Quantifying Variance in Evaluation Benchmarks
作者: Lovish Madaan, Aaditya K. Singh, Rylan Schaeffer, Andrew Poulton, Sanmi Koyejo, Pontus Stenetorp, Sharan Narang, Dieuwke Hupkes
分类: cs.LG, cs.AI
发布日期: 2024-06-14
💡 一句话要点
量化评估基准中的方差,为LLM评估提供更可靠的性能比较依据
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 评估基准 方差分析 模型评估 性能比较
📋 核心要点
- 当前LLM评估基准缺乏对方差的量化,导致难以判断性能差异的显著性,影响模型选择和训练策略。
- 论文核心在于定义并量化评估基准中的方差,通过分析不同初始化种子和训练过程中的单调性来评估方差。
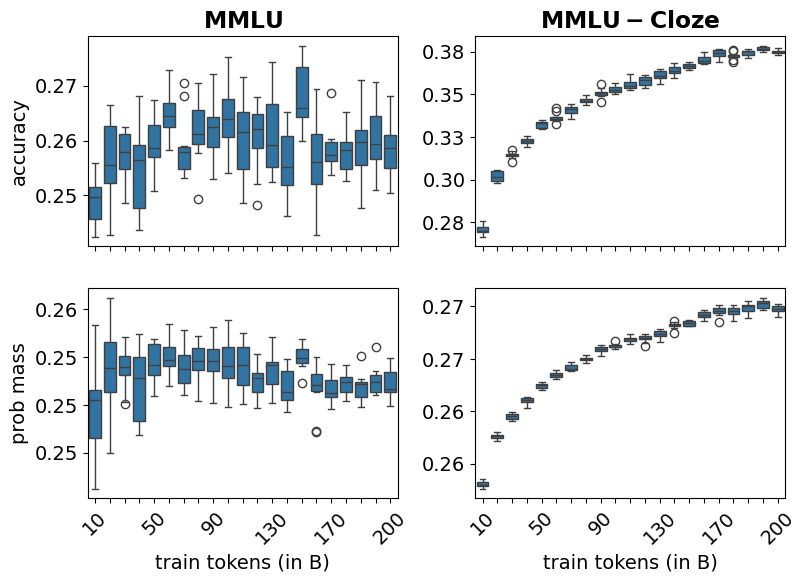
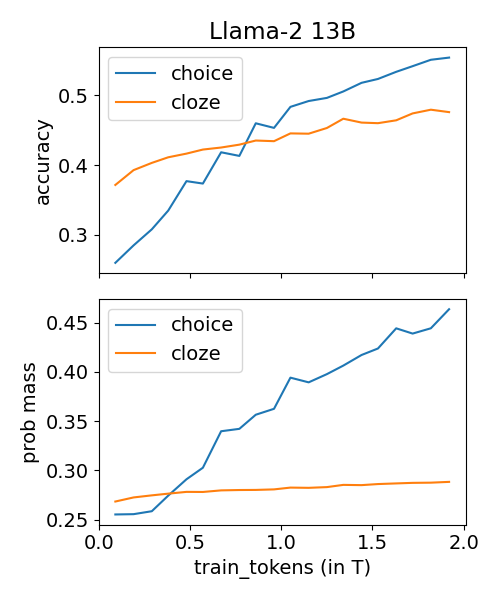
- 实验表明,将选择任务转化为完成任务可以降低小规模模型的方差,并为从业者提供了方差分析和降低的建议。
📝 摘要(中文)
评估基准是衡量大型语言模型(LLM)能力以及推动能力进步的基石。最初设计用于评估预训练模型的性能,现在评估基准也被广泛用于比较不同的训练选择。然而,我们很少量化评估基准中的方差,而方差决定了性能差异是否有意义。本文定义并测量了一系列用于衡量评估基准方差的指标,包括不同初始化种子之间的方差和训练过程中的单调性。通过研究大量模型(包括开源模型和从头开始预训练的模型),我们为各种方差指标提供了经验估计,并为从业者提供了考虑和建议。我们还评估了连续性能指标与离散性能指标的效用和权衡,并探索了更好地理解和减少这种方差的方法。我们发现,简单的更改,例如将选择任务(如MMLU)构建为完成任务,通常可以减少较小规模(约70亿参数)模型的方差,而受人类测试文献启发的更复杂的方法(如项目分析和项目反应理论)难以有意义地减少方差。总的来说,我们的工作提供了对方差的深入了解,提出了减少方差的LM特定技术,并更普遍地鼓励从业者在比较模型时仔细考虑方差。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)评估基准中方差未被充分量化的问题。现有评估方法通常只关注性能的平均值,而忽略了评估结果的方差,这使得研究人员难以判断不同模型或训练策略之间的性能差异是否具有统计意义。这种忽略可能导致错误的结论,例如,误认为一个模型优于另一个模型,而实际上它们的性能差异可能只是由随机因素引起的。
核心思路:论文的核心思路是系统地量化和分析LLM评估基准中的方差。通过研究不同初始化种子、训练过程以及评估任务本身对性能的影响,论文旨在揭示方差的来源,并提出降低方差的方法。这种方法能够帮助研究人员更准确地评估LLM的性能,并做出更明智的模型选择和训练决策。
技术框架:论文的技术框架主要包括以下几个方面:1) 定义方差指标:论文定义了一系列用于衡量评估基准方差的指标,包括种子方差(不同初始化种子之间的性能差异)和单调性(训练过程中性能变化的稳定性)。2) 实验设计:论文设计了大量的实验,包括对开源模型和从头开始预训练的模型进行评估,以收集方差数据。3) 方差分析:论文对收集到的数据进行分析,以确定方差的来源和影响因素。4) 方差降低方法:论文探索了多种降低方差的方法,包括修改评估任务的格式(例如,将选择任务转换为完成任务)和应用人类测试文献中的技术(例如,项目分析和项目反应理论)。
关键创新:论文的关键创新在于系统地量化和分析了LLM评估基准中的方差,并提出了降低方差的方法。与现有方法相比,论文不仅关注性能的平均值,而且关注性能的方差,这使得研究人员能够更准确地评估LLM的性能。此外,论文还探索了多种降低方差的方法,为从业者提供了实用的建议。
关键设计:论文的关键设计包括:1) 对方差指标的定义:论文定义了多种方差指标,以全面衡量评估基准的方差。2) 实验设计:论文设计了大量的实验,以收集方差数据。实验涵盖了不同规模的模型、不同的训练策略和不同的评估任务。3) 方差降低方法:论文探索了多种降低方差的方法,包括修改评估任务的格式和应用人类测试文献中的技术。例如,将MMLU等选择任务转化为完成任务,可以减少小规模模型的方差。
🖼️ 关键图片

📊 实验亮点
研究发现,将MMLU等选择任务转化为完成任务,可以有效降低小规模(约70亿参数)模型的评估方差。此外,论文还提供了多种方差指标的经验估计,并为从业者提供了降低方差的实用建议。实验结果表明,量化和分析评估基准中的方差对于准确评估LLM性能至关重要。
🎯 应用场景
该研究成果可应用于LLM的开发、评估和选择。通过量化评估基准中的方差,可以更准确地比较不同模型和训练策略的性能,从而指导模型开发和优化。此外,该研究还可以帮助研究人员设计更可靠的评估基准,提高LLM研究的可重复性和可信度。未来,该研究有望推动LLM技术的进步,并促进其在各个领域的应用。
📄 摘要(原文)
Evaluation benchmarks are the cornerstone of measuring capabilities of large language models (LLMs), as well as driving progress in said capabilities. Originally designed to make claims about capabilities (or lack thereof) in fully pretrained models, evaluation benchmarks are now also extensively used to decide between various training choices. Despite this widespread usage, we rarely quantify the variance in our evaluation benchmarks, which dictates whether differences in performance are meaningful. Here, we define and measure a range of metrics geared towards measuring variance in evaluation benchmarks, including seed variance across initialisations, and monotonicity during training. By studying a large number of models -- both openly available and pretrained from scratch -- we provide empirical estimates for a variety of variance metrics, with considerations and recommendations for practitioners. We also evaluate the utility and tradeoffs of continuous versus discrete performance measures and explore options for better understanding and reducing this variance. We find that simple changes, such as framing choice tasks (like MMLU) as completion tasks, can often reduce variance for smaller scale ($\sim$7B) models, while more involved methods inspired from human testing literature (such as item analysis and item response theory) struggle to meaningfully reduce variance. Overall, our work provides insights into variance in evaluation benchmarks, suggests LM-specific techniques to reduce variance, and more generally encourages practitioners to carefully factor in variance when comparing models.