Unraveling the Mechanics of Learning-Based Demonstration Selection for In-Context Learning
作者: Hui Liu, Wenya Wang, Hao Sun, Chris Xing Tian, Chenqi Kong, Xin Dong, Haoliang Li
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-06-14 (更新: 2024-10-15)
备注: 17 pages, 7 figures and 9 tables
💡 一句话要点
揭示ICL中基于学习的示例选择机制,提升泛化性和效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 示例选择 大型语言模型 相似性度量 任务泛化
📋 核心要点
- 现有基于学习的示例选择方法机制不透明,存在训练成本高、泛化性差等问题。
- 通过分析相似性度量,发现整合任务无关的文本相似性和结合任务特定标签是关键。
- 提出两种简化的示例选择方法,分别针对任务无关和任务特定的需求,降低计算开销。
📝 摘要(中文)
大型语言模型(LLMs)在少样本示例中展示了令人印象深刻的上下文学习(ICL)能力。最近基于学习的示例选择方法通过选择更有用的示例,已被证明对ICL有益,但其底层机制是不透明的,阻碍了解决诸如高训练成本和跨任务泛化性差等局限性的努力。这些方法通常假设选择过程捕获了示例和目标实例之间的相似性,然而,捕获了哪些类型的相似性以及对执行ICL至关重要仍然未知。为了深入研究这个问题,我们分析了基于学习的示例选择方法的工作机制,并通过经验确定了与相似性度量相关的两个重要因素:1)整合示例输入和测试用例之间不同层次的与任务无关的文本相似性的能力,增强了跨不同任务的泛化能力。2)在测量相似性时,结合特定于任务的标签可以显著提高每个特定任务的性能。我们通过在十个数据集和各种LLM上的广泛定量和定性分析验证了这两个发现。基于我们的发现,我们引入了两种有效但简化的示例选择方法,以满足与任务无关和特定于任务的需求,从而消除了昂贵的LLM推理开销。
🔬 方法详解
问题定义:现有基于学习的上下文学习(ICL)示例选择方法,虽然能提升性能,但其内部机制如同黑盒,难以理解。这导致了两个主要问题:一是训练这些选择器需要大量的计算资源和时间;二是这些选择器在不同任务之间的泛化能力较差,需要针对每个新任务重新训练。因此,核心问题是如何理解这些选择器的工作原理,从而设计出更高效、更通用的示例选择方法。
核心思路:论文的核心思路是通过深入分析现有基于学习的示例选择方法,揭示其选择示例的关键因素。作者假设这些选择器本质上是在衡量示例和目标实例之间的相似性,因此重点研究了哪些类型的相似性对于ICL至关重要。通过实验分析,作者发现任务无关的文本相似性和任务特定的标签信息是两个关键因素。
技术框架:论文没有提出一个全新的技术框架,而是侧重于分析现有方法的机制。其研究流程大致如下:1) 选择现有的基于学习的示例选择方法作为研究对象;2) 设计实验来分析这些方法在选择示例时所关注的相似性特征;3) 通过定量和定性分析,确定任务无关的文本相似性和任务特定的标签信息的重要性;4) 基于分析结果,提出两种简化的示例选择方法。
关键创新:论文的关键创新在于揭示了基于学习的示例选择方法背后的工作机制,明确了任务无关的文本相似性和任务特定的标签信息在示例选择中的重要作用。这打破了以往对这些方法的黑盒认知,为设计更高效、更通用的示例选择方法提供了理论基础。
关键设计:论文提出了两种简化的示例选择方法,分别针对任务无关和任务特定的需求。对于任务无关的情况,方法侧重于计算输入文本之间的多种文本相似度(例如,词法相似度、语义相似度等),并将它们整合起来作为选择示例的依据。对于任务特定的情况,方法则在计算相似度时,会考虑示例的标签信息,例如,选择与目标实例具有相同标签的示例。这些方法避免了使用大型语言模型进行推理,从而大大降低了计算开销。
🖼️ 关键图片
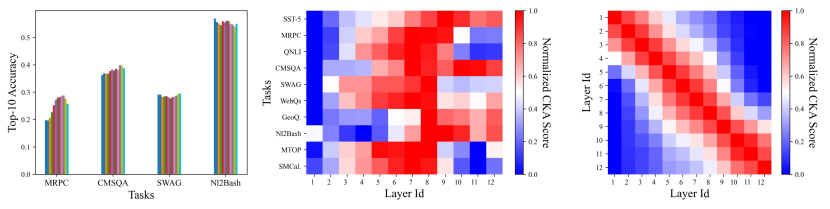
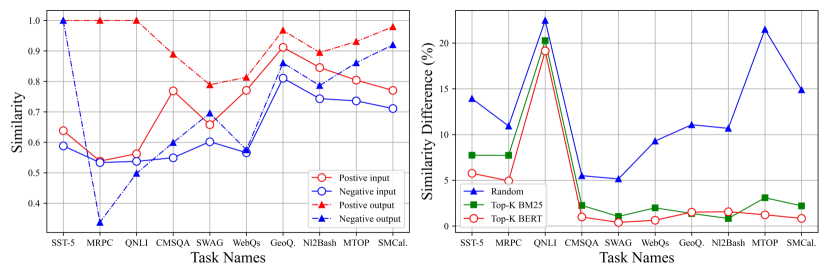

📊 实验亮点
实验结果表明,论文提出的两种简化的示例选择方法在多个数据集上取得了与现有方法相当甚至更好的性能,同时显著降低了计算成本。例如,在某些任务上,新方法在保持性能的同时,可以将推理时间缩短几个数量级。这证明了论文对示例选择机制的理解是准确的,并且基于此提出的方法是有效的。
🎯 应用场景
该研究成果可应用于各种需要上下文学习的自然语言处理任务中,例如文本分类、问答系统、机器翻译等。通过更高效地选择示例,可以提升LLM在这些任务上的性能,并降低计算成本。此外,该研究对于理解和改进其他基于学习的ICL方法也具有指导意义。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated impressive in-context learning (ICL) capabilities from few-shot demonstration exemplars. While recent learning-based demonstration selection methods have proven beneficial to ICL by choosing more useful exemplars, their underlying mechanisms are opaque, hindering efforts to address limitations such as high training costs and poor generalization across tasks. These methods generally assume the selection process captures similarities between the exemplar and the target instance, however, it remains unknown what kinds of similarities are captured and vital to performing ICL. To dive into this question, we analyze the working mechanisms of the learning-based demonstration selection methods and empirically identify two important factors related to similarity measurement: 1) The ability to integrate different levels of task-agnostic text similarities between the input of exemplars and test cases enhances generalization power across different tasks. 2) Incorporating task-specific labels when measuring the similarities significantly improves the performance on each specific task. We validate these two findings through extensive quantitative and qualitative analyses across ten datasets and various LLMs. Based on our findings, we introduce two effective yet simplified exemplar selection methods catering to task-agnostic and task-specific demands, eliminating the costly LLM inference overhead.