ME-IGM: Individual-Global-Max in Maximum Entropy Multi-Agent Reinforcement Learning
作者: Wen-Tse Chen, Yuxuan Li, Shiyu Huang, Jiayu Chen, Jeff Schneider
分类: cs.LG
发布日期: 2024-06-20 (更新: 2026-02-03)
备注: Published in the Proceedings of the 25th International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2026)
期刊: Proc. of the 25th International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2026), Paphos, Cyprus, May 25 - 29, 2026, IFAAMAS, 19 pages
DOI: 10.65109/GYYC3346
💡 一句话要点
ME-IGM:最大熵多智能体强化学习中基于个体-全局最大化原则的算法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 信用分配 最大熵 个体-全局最大化 保序变换
📋 核心要点
- 现有最大熵多智能体强化学习方法存在局部策略与全局策略错位的问题,导致违反IGM条件。
- 论文提出一种保序变换,并在此基础上设计了ME-IGM算法,以解决局部策略与全局策略的错位问题。
- 实验结果表明,ME-IGM在SMAC-v2和Overcooked等多个场景中取得了优于现有算法的性能。
📝 摘要(中文)
多智能体信用分配是合作多智能体强化学习(MARL)中的一个基本挑战,其中智能体团队从共享的奖励信号中学习。个体-全局最大化(IGM)条件是多智能体信用分配中广泛使用的原则,它要求由个体Q函数确定的联合动作最大化全局Q值。同时,最大熵原理已被用于增强MARL中的探索。然而,我们发现现有最大熵MARL方法存在一个关键限制:局部策略与最大化全局Q值的联合策略之间存在错位,导致违反IGM条件。为了解决这种错位,我们提出了一种保序变换。在此基础上,我们引入了ME-IGM,一种新颖的最大熵MARL算法,它与任何满足IGM条件的信用分配机制兼容,同时享受最大熵探索的好处。我们在非单调矩阵博弈中对ME-IGM的两个变体:ME-QMIX和ME-QPLEX进行了实证评估,并证明了它们在SMAC-v2和Overcooked的17个场景中的最先进性能。
🔬 方法详解
问题定义:多智能体强化学习中的信用分配问题,即如何将全局奖励分配给各个智能体。现有最大熵MARL方法在鼓励探索的同时,容易导致局部策略与全局最优策略不一致,违反IGM条件,影响学习效果。
核心思路:通过引入保序变换,确保个体Q函数导出的联合动作能够最大化全局Q值,从而对齐局部策略和全局策略,在最大熵探索的同时满足IGM条件。
技术框架:ME-IGM算法建立在现有的满足IGM条件的信用分配机制之上,例如QMIX和QPLEX。它主要包含以下几个阶段:1) 使用个体Q函数选择动作;2) 使用保序变换调整个体Q函数,使其满足IGM条件;3) 执行动作并获得奖励;4) 使用全局奖励更新Q函数。
关键创新:核心创新在于提出的保序变换,该变换能够保证个体Q函数导出的联合动作最大化全局Q值,从而在最大熵探索的同时满足IGM条件,避免了局部策略与全局策略的错位。
关键设计:保序变换的具体形式需要根据具体的信用分配机制进行设计。例如,对于QMIX,可以使用一个单调网络来保证全局Q值是各个个体Q值的单调函数。损失函数的设计需要同时考虑最大熵目标和IGM条件,例如可以使用KL散度来约束策略的熵,并使用一个额外的损失项来惩罚违反IGM条件的行为。
🖼️ 关键图片

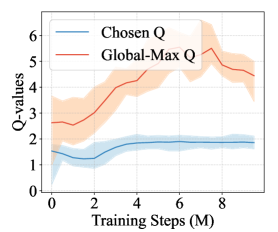

📊 实验亮点
实验结果表明,ME-IGM在SMAC-v2和Overcooked等多个benchmark环境中取得了state-of-the-art的性能。具体来说,ME-QMIX和ME-QPLEX在17个SMAC-v2场景和Overcooked中均表现出显著的性能提升,证明了ME-IGM在解决多智能体信用分配问题上的有效性。
🎯 应用场景
该研究成果可应用于各种需要多智能体协作的场景,例如机器人协同、交通调度、资源分配等。通过提高多智能体强化学习的效率和稳定性,可以更好地解决这些实际问题,提升系统的整体性能和智能化水平。
📄 摘要(原文)
Multi-agent credit assignment is a fundamental challenge for cooperative multi-agent reinforcement learning (MARL), where a team of agents learn from shared reward signals. The Individual-Global-Max (IGM) condition is a widely used principle for multi-agent credit assignment, requiring that the joint action determined by individual Q-functions maximizes the global Q-value. Meanwhile, the principle of maximum entropy has been leveraged to enhance exploration in MARL. However, we identify a critical limitation in existing maximum entropy MARL methods: a misalignment arises between local policies and the joint policy that maximizes the global Q-value, leading to violations of the IGM condition. To address this misalignment, we propose an order-preserving transformation. Building on it, we introduce ME-IGM, a novel maximum entropy MARL algorithm compatible with any credit assignment mechanism that satisfies the IGM condition while enjoying the benefits of maximum entropy exploration. We empirically evaluate two variants of ME-IGM: ME-QMIX and ME-QPLEX, in non-monotonic matrix games, and demonstrate their state-of-the-art performance across 17 scenarios in SMAC-v2 and Overcooked.