Data-Centric AI in the Age of Large Language Models
作者: Xinyi Xu, Zhaoxuan Wu, Rui Qiao, Arun Verma, Yao Shu, Jingtan Wang, Xinyuan Niu, Zhenfeng He, Jiangwei Chen, Zijian Zhou, Gregory Kang Ruey Lau, Hieu Dao, Lucas Agussurja, Rachael Hwee Ling Sim, Xiaoqiang Lin, Wenyang Hu, Zhongxiang Dai, Pang Wei Koh, Bryan Kian Hsiang Low
分类: cs.LG, cs.CL
发布日期: 2024-06-20
备注: Preprint
💡 一句话要点
针对大语言模型,提出以数据为中心的人工智能研究视角
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 数据中心AI 数据管理 数据质量 知识迁移
📋 核心要点
- 现有大语言模型研究对数据的关注不足,忽略了数据在模型开发和推理中的关键作用。
- 论文倡导以数据为中心的研究方法,强调数据质量、数据管理和数据理解的重要性。
- 论文提出了四个以数据为中心的场景,并为每个场景指出了有前景的研究方向和潜在影响。
📝 摘要(中文)
本文提出了一种以数据为中心的人工智能研究视角,重点关注大语言模型(LLM)。我们首先观察到,数据在LLM的开发阶段(例如,预训练和微调)和推理阶段(例如,上下文学习)都至关重要,但研究界对数据的关注却不成比例地低。我们确定了四个以数据为中心的特定场景,包括数据为中心的基准和数据管理、数据归因、知识迁移和推理上下文构建。在每个场景中,我们都强调了数据的重要性,突出了有前景的研究方向,并阐明了对研究社区以及在适用的情况下对整个社会的潜在影响。例如,我们提倡一套针对LLM数据规模和复杂性量身定制的以数据为中心的基准。这些基准可用于开发新的数据管理方法和记录研究工作和结果,这有助于提高人工智能和LLM研究的开放性和透明度。
🔬 方法详解
问题定义:现有的大语言模型研究往往侧重于模型架构的创新,而忽略了数据质量和数据管理的重要性。高质量的数据对于训练出性能优越的大语言模型至关重要。此外,如何理解和利用数据中的知识,以及如何将知识迁移到新的任务中,也是当前研究面临的挑战。现有方法在数据选择、数据清洗、数据增强和数据归因等方面存在不足。
核心思路:论文的核心思路是将数据置于人工智能研究的中心位置,强调数据在模型开发和推理中的关键作用。通过关注数据质量、数据管理和数据理解,可以更好地训练和利用大语言模型。论文认为,未来的研究应该更加重视数据,开发新的数据管理方法和数据分析工具,以提高大语言模型的性能和可靠性。
技术框架:论文并没有提出一个具体的模型或算法框架,而是从宏观层面提出了一个以数据为中心的研究视角。论文将研究重点放在四个关键的数据相关场景:1) 数据为中心的基准和数据管理;2) 数据归因;3) 知识迁移;4) 推理上下文构建。针对每个场景,论文都提出了具体的研究方向和潜在影响。例如,在数据为中心的基准方面,论文提倡开发一套专门针对LLM数据规模和复杂性的基准测试集。
关键创新:论文的创新之处在于提出了一个以数据为中心的人工智能研究视角,这与当前以模型为中心的研究趋势形成对比。论文强调了数据在LLM开发和推理中的重要性,并指出了未来研究的几个关键方向。这种视角转变有助于研究人员更加重视数据,开发新的数据管理方法和数据分析工具,从而提高大语言模型的性能和可靠性。
关键设计:论文没有涉及具体的参数设置、损失函数或网络结构等技术细节。论文主要关注的是数据在LLM研究中的宏观作用,以及如何通过关注数据来提高LLM的性能。未来的研究可以根据论文提出的研究方向,开发具体的数据管理方法和数据分析工具。
🖼️ 关键图片
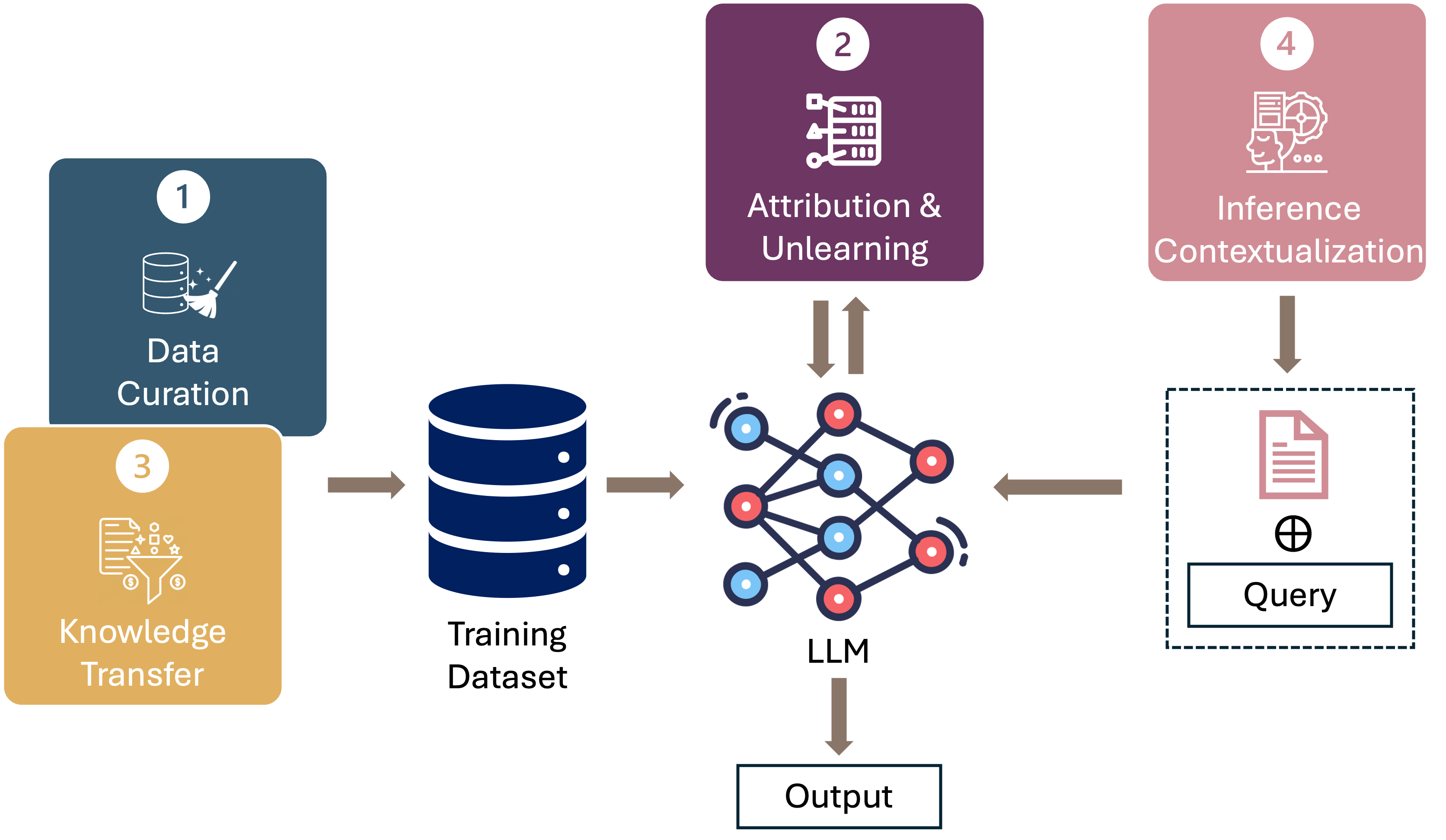
📊 实验亮点
本文是一篇立场性论文,没有提供具体的实验结果。其亮点在于提出了一个以数据为中心的人工智能研究视角,并指出了未来研究的几个关键方向。论文强调了数据在LLM开发和推理中的重要性,并提倡开发新的数据管理方法和数据分析工具。
🎯 应用场景
该研究视角可应用于各种需要大语言模型的领域,如自然语言处理、机器翻译、文本生成、智能客服等。通过提高数据质量和数据管理水平,可以显著提升大语言模型在这些领域的应用效果,并促进人工智能技术的更广泛应用。此外,该研究还有助于提高人工智能研究的透明度和可重复性。
📄 摘要(原文)
This position paper proposes a data-centric viewpoint of AI research, focusing on large language models (LLMs). We start by making the key observation that data is instrumental in the developmental (e.g., pretraining and fine-tuning) and inferential stages (e.g., in-context learning) of LLMs, and yet it receives disproportionally low attention from the research community. We identify four specific scenarios centered around data, covering data-centric benchmarks and data curation, data attribution, knowledge transfer, and inference contextualization. In each scenario, we underscore the importance of data, highlight promising research directions, and articulate the potential impacts on the research community and, where applicable, the society as a whole. For instance, we advocate for a suite of data-centric benchmarks tailored to the scale and complexity of data for LLMs. These benchmarks can be used to develop new data curation methods and document research efforts and results, which can help promote openness and transparency in AI and LLM research.