LatentExplainer: Explaining Latent Representations in Deep Generative Models with Multimodal Large Language Models
作者: Mengdan Zhu, Raasikh Kanjiani, Jiahui Lu, Andrew Choi, Qirui Ye, Liang Zhao
分类: cs.LG, cs.CL, cs.CV
发布日期: 2024-06-21 (更新: 2025-12-18)
备注: Accepted to CIKM 2025 Full Research Track
💡 一句话要点
LatentExplainer:利用多模态大语言模型解释深度生成模型中的隐变量
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 深度生成模型 隐变量解释 多模态大语言模型 可解释性AI 生成模型分析
📋 核心要点
- 现有方法难以解释深度生成模型中的隐变量,阻碍了对模型内部机制的理解和控制。
- LatentExplainer通过扰动隐变量,观察生成数据的变化,并利用多模态大语言模型生成语义解释。
- 实验表明,LatentExplainer在多个数据集上生成了高质量的隐变量解释,提升了模型可解释性。
📝 摘要(中文)
深度生成模型,如VAEs和扩散模型,通过利用隐变量学习数据分布并生成高质量样本,推动了各种生成任务的发展。尽管可解释性AI领域在解释机器学习模型方面取得了进展,但理解生成模型中的隐变量仍然具有挑战性。本文提出了LatentExplainer,一个自动生成深度生成模型中隐变量的语义解释的框架。LatentExplainer解决了三个主要挑战:推断隐变量的含义,将解释与归纳偏置对齐,以及处理不同程度的可解释性。我们的方法扰动隐变量,解释生成数据的变化,并使用多模态大语言模型(MLLMs)来产生人类可理解的解释。我们在几个真实世界和合成数据集上评估了我们提出的方法,结果表明在为隐变量生成高质量解释方面表现优异。结果突出了结合归纳偏置和不确定性量化的有效性,显著增强了模型的可解释性。
🔬 方法详解
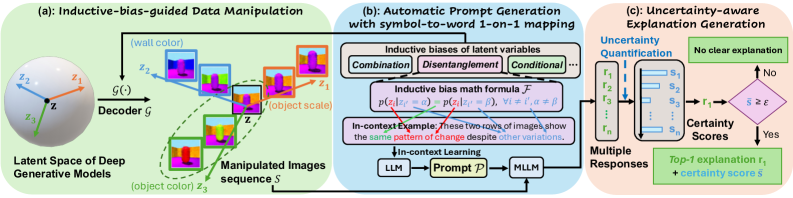
问题定义:深度生成模型(如VAE、扩散模型)的隐变量难以理解,这限制了我们对模型如何表示和生成数据的理解。现有的可解释性方法主要集中在判别模型上,缺乏针对生成模型隐变量的有效解释工具。因此,如何自动、准确地解释隐变量的语义含义是一个关键问题。
核心思路:LatentExplainer的核心思路是通过观察隐变量的微小变化对生成结果的影响来推断其语义。具体来说,通过对隐变量进行扰动,并分析生成数据相应的变化,从而理解该隐变量控制的生成属性。然后,利用多模态大语言模型将这些变化转化为人类可理解的语义解释。
技术框架:LatentExplainer框架主要包含以下几个阶段:1) 隐变量扰动:对选定的隐变量进行微小的扰动。2) 生成数据变化分析:观察扰动后的隐变量生成的数据与原始数据之间的差异。3) 多模态解释生成:利用多模态大语言模型(MLLM),将生成数据的变化转化为自然语言描述,作为对隐变量的解释。框架还考虑了归纳偏置和不确定性量化,以提高解释的质量和可靠性。
关键创新:LatentExplainer的关键创新在于:1) 结合隐变量扰动和生成数据变化分析:通过观察隐变量的微小变化对生成结果的影响来推断其语义,这是一种针对生成模型隐变量的有效解释方法。2) 利用多模态大语言模型生成语义解释:将生成数据的变化转化为人类可理解的自然语言描述,使得解释更加直观和易于理解。3) 融入归纳偏置和不确定性量化:通过融入归纳偏置和不确定性量化,可以提高解释的质量和可靠性。
关键设计:在隐变量扰动方面,采用微小的随机扰动或基于梯度的扰动。在生成数据变化分析方面,使用图像差异度量(如LPIPS)或文本相似度度量(如BERTScore)来量化生成数据的变化。在多模态解释生成方面,选择具有强大视觉理解和文本生成能力的MLLM,如BLIP-2或Flamingo。损失函数的设计目标是最大化解释的准确性和可读性,同时最小化不确定性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LatentExplainer在多个真实世界和合成数据集上生成了高质量的隐变量解释。与现有方法相比,LatentExplainer能够更准确地捕捉隐变量的语义含义,并生成更易于理解的自然语言描述。通过结合归纳偏置和不确定性量化,LatentExplainer显著提高了模型的可解释性。
🎯 应用场景
LatentExplainer可应用于各种深度生成模型的可解释性分析,例如图像生成、文本生成和音频生成。它可以帮助研究人员和开发者更好地理解和控制生成模型的行为,从而改进模型的设计和应用。此外,该方法还可以用于发现数据集中隐藏的模式和关系,为数据分析和知识发现提供新的视角。
📄 摘要(原文)
Deep generative models like VAEs and diffusion models have advanced various generation tasks by leveraging latent variables to learn data distributions and generate high-quality samples. Despite the field of explainable AI making strides in interpreting machine learning models, understanding latent variables in generative models remains challenging. This paper introduces LatentExplainer, a framework for automatically generating semantically meaningful explanations of latent variables in deep generative models. LatentExplainer tackles three main challenges: inferring the meaning of latent variables, aligning explanations with inductive biases, and handling varying degrees of explainability. Our approach perturbs latent variables, interprets changes in generated data, and uses multimodal large language models (MLLMs) to produce human-understandable explanations. We evaluate our proposed method on several real-world and synthetic datasets, and the results demonstrate superior performance in generating high-quality explanations for latent variables. The results highlight the effectiveness of incorporating inductive biases and uncertainty quantification, significantly enhancing model interpretability.