Binary Reward Labeling: Bridging Offline Preference and Reward-Based Reinforcement Learning
作者: Yinglun Xu, David Zhu, Rohan Gumaste, Gagandeep Singh
分类: cs.LG
发布日期: 2024-06-14 (更新: 2024-10-23)
💡 一句话要点
提出二元奖励标记法,桥接离线偏好与基于奖励的强化学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 偏好学习 二元奖励标记 奖励重塑 D4RL 强化学习
📋 核心要点
- 现有离线强化学习主要集中于标量奖励反馈,缺乏对偏好反馈的有效处理。
- 提出二元奖励标记法(BRL),将偏好反馈转化为标量奖励,从而应用现有基于奖励的离线强化学习算法。
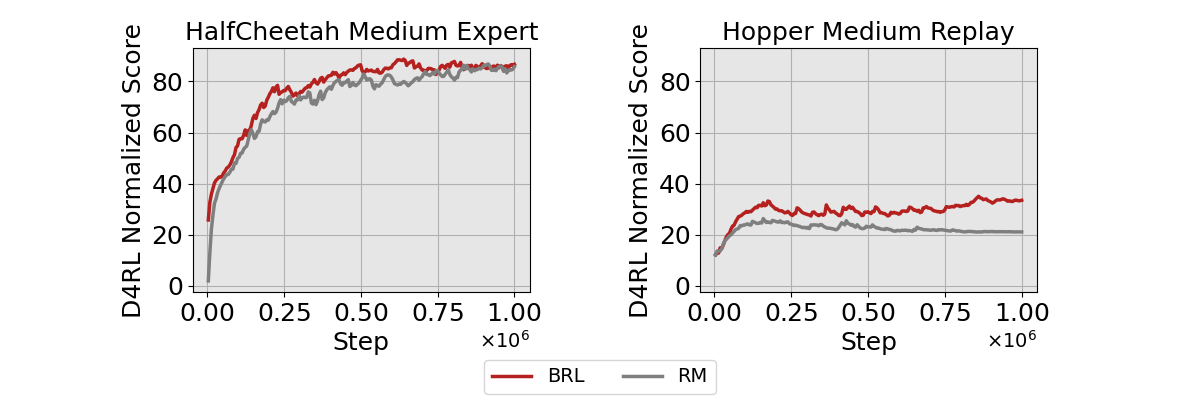
- 实验表明,该框架在D4RL数据集上与实际奖励训练结果相当,且优于现有偏好强化学习基线。
📝 摘要(中文)
离线强化学习已成为最实用的强化学习设置之一。然而,现有关于离线强化学习的大部分工作都集中在具有标量奖励反馈的标准设置上。目前尚不清楚如何将现有的对离线强化学习的丰富理解从基于奖励的设置普遍转移到基于偏好的设置。在这项工作中,我们提出了一个通用框架来弥合这一差距。我们的关键见解是通过二元奖励标记(BRL)将偏好反馈转换为标量奖励,然后任何基于奖励的离线强化学习算法都可以应用于带有奖励标签的数据集。在实际学习场景中,通过二元奖励标记可以最大限度地减少反馈信号转换过程中的信息损失。我们从理论上展示了几种最近的PBRL技术与我们的框架以及特定离线强化学习算法的联系。通过将奖励标记与不同的算法相结合,我们的框架可以产生新的且可能更有效的离线PBRL算法。我们在基于标准D4RL基准的偏好数据集上对我们的框架进行了实证测试。当与各种有效的基于奖励的离线强化学习算法相结合时,在许多情况下,在我们的框架下实现的学习结果与在具有实际奖励的数据集上训练相同算法的结果相当,并且在大多数情况下优于最近的PBRL基线。
🔬 方法详解
问题定义:论文旨在解决离线强化学习中,如何将基于奖励的算法迁移到基于偏好的数据集上的问题。现有的离线强化学习方法主要针对标量奖励,而实际应用中,偏好数据(例如人类反馈)更为常见,直接应用现有方法效果不佳。
核心思路:核心思路是将偏好反馈转化为标量奖励。具体而言,通过二元奖励标记(Binary Reward Labeling, BRL)将偏好信息转换为二元奖励信号(0或1),从而将偏好学习问题转化为标准的奖励学习问题。这样,就可以直接利用现有的、成熟的基于奖励的离线强化学习算法。
技术框架:整体框架包含以下几个步骤:1. 数据收集:收集包含偏好信息的数据集。2. 二元奖励标记:使用BRL方法,根据偏好信息为数据集中的每个样本赋予二元奖励标签。3. 离线强化学习:将带有二元奖励标签的数据集输入到现有的基于奖励的离线强化学习算法中进行训练。4. 策略评估:评估训练得到的策略在目标任务上的性能。
关键创新:关键创新在于提出了二元奖励标记(BRL)方法,它提供了一种通用的、简单有效的方式,将偏好学习问题转化为奖励学习问题。与直接学习偏好模型相比,BRL方法可以充分利用现有的基于奖励的离线强化学习算法,避免了从头开始设计新的算法。
关键设计:BRL的关键设计在于如何有效地将偏好信息转化为二元奖励。具体实现方式可能根据具体的偏好数据形式而有所不同。例如,如果偏好数据是成对的轨迹比较,则可以将更受偏好的轨迹标记为奖励1,另一条标记为奖励0。论文中可能探讨了不同的BRL策略,以及它们对最终学习效果的影响。此外,选择合适的离线强化学习算法也很重要,例如,可以使用保守策略优化(Conservative Policy Optimization, CPO)或批量约束Q学习(Batch-Constrained Q-learning, BCQ)等算法。
🖼️ 关键图片


📊 实验亮点
实验结果表明,将BRL框架与现有的离线强化学习算法相结合,在D4RL数据集上取得了与使用真实奖励训练相当的性能,并且在大多数情况下优于现有的偏好强化学习基线。这表明BRL方法能够有效地保留偏好信息,并将其转化为可用于训练强化学习模型的奖励信号。
🎯 应用场景
该研究成果可广泛应用于需要从人类反馈或偏好数据中学习的强化学习任务中,例如机器人控制、游戏AI、推荐系统等。通过将偏好数据转化为奖励信号,可以更有效地利用人类知识,提升强化学习算法的性能和效率,降低对大量精确奖励信号的依赖。
📄 摘要(原文)
Offline reinforcement learning has become one of the most practical RL settings. However, most existing works on offline RL focus on the standard setting with scalar reward feedback. It remains unknown how to universally transfer the existing rich understanding of offline RL from the reward-based to the preference-based setting. In this work, we propose a general framework to bridge this gap. Our key insight is transforming preference feedback to scalar rewards via binary reward labeling (BRL), and then any reward-based offline RL algorithms can be applied to the dataset with the reward labels. The information loss during the feedback signal transition is minimized with binary reward labeling in the practical learning scenarios. We theoretically show the connection between several recent PBRL techniques and our framework combined with specific offline RL algorithms. By combining reward labeling with different algorithms, our framework can lead to new and potentially more efficient offline PBRL algorithms. We empirically test our framework on preference datasets based on the standard D4RL benchmark. When combined with a variety of efficient reward-based offline RL algorithms, the learning result achieved under our framework is comparable to training the same algorithm on the dataset with actual rewards in many cases and better than the recent PBRL baselines in most cases.