Revisiting Modularity Maximization for Graph Clustering: A Contrastive Learning Perspective
作者: Yunfei Liu, Jintang Li, Yuehe Chen, Ruofan Wu, Ericbk Wang, Jing Zhou, Sheng Tian, Shuheng Shen, Xing Fu, Changhua Meng, Weiqiang Wang, Liang Chen
分类: cs.LG, cs.AI
发布日期: 2024-06-20
备注: KDD 2024 research track. Code available at https://github.com/EdisonLeeeee/MAGI
💡 一句话要点
提出MAGI框架,利用对比学习视角下的模块度最大化进行图聚类,提升性能和可扩展性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 图聚类 图对比学习 模块度最大化 社区检测 图神经网络
📋 核心要点
- 现有图对比学习方法依赖图增强,易引入语义漂移,且可扩展性受限。
- 论文提出MAGI框架,利用模块度最大化自然定义正负样本,避免语义漂移。
- 实验表明,MAGI在性能和可扩展性上优于现有方法,可处理1亿节点图。
📝 摘要(中文)
图聚类是图挖掘中一项基础且具有挑战性的任务,旨在将图中的节点划分为若干个不相交的簇。近年来,图对比学习(GCL)已成为图聚类领域的主流研究方向,并不断刷新性能记录。然而,基于GCL的方法严重依赖于图增强和对比方案,这可能会引入语义漂移和可扩展性问题。另一种有前景的研究方向是采用模块度最大化,这是一种流行的社区检测有效方法,并将其作为聚类任务的指导原则。尽管最近取得了一些进展,但模块度最大化的潜在机制仍未被充分理解。本文深入研究了模块度最大化在图聚类中的成功之处。我们的分析揭示了模块度最大化与图对比学习之间的紧密联系,其中正例和负例由模块度自然定义。基于此,我们提出了一个名为MAGI的社区感知图聚类框架,该框架利用模块度最大化作为对比预训练任务,以有效地揭示图中社区的潜在信息,同时避免语义漂移问题。在多个图数据集上的大量实验验证了MAGI在可扩展性和聚类性能方面优于最先进的图聚类方法。值得注意的是,MAGI可以轻松扩展到具有1亿个节点的大型图,同时优于强大的基线方法。
🔬 方法详解
问题定义:图聚类旨在将图中的节点划分到不同的簇中。现有的图对比学习方法依赖于图增强技术,这些技术可能会引入噪声,导致语义漂移,并且在处理大规模图时面临可扩展性问题。模块度最大化是一种有效的社区检测方法,但其内在机制尚未被充分理解。
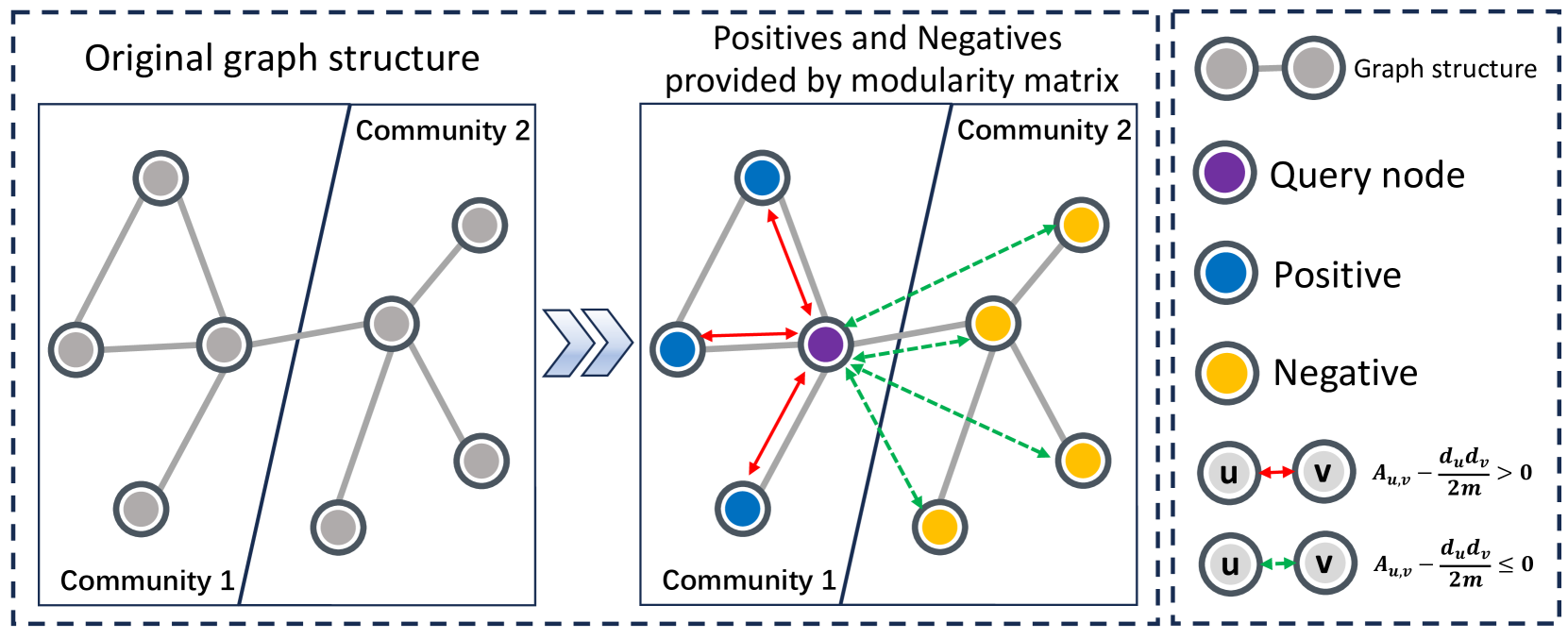
核心思路:论文的核心思路是将模块度最大化与图对比学习联系起来,将模块度作为定义正负样本的依据。模块度高的节点对被认为是正样本,而模块度低的节点对被认为是负样本。通过这种方式,模型可以学习到图的社区结构信息,从而提高聚类性能,同时避免了图增强带来的语义漂移问题。
技术框架:MAGI框架包含以下主要模块:1) 图嵌入模块:使用图神经网络(GNN)学习节点的嵌入表示。2) 模块度计算模块:计算节点之间的模块度值。3) 对比学习模块:基于模块度值构建正负样本对,并使用对比损失函数训练模型。4) 聚类模块:使用学习到的节点嵌入表示进行聚类。
关键创新:论文的关键创新在于将模块度最大化与图对比学习相结合,利用模块度自然地定义正负样本,从而避免了图增强带来的语义漂移问题。此外,该方法具有良好的可扩展性,可以处理大规模图。
关键设计:MAGI框架的关键设计包括:1) 使用GNN学习节点嵌入表示。2) 使用模块度公式计算节点之间的模块度值。3) 使用InfoNCE损失函数进行对比学习。4) 使用K-means算法进行聚类。具体的参数设置需要根据不同的数据集进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,MAGI框架在多个图数据集上取得了优于现有方法的聚类性能。例如,在规模为1亿节点的图上,MAGI框架仍然能够有效地进行聚类,并且优于其他基线方法。这表明MAGI框架具有良好的可扩展性。
🎯 应用场景
该研究成果可应用于社交网络分析、生物信息学、推荐系统等领域。例如,在社交网络中,可以利用MAGI框架识别用户社区,从而进行精准营销和个性化推荐。在生物信息学中,可以用于发现基因之间的相互作用关系,从而帮助研究人员理解生物过程。
📄 摘要(原文)
Graph clustering, a fundamental and challenging task in graph mining, aims to classify nodes in a graph into several disjoint clusters. In recent years, graph contrastive learning (GCL) has emerged as a dominant line of research in graph clustering and advances the new state-of-the-art. However, GCL-based methods heavily rely on graph augmentations and contrastive schemes, which may potentially introduce challenges such as semantic drift and scalability issues. Another promising line of research involves the adoption of modularity maximization, a popular and effective measure for community detection, as the guiding principle for clustering tasks. Despite the recent progress, the underlying mechanism of modularity maximization is still not well understood. In this work, we dig into the hidden success of modularity maximization for graph clustering. Our analysis reveals the strong connections between modularity maximization and graph contrastive learning, where positive and negative examples are naturally defined by modularity. In light of our results, we propose a community-aware graph clustering framework, coined MAGI, which leverages modularity maximization as a contrastive pretext task to effectively uncover the underlying information of communities in graphs, while avoiding the problem of semantic drift. Extensive experiments on multiple graph datasets verify the effectiveness of MAGI in terms of scalability and clustering performance compared to state-of-the-art graph clustering methods. Notably, MAGI easily scales a sufficiently large graph with 100M nodes while outperforming strong baselines.