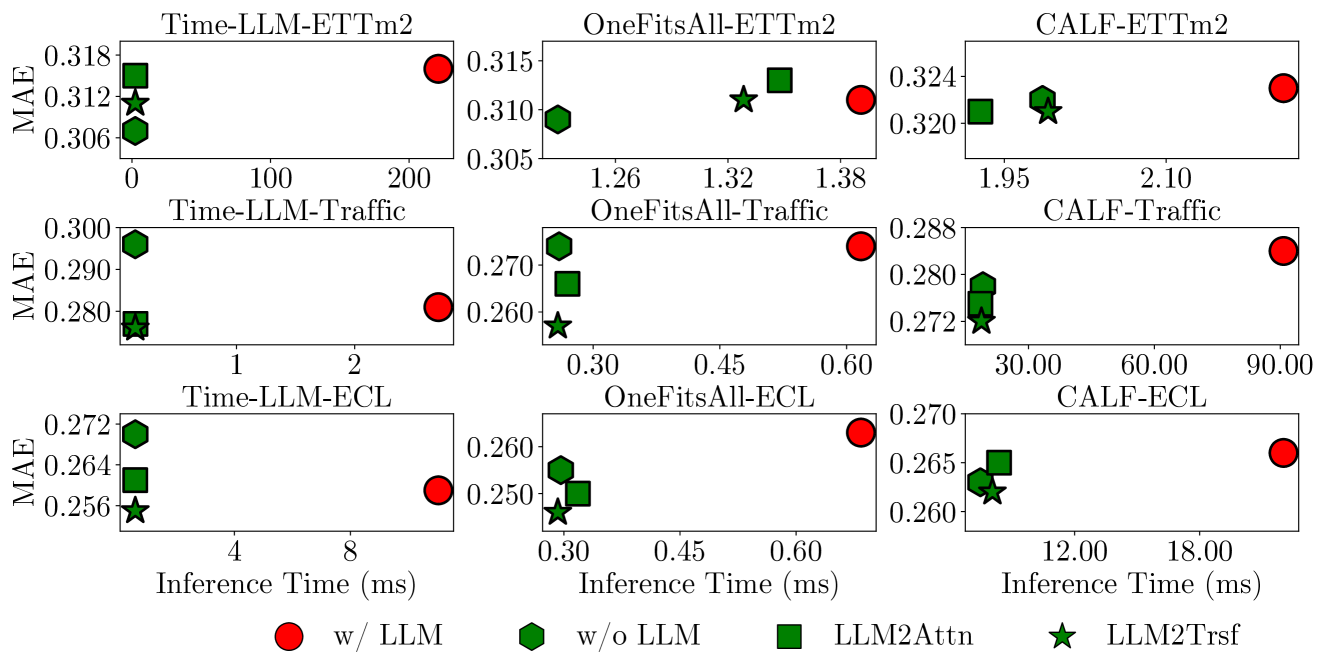
- 实验结果表明,移除LLM或替换为简单注意力层,预测性能通常不降反升,预训练LLM优势不明显。
📝 摘要(中文)
大型语言模型(LLM)正被应用于时间序列预测。但是,语言模型对于时间序列真的有用吗?通过对三种最新且流行的基于LLM的时间序列预测方法进行一系列消融研究,我们发现移除LLM组件或将其替换为基本注意力层并不会降低预测性能——在大多数情况下,结果甚至有所改善!我们还发现,尽管预训练LLM具有显著的计算成本,但它们并不比从头开始训练的模型表现更好,不能很好地表示时间序列中的序列依赖关系,并且不能帮助进行少样本学习。此外,我们探索了时间序列编码器,发现patching和注意力结构与基于LLM的预测器表现相似。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在时间序列预测任务中的实际效用。现有方法直接将LLM应用于时间序列,但其计算成本高昂,且缺乏对LLM有效性的深入分析。痛点在于,不清楚LLM是否真的能提升时间序列预测的性能,或者是否存在更简单、更高效的替代方案。
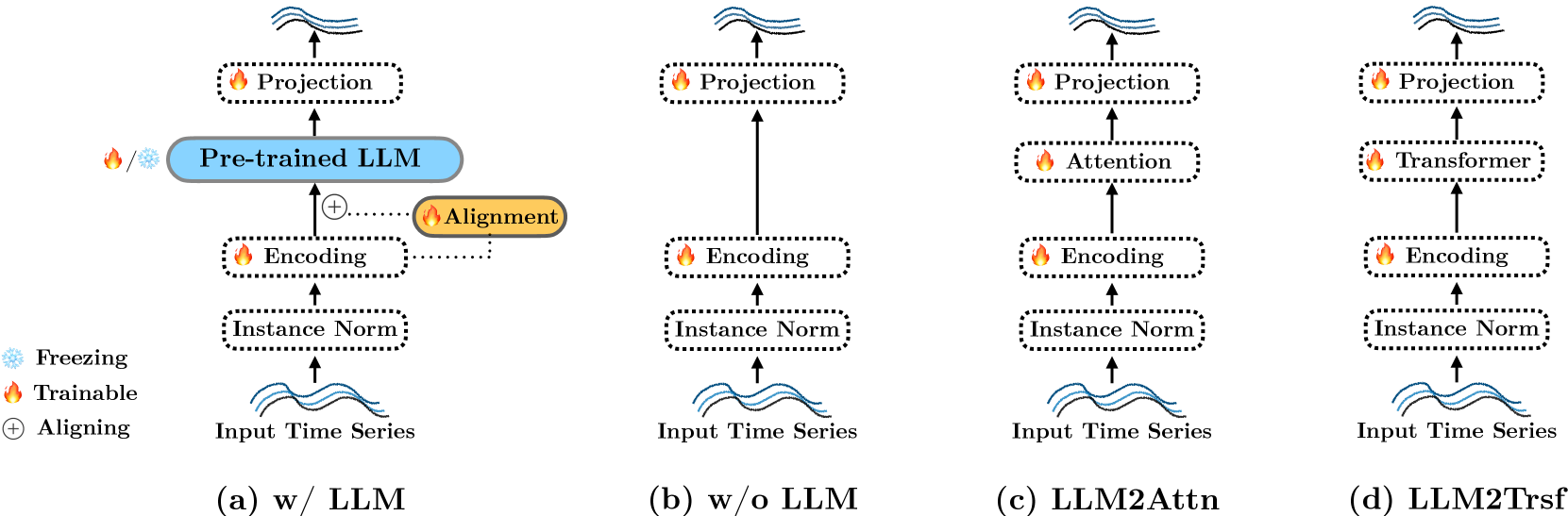
核心思路:论文的核心思路是通过消融实验,系统性地移除或替换现有基于LLM的时间序列预测模型中的LLM组件,并观察预测性能的变化。如果移除LLM后性能没有显著下降,甚至有所提升,则表明LLM并非时间序列预测的关键组件。同时,研究还比较了预训练LLM和从头训练的模型,以及其他时间序列编码器的性能。
技术框架:研究主要包含以下几个步骤:1) 选择三种流行的基于LLM的时间序列预测模型作为研究对象。2) 对这些模型进行消融实验,包括移除LLM组件、替换为基本注意力层等。3) 比较不同模型的预测性能,包括准确率、均方误差等指标。4) 比较预训练LLM和从头训练的模型的性能。5) 探索其他时间序列编码器(如基于patching和attention的结构)的性能。
关键创新:论文最重要的技术创新点在于,通过严谨的消融实验,揭示了LLM在时间序列预测中可能并非必要组件。这挑战了当前将LLM直接应用于时间序列预测的趋势,并为未来研究提供了新的方向,即探索更简单、更高效的时间序列预测方法。与现有方法的本质区别在于,该研究并非简单地应用LLM,而是深入分析了LLM的实际作用。
关键设计:论文的关键设计包括:1) 选择具有代表性的基于LLM的时间序列预测模型。2) 设计合理的消融实验,确保能够准确评估LLM的作用。3) 使用标准的时间序列预测数据集进行实验,保证结果的可重复性和可比性。4) 采用多种评价指标,全面评估模型的性能。具体参数设置、损失函数和网络结构等细节,遵循原始论文中被消融的LLM模型。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在大多数情况下,移除LLM组件或将其替换为基本注意力层,预测性能甚至有所改善。预训练LLM并不比从头开始训练的模型表现更好,且不能很好地表示时间序列中的序列依赖关系。这些发现挑战了当前将LLM应用于时间序列预测的趋势,并为未来研究提供了新的方向。
🎯 应用场景
该研究成果可应用于各种时间序列预测场景,例如金融市场预测、销售预测、能源需求预测等。通过避免使用不必要的LLM,可以显著降低计算成本,提高预测效率。此外,该研究也为未来时间序列预测模型的设计提供了新的思路,即关注更简单、更高效的结构,而非盲目追求复杂模型。
📄 摘要(原文)
Large language models (LLMs) are being applied to time series forecasting. But are language models actually useful for time series? In a series of ablation studies on three recent and popular LLM-based time series forecasting methods, we find that removing the LLM component or replacing it with a basic attention layer does not degrade forecasting performance -- in most cases, the results even improve! We also find that despite their significant computational cost, pretrained LLMs do no better than models trained from scratch, do not represent the sequential dependencies in time series, and do not assist in few-shot settings. Additionally, we explore time series encoders and find that patching and attention structures perform similarly to LLM-based forecasters.