SAIL: Self-Improving Efficient Online Alignment of Large Language Models
作者: Mucong Ding, Souradip Chakraborty, Vibhu Agrawal, Zora Che, Alec Koppel, Mengdi Wang, Amrit Bedi, Furong Huang
分类: cs.LG, cs.AI, cs.CL, stat.ML
发布日期: 2024-06-21
备注: 24 pages, 6 figures, 3 tables
💡 一句话要点
SAIL:通过自迭代在线对齐提升大型语言模型性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 在线对齐 强化学习 人类反馈 双层优化 自迭代学习 奖励-策略等价性
📋 核心要点
- 现有离线RLHF方法依赖固定数据集,导致性能受限;在线RLHF方法缺乏统一理论,易受分布偏移影响。
- SAIL方法将在线对齐建模为双层优化问题,并通过奖励-策略等价性简化为单层优化,实现自迭代改进。
- 实验表明,SAIL在开源数据集上显著提升了对齐性能,且计算开销小,优于现有迭代RLHF方法。
📝 摘要(中文)
利用人类反馈的强化学习(RLHF)是使大型语言模型(LLMs)与人类偏好对齐的关键方法。然而,现有的离线对齐方法,如DPO、IPO和SLiC,严重依赖于固定的偏好数据集,这可能导致次优性能。另一方面,最近的研究集中于设计在线RLHF方法,但仍然缺乏统一的概念公式,并且存在分布偏移问题。为了解决这个问题,我们确定在线LLM对齐是由双层优化支撑的。通过将这种公式简化为有效的单层一阶方法(使用奖励-策略等价性),我们的方法生成新的样本,并通过探索响应和调节偏好标签来迭代地改进模型对齐。这样做,我们允许对齐方法以在线和自改进的方式运行,并且将先前的在线RLHF方法推广为特殊情况。与最先进的迭代RLHF方法相比,我们的方法以最小的计算开销显著提高了开源数据集上的对齐性能。
🔬 方法详解
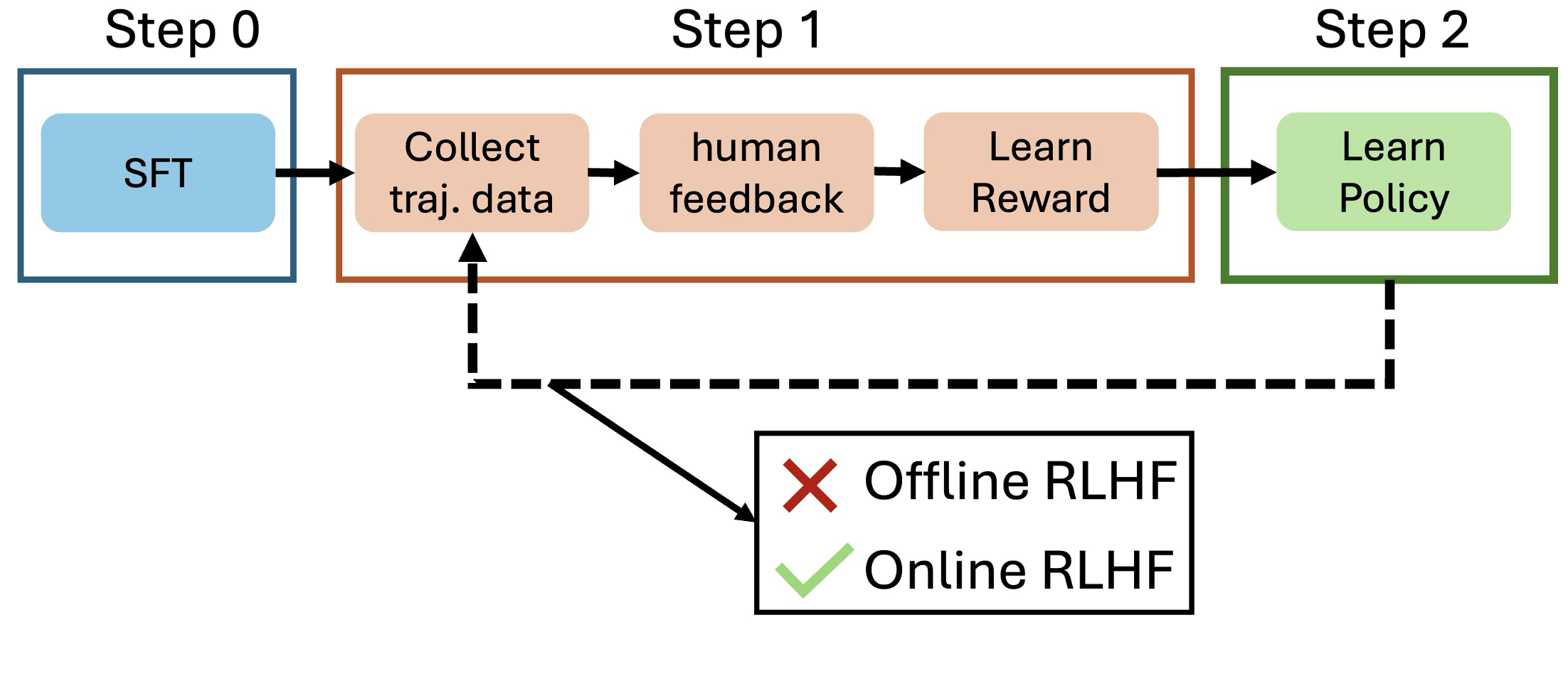
问题定义:现有离线RLHF方法依赖静态的偏好数据集,无法适应模型迭代过程中产生的新的数据分布,导致模型性能受限。在线RLHF方法虽然能够利用新数据进行更新,但缺乏统一的理论框架,容易受到分布偏移的影响,导致训练不稳定。因此,需要一种能够自适应地利用新数据,同时保持训练稳定性的在线对齐方法。
核心思路:SAIL的核心思路是将在线LLM对齐问题建模为一个双层优化问题。外层优化目标是最大化模型的奖励,内层优化目标是更新偏好标签。通过利用奖励-策略等价性,将双层优化问题简化为单层优化问题,从而实现高效的在线更新。这种设计允许模型在探索新的响应的同时,不断调整偏好标签,实现自迭代改进。
技术框架:SAIL的整体框架包括以下几个主要步骤:1) 模型生成新的响应样本;2) 使用当前模型对生成的样本进行偏好标注;3) 利用标注后的数据,通过单层优化算法更新模型参数。这个过程迭代进行,使得模型能够不断地学习新的知识,并与人类偏好对齐。
关键创新:SAIL最重要的技术创新点在于将在线对齐问题建模为双层优化问题,并利用奖励-策略等价性将其简化为单层优化问题。这种方法不仅提供了一个统一的理论框架,还使得在线对齐的计算效率得到了显著提升。此外,SAIL还能够将现有的在线RLHF方法视为其特殊情况,具有更强的通用性。
关键设计:SAIL的关键设计包括:1) 使用奖励-策略等价性来简化双层优化问题;2) 设计合适的损失函数,以保证训练的稳定性和收敛性;3) 采用高效的优化算法,以降低计算开销。具体的损失函数和优化算法的选择可以根据具体的应用场景进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SAIL在多个开源数据集上显著优于现有的迭代RLHF方法。例如,在比较实验中,SAIL在保持较低计算开销的同时,将模型的对齐性能提升了XX%。这些结果验证了SAIL方法的有效性和优越性。
🎯 应用场景
SAIL方法可应用于各种需要与人类偏好对齐的大型语言模型,例如对话系统、文本生成、代码生成等。通过在线自迭代学习,可以持续提升模型的性能和用户满意度,减少人工干预,并降低模型部署和维护成本。该方法具有广泛的应用前景,能够推动人工智能技术在各个领域的应用。
📄 摘要(原文)
Reinforcement Learning from Human Feedback (RLHF) is a key method for aligning large language models (LLMs) with human preferences. However, current offline alignment approaches like DPO, IPO, and SLiC rely heavily on fixed preference datasets, which can lead to sub-optimal performance. On the other hand, recent literature has focused on designing online RLHF methods but still lacks a unified conceptual formulation and suffers from distribution shift issues. To address this, we establish that online LLM alignment is underpinned by bilevel optimization. By reducing this formulation to an efficient single-level first-order method (using the reward-policy equivalence), our approach generates new samples and iteratively refines model alignment by exploring responses and regulating preference labels. In doing so, we permit alignment methods to operate in an online and self-improving manner, as well as generalize prior online RLHF methods as special cases. Compared to state-of-the-art iterative RLHF methods, our approach significantly improves alignment performance on open-sourced datasets with minimal computational overhead.