A Label is Worth a Thousand Images in Dataset Distillation
作者: Tian Qin, Zhiwei Deng, David Alvarez-Melis
分类: cs.LG, cs.CV
发布日期: 2024-06-15 (更新: 2025-01-19)
备注: NeurIPS 2024
🔗 代码/项目: GITHUB
💡 一句话要点
揭示软标签在数据集蒸馏中的关键作用,强调其结构化信息的重要性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 数据集蒸馏 软标签 数据高效学习 知识蒸馏 模型压缩
📋 核心要点
- 现有数据集蒸馏方法依赖各种合成数据生成技术,缺乏共性,难以理解其有效性的根本原因。
- 该研究强调了软标签在数据集蒸馏中的关键作用,并证明其重要性超越了特定的合成数据生成技术。
- 实验表明,软标签的有效性取决于其包含的结构化信息,并提出了软标签有效性的经验缩放定律。
📝 摘要(中文)
数据质量是机器学习模型性能的关键因素,数据集蒸馏方法通过将训练数据集压缩成更小的、但保持相似下游性能的对应物来利用这一原则。理解数据蒸馏方法如何以及为何有效,对于改进这些方法以及揭示“良好”训练数据的基本特征至关重要。然而,实现这一目标的主要挑战是,依赖复杂但大多不同的方法来生成合成数据的蒸馏方法彼此之间几乎没有共同之处。在这项工作中,我们强调了大多数这些方法中一个很大程度上被忽视的共同方面:软(概率)标签的使用。通过一系列消融实验,我们深入研究了软标签的作用。我们的结果表明,解释最先进蒸馏方法性能的主要因素不是用于生成合成数据的特定技术,而是软标签的使用。此外,我们证明并非所有软标签都是一样的;它们必须包含结构化信息才能有益。我们还提供了经验缩放定律,描述了软标签的有效性与蒸馏数据集中每个类别的图像数量之间的关系,并建立了数据高效学习的经验帕累托前沿。总而言之,我们的发现挑战了数据集蒸馏中的传统观念,强调了软标签在学习中的重要性,并为改进蒸馏方法提出了新的方向。
🔬 方法详解
问题定义:论文旨在理解数据集蒸馏方法有效性的根本原因,并解决现有方法之间缺乏共性的问题。现有数据集蒸馏方法依赖于各种复杂的合成数据生成技术,但这些方法之间差异很大,难以确定哪些因素是提升性能的关键。此外,现有研究对软标签在数据集蒸馏中的作用关注不足。
核心思路:论文的核心思路是,通过消融实验来分析软标签在数据集蒸馏中的作用,并揭示软标签中包含的结构化信息是提升性能的关键因素。论文认为,与其关注复杂的合成数据生成技术,不如深入研究软标签本身,从而更好地理解数据集蒸馏的本质。
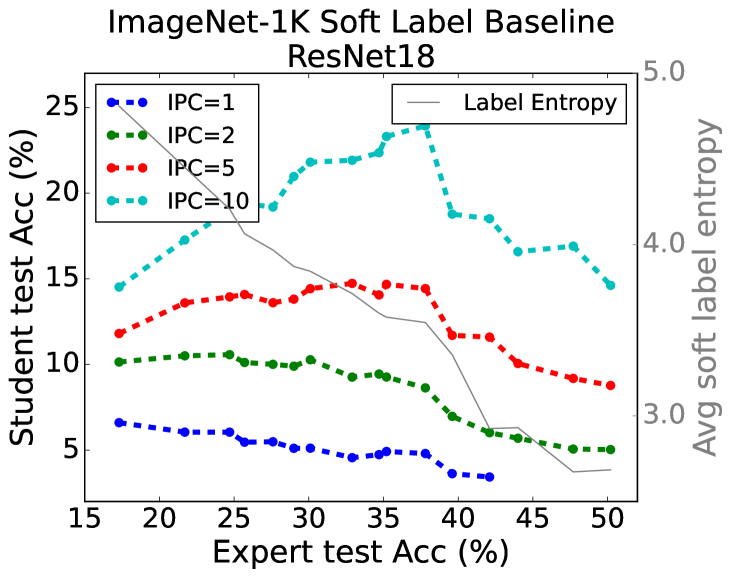
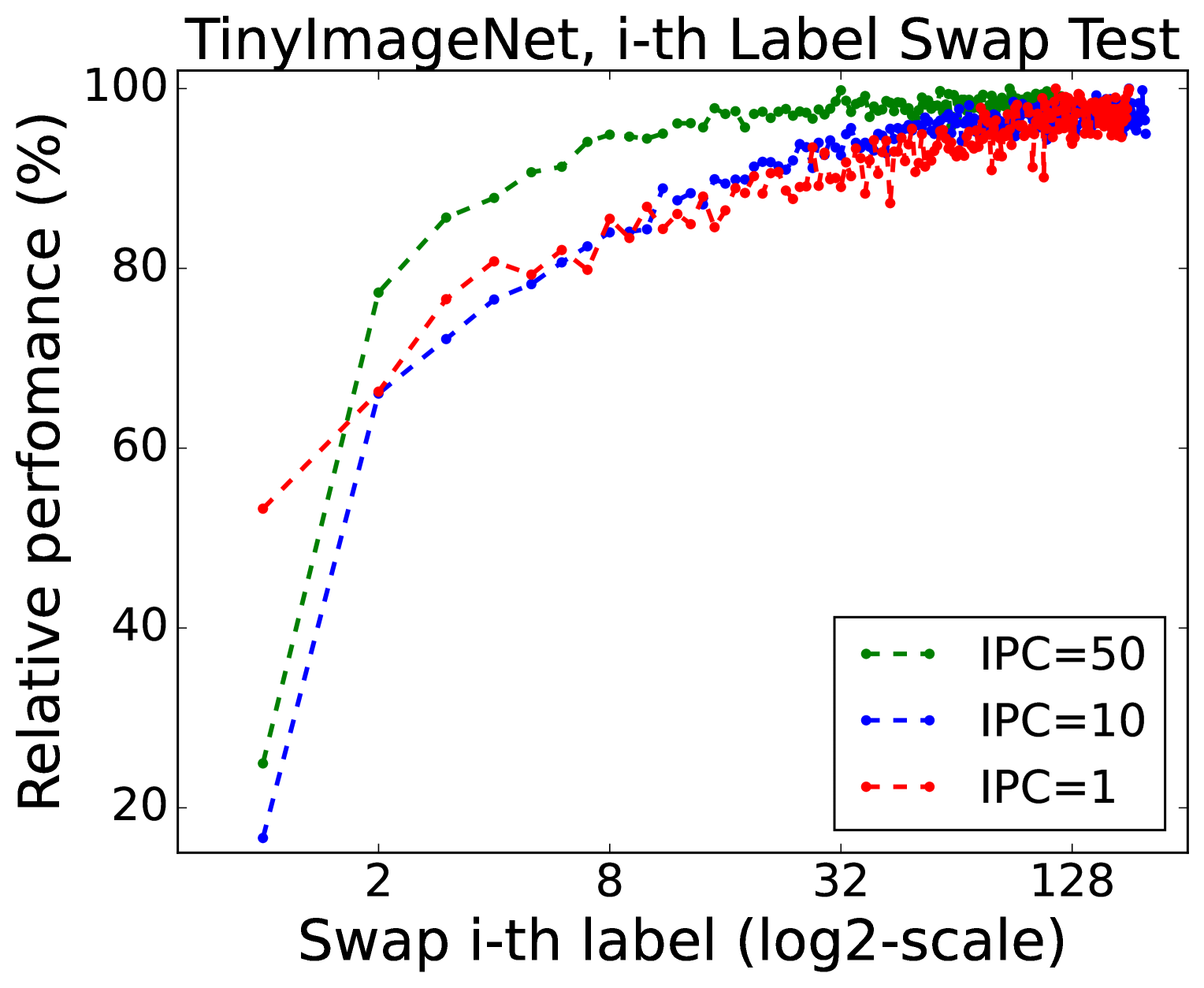
技术框架:论文采用了一系列消融实验来研究软标签的作用。具体来说,论文首先复现了现有的数据集蒸馏方法,然后通过修改这些方法中的软标签生成方式,来观察性能的变化。例如,论文比较了使用真实标签、随机标签和经过特殊设计的软标签的性能。此外,论文还研究了软标签的有效性与蒸馏数据集中每个类别的图像数量之间的关系,并建立了经验帕累托前沿。
关键创新:论文最重要的技术创新点在于,它揭示了软标签在数据集蒸馏中的关键作用,并证明软标签中包含的结构化信息是提升性能的关键因素。这一发现挑战了数据集蒸馏中的传统观念,即认为复杂的合成数据生成技术是提升性能的关键。论文还提出了软标签有效性的经验缩放定律,为数据集蒸馏方法的设计提供了新的指导。
关键设计:论文的关键设计包括:1) 使用多种数据集(如CIFAR-10、SVHN)进行实验,以验证结论的普适性;2) 设计多种软标签生成方式,包括真实标签、随机标签和经过特殊设计的软标签,以比较不同软标签的性能;3) 通过消融实验来分析软标签中不同成分的作用,例如标签平滑、知识蒸馏等;4) 建立软标签有效性的经验缩放定律,以指导数据集蒸馏方法的设计。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用包含结构化信息的软标签可以显著提升数据集蒸馏的性能。例如,在CIFAR-10数据集上,使用精心设计的软标签可以达到与使用真实标签相似的性能,同时大大减少了训练数据量。此外,论文还建立了软标签有效性的经验缩放定律,为数据集蒸馏方法的设计提供了量化指导。
🎯 应用场景
该研究成果可应用于数据高效学习、模型压缩和知识迁移等领域。通过理解软标签在数据集蒸馏中的作用,可以设计更有效的数据集蒸馏方法,从而在资源受限的环境下训练高性能的机器学习模型。此外,该研究还可以帮助我们更好地理解“良好”训练数据的特征,从而指导数据收集和标注工作。
📄 摘要(原文)
Data $\textit{quality}$ is a crucial factor in the performance of machine learning models, a principle that dataset distillation methods exploit by compressing training datasets into much smaller counterparts that maintain similar downstream performance. Understanding how and why data distillation methods work is vital not only for improving these methods but also for revealing fundamental characteristics of "good" training data. However, a major challenge in achieving this goal is the observation that distillation approaches, which rely on sophisticated but mostly disparate methods to generate synthetic data, have little in common with each other. In this work, we highlight a largely overlooked aspect common to most of these methods: the use of soft (probabilistic) labels. Through a series of ablation experiments, we study the role of soft labels in depth. Our results reveal that the main factor explaining the performance of state-of-the-art distillation methods is not the specific techniques used to generate synthetic data but rather the use of soft labels. Furthermore, we demonstrate that not all soft labels are created equal; they must contain $\textit{structured information}$ to be beneficial. We also provide empirical scaling laws that characterize the effectiveness of soft labels as a function of images-per-class in the distilled dataset and establish an empirical Pareto frontier for data-efficient learning. Combined, our findings challenge conventional wisdom in dataset distillation, underscore the importance of soft labels in learning, and suggest new directions for improving distillation methods. Code for all experiments is available at https://github.com/sunnytqin/no-distillation.