Mixture of Attention Spans: Optimizing LLM Inference Efficiency with Heterogeneous Sliding-Window Lengths
作者: Tianyu Fu, Haofeng Huang, Xuefei Ning, Genghan Zhang, Boju Chen, Tianqi Wu, Hongyi Wang, Zixiao Huang, Shiyao Li, Shengen Yan, Guohao Dai, Huazhong Yang, Yu Wang
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-06-21 (更新: 2025-11-24)
备注: Published at CoLM'25
🔗 代码/项目: GITHUB
💡 一句话要点
提出混合注意力跨度(MoA),优化LLM在长文本场景下的推理效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 长文本处理 滑动窗口注意力 推理效率优化 异构注意力 自适应窗口长度 内存优化
📋 核心要点
- 现有滑动窗口注意力机制采用单一窗口长度,无法捕捉LLM中固有的异构注意力模式,忽略了精度-延迟的权衡。
- MoA的核心思想是为不同的注意力头和层自动定制不同的滑动窗口长度配置,以适应异构注意力模式。
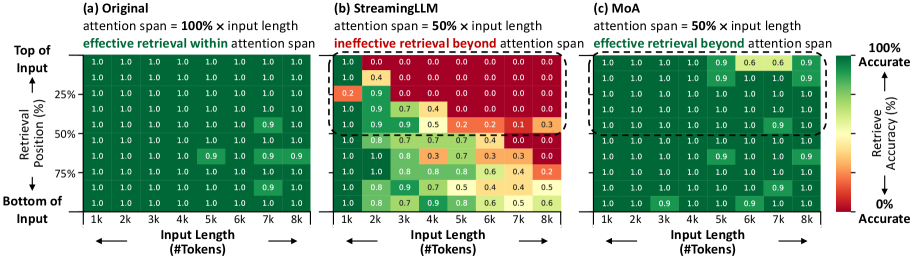
- 实验表明,MoA显著提升了有效上下文长度和检索准确率,同时降低了GPU内存占用并提高了解码吞吐量。
📝 摘要(中文)
本文提出了一种名为混合注意力跨度(MoA)的方法,旨在解决大型语言模型(LLM)在长文本场景中面临的内存和吞吐量挑战。MoA通过为不同的注意力头和层自动定制不同的滑动窗口长度配置来实现这一目标。它构建并探索了一个包含各种窗口长度及其相对于输入大小的缩放规则的搜索空间。通过对模型进行性能分析,评估潜在的配置,并确定每个头的最佳长度配置。MoA能够适应不同的输入大小,揭示了一些注意力头会扩展其关注范围以适应更长的输入,而另一些则始终专注于固定长度的局部上下文。实验结果表明,MoA在相同的平均滑动窗口长度下,有效上下文长度提高了3.9倍,在Vicuna-{7B, 13B}和Llama3-{8B, 70B}模型上,检索准确率比统一窗口基线提高了1.5-7.1倍。此外,MoA缩小了与全注意力机制的性能差距,将最大相对性能下降从9%-36%降低到5%以内。MoA实现了1.2-1.4倍的GPU内存减少,并使解码吞吐量比FlashAttention2和vLLM分别提高了6.6-8.2倍和1.7-1.9倍,且性能影响极小。
🔬 方法详解
问题定义:现有的大型语言模型在处理长文本时,滑动窗口注意力机制通常采用统一的窗口长度,这无法有效捕捉不同注意力头和层之间的异构性。这种统一的方法忽略了不同注意力头对上下文信息的不同需求,导致次优的精度-延迟权衡。
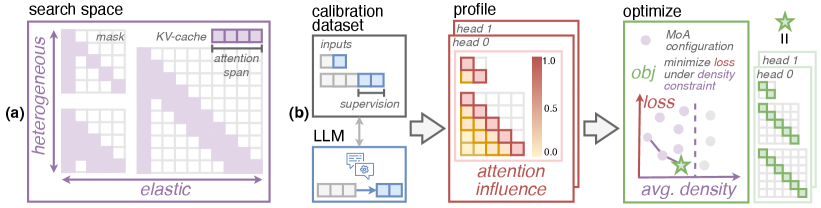
核心思路:MoA的核心思路是根据每个注意力头和层对上下文信息的不同需求,自适应地调整滑动窗口的长度。通过构建一个包含各种窗口长度及其缩放规则的搜索空间,并对模型进行性能分析,MoA能够为每个头选择最佳的窗口长度配置,从而实现更高效的推理。
技术框架:MoA的整体框架包括以下几个主要阶段:1) 构建窗口长度搜索空间,包含不同的窗口长度和缩放规则;2) 对模型进行性能分析,评估不同窗口长度配置的精度和延迟;3) 使用搜索算法(具体算法未知)找到每个注意力头的最佳窗口长度配置;4) 在推理过程中,根据输入长度动态调整窗口长度。
关键创新:MoA的关键创新在于其自适应地为不同的注意力头和层分配不同的滑动窗口长度。与传统的统一窗口长度方法相比,MoA能够更好地捕捉LLM中固有的异构注意力模式,从而提高模型的性能和效率。
关键设计:论文中没有明确给出关键参数设置、损失函数或网络结构的细节。但可以推断,搜索算法的选择和性能分析的指标(精度、延迟)是关键的设计因素。此外,窗口长度的缩放规则也可能对模型的性能产生重要影响。具体实现细节未知。
🖼️ 关键图片
📊 实验亮点
MoA在Vicuna和Llama3模型上进行了实验,结果表明,在相同的平均滑动窗口长度下,MoA将有效上下文长度提高了3.9倍,检索准确率提高了1.5-7.1倍。与FlashAttention2和vLLM相比,MoA实现了1.2-1.4倍的GPU内存减少,并使解码吞吐量分别提高了6.6-8.2倍和1.7-1.9倍,且性能影响极小。MoA还缩小了与全注意力机制的性能差距,将最大相对性能下降降低到5%以内。
🎯 应用场景
MoA适用于需要处理长文本的各种应用场景,例如文档摘要、机器翻译、问答系统和代码生成。通过提高LLM的推理效率和降低内存占用,MoA可以使这些应用在资源受限的设备上运行,并支持处理更长的输入序列。MoA还有潜力应用于其他类型的注意力机制,进一步提升模型的性能和效率。
📄 摘要(原文)
Sliding-window attention offers a hardware-efficient solution to the memory and throughput challenges of Large Language Models (LLMs) in long-context scenarios. Existing methods typically employ a single window length across all attention heads and input sizes. However, this uniform approach fails to capture the heterogeneous attention patterns inherent in LLMs, ignoring their distinct accuracy-latency trade-offs. To address this challenge, we propose Mixture of Attention Spans (MoA), which automatically tailors distinct sliding-window length configurations to different heads and layers. MoA constructs and navigates a search space of various window lengths and their scaling rules relative to input sizes. It profiles the model, evaluates potential configurations, and pinpoints the optimal length configurations for each head. MoA adapts to varying input sizes, revealing that some attention heads expand their focus to accommodate longer inputs, while other heads consistently concentrate on fixed-length local contexts. Experiments show that MoA increases the effective context length by 3.9x with the same average sliding-window length, boosting retrieval accuracy by 1.5-7.1x over the uniform-window baseline across Vicuna-{7B, 13B} and Llama3-{8B, 70B} models. Moreover, MoA narrows the performance gap with full attention, reducing the maximum relative performance drop from 9%-36% to within 5% across three long-context understanding benchmarks. MoA achieves a 1.2-1.4x GPU memory reduction, boosting decode throughput by 6.6-8.2x and 1.7-1.9x over FlashAttention2 and vLLM, with minimal performance impact. Our code is available at: https://github.com/thu-nics/MoA