Bayesian Inverse Reinforcement Learning for Non-Markovian Rewards
作者: Noah Topper, Alvaro Velasquez, George Atia
分类: cs.LG
发布日期: 2024-06-20
💡 一句话要点
提出基于贝叶斯逆强化学习的非马尔可夫奖励函数学习方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 逆强化学习 贝叶斯方法 非马尔可夫奖励 奖励机 专家演示
📋 核心要点
- 现有逆强化学习方法主要针对马尔可夫奖励函数,无法有效处理依赖历史信息的非马尔可夫奖励。
- 论文提出基于贝叶斯框架的逆强化学习方法,直接从专家行为中推断奖励机,无需访问奖励信号。
- 实验结果表明,该方法在学习非马尔可夫奖励函数时表现良好,优于现有二元非马尔可夫奖励学习方法。
📝 摘要(中文)
逆强化学习(IRL)是从专家行为中推断奖励函数的问题。现有的IRL方法大多设计用于学习马尔可夫奖励。然而,奖励函数可能是非马尔可夫的,即依赖于当前状态以外的信息,例如奖励机(RM)。虽然最近有关于推断RM的工作,但它们假设可以访问奖励信号,这在IRL中是不存在的。我们提出了一种贝叶斯IRL(BIRL)框架,用于直接从专家行为中推断RM,这需要对标准框架进行重大修改。我们定义了一个新的奖励空间,调整专家演示以包含历史信息,展示了如何计算奖励后验,并提出了一种新颖的模拟退火修改方法来最大化这个后验。我们证明了我们的方法在根据其推断的奖励进行优化时表现良好,并且与现有的专门学习二元非马尔可夫奖励的方法相比,具有优势。
🔬 方法详解
问题定义:论文旨在解决从专家行为中学习非马尔可夫奖励函数的问题。现有的逆强化学习方法大多假设奖励函数是马尔可夫的,即只依赖于当前状态。然而,在许多实际场景中,奖励可能依赖于历史状态或事件序列,例如奖励机。现有的奖励机学习方法通常需要访问奖励信号,这在逆强化学习问题中是不可行的。
核心思路:论文的核心思路是将贝叶斯方法应用于逆强化学习,并针对非马尔可夫奖励函数(特别是奖励机)进行优化。通过定义合适的奖励空间和后验概率,可以直接从专家行为中推断奖励机,而无需显式地访问奖励信号。这种方法能够更好地捕捉奖励函数与历史信息之间的依赖关系。
技术框架:整体框架包括以下几个主要步骤:1) 定义奖励空间,使用奖励机表示非马尔可夫奖励函数。2) 调整专家演示,将历史信息纳入状态表示中。3) 计算奖励后验概率,基于专家行为和奖励函数的先验知识。4) 使用改进的模拟退火算法最大化后验概率,从而找到最优的奖励机。
关键创新:论文的关键创新在于将贝叶斯逆强化学习框架扩展到非马尔可夫奖励函数,并提出了一种直接从专家行为中学习奖励机的方法。与现有方法相比,该方法不需要访问奖励信号,并且能够更好地捕捉奖励函数与历史信息之间的依赖关系。此外,论文还提出了一种改进的模拟退火算法,用于优化奖励后验概率。
关键设计:论文的关键设计包括:1) 使用奖励机作为非马尔可夫奖励函数的表示形式。2) 定义包含历史信息的状态表示,以便捕捉奖励函数与历史信息之间的依赖关系。3) 使用贝叶斯公式计算奖励后验概率,并结合专家行为和奖励函数的先验知识。4) 提出一种改进的模拟退火算法,通过调整温度下降策略来更好地搜索最优奖励机。
🖼️ 关键图片
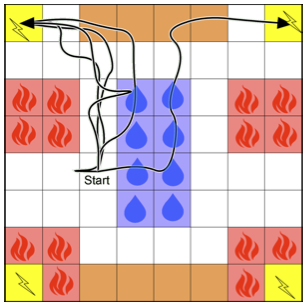

📊 实验亮点
实验结果表明,该方法在学习非马尔可夫奖励函数时表现良好,并且优于现有的专门学习二元非马尔可夫奖励的方法。具体来说,该方法能够更准确地推断奖励机,并使智能体能够根据推断的奖励函数进行有效的优化。性能提升的具体数值未知,但摘要中明确指出该方法优于现有方法。
🎯 应用场景
该研究成果可应用于机器人导航、游戏AI、自动驾驶等领域,在这些领域中,智能体需要根据复杂的、非马尔可夫的奖励函数进行学习和决策。例如,在机器人导航中,奖励可能取决于机器人是否遵循了特定的路径或避免了特定的区域。该方法可以帮助智能体更好地理解人类意图,从而实现更高效、更安全的行为。
📄 摘要(原文)
Inverse reinforcement learning (IRL) is the problem of inferring a reward function from expert behavior. There are several approaches to IRL, but most are designed to learn a Markovian reward. However, a reward function might be non-Markovian, depending on more than just the current state, such as a reward machine (RM). Although there has been recent work on inferring RMs, it assumes access to the reward signal, absent in IRL. We propose a Bayesian IRL (BIRL) framework for inferring RMs directly from expert behavior, requiring significant changes to the standard framework. We define a new reward space, adapt the expert demonstration to include history, show how to compute the reward posterior, and propose a novel modification to simulated annealing to maximize this posterior. We demonstrate that our method performs well when optimizing according to its inferred reward and compares favorably to an existing method that learns exclusively binary non-Markovian rewards.