LUMA: A Benchmark Dataset for Learning from Uncertain and Multimodal Data
作者: Grigor Bezirganyan, Sana Sellami, Laure Berti-Équille, Sébastien Fournier
分类: cs.LG, cs.AI, cs.CL, cs.CV
发布日期: 2024-06-14 (更新: 2025-08-13)
备注: SIGIR 2025
期刊: Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2025
🔗 代码/项目: GITHUB
💡 一句话要点
LUMA:一个用于学习不确定和多模态数据的基准数据集
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 不确定性量化 基准数据集 深度学习 音频 图像 文本 鲁棒性
📋 核心要点
- 现有的多模态深度学习方法缺乏在不确定性数据下的鲁棒性,难以评估和提升模型的可信度。
- LUMA数据集通过扩展CIFAR数据集,并引入音频和文本模态,同时支持可控地注入不同类型和程度的不确定性。
- 论文提供基线模型和不确定性量化方法,并开源数据集和工具包,促进多模态不确定性学习的研究。
📝 摘要(中文)
本文提出了LUMA,一个独特的多模态数据集,包含来自50个类别的音频、图像和文本数据,专门设计用于学习不确定数据。LUMA通过从三个音频语料库中提取音频样本,并使用Gemma-7B大型语言模型(LLM)生成文本数据,扩展了著名的CIFAR 10/100数据集。LUMA数据集能够以受控方式注入不同类型和程度的不确定性,以实现和定制特定的实验和基准测试。LUMA还提供一个Python包,其中包括生成具有不同数据多样性、每种模态噪声量以及添加分布外样本的多个数据集变体的函数。此外,还提供了一个基线预训练模型以及三种不确定性量化方法:蒙特卡洛Dropout、深度集成和可靠冲突多视图学习。该数据集及其工具旨在促进和支持可信和鲁棒的多模态深度学习方法的发展、评估和基准测试。LUMA数据集将有助于研究社区设计更可信和鲁棒的机器学习方法,用于安全关键型应用。
🔬 方法详解
问题定义:现有的多模态深度学习模型在处理真实世界数据时,面临着数据不确定性和模态多样性的挑战。缺乏一个标准化的、可控的数据集来评估和提升模型在不确定性条件下的性能,阻碍了可信赖多模态学习的发展。现有数据集难以系统性地控制和注入不同类型和程度的不确定性。
核心思路:LUMA数据集的核心思路是构建一个可控的多模态数据集,允许研究人员以受控的方式注入不同类型和程度的不确定性。通过扩展CIFAR数据集,并引入音频和文本模态,LUMA提供了一个更接近真实世界场景的数据集,用于评估和提升模型在不确定性条件下的鲁棒性。
技术框架:LUMA数据集的构建主要包含以下几个阶段:1)图像数据:使用CIFAR-10/100数据集;2)音频数据:从三个音频语料库中提取音频样本,并与图像类别对应;3)文本数据:使用Gemma-7B大型语言模型(LLM)生成与图像类别相关的文本描述;4)不确定性注入:提供Python工具包,允许用户控制每种模态的噪声量、数据多样性以及添加分布外样本。
关键创新:LUMA数据集的关键创新在于其可控的不确定性注入机制。通过提供Python工具包,研究人员可以灵活地控制每种模态的噪声水平、数据多样性,并添加分布外样本,从而模拟真实世界中复杂的数据不确定性。此外,LUMA集成了图像、音频和文本三种模态,为多模态不确定性学习提供了更全面的数据基础。
关键设计:LUMA数据集的关键设计包括:1)音频数据的选择:从多个音频语料库中提取样本,以增加音频数据的多样性;2)文本数据的生成:使用Gemma-7B LLM生成文本描述,以保证文本数据的质量和相关性;3)不确定性注入的控制:提供细粒度的控制参数,允许用户调整每种模态的噪声水平和数据多样性;4)基线模型的提供:提供预训练模型和不确定性量化方法,方便研究人员进行快速实验和比较。
🖼️ 关键图片
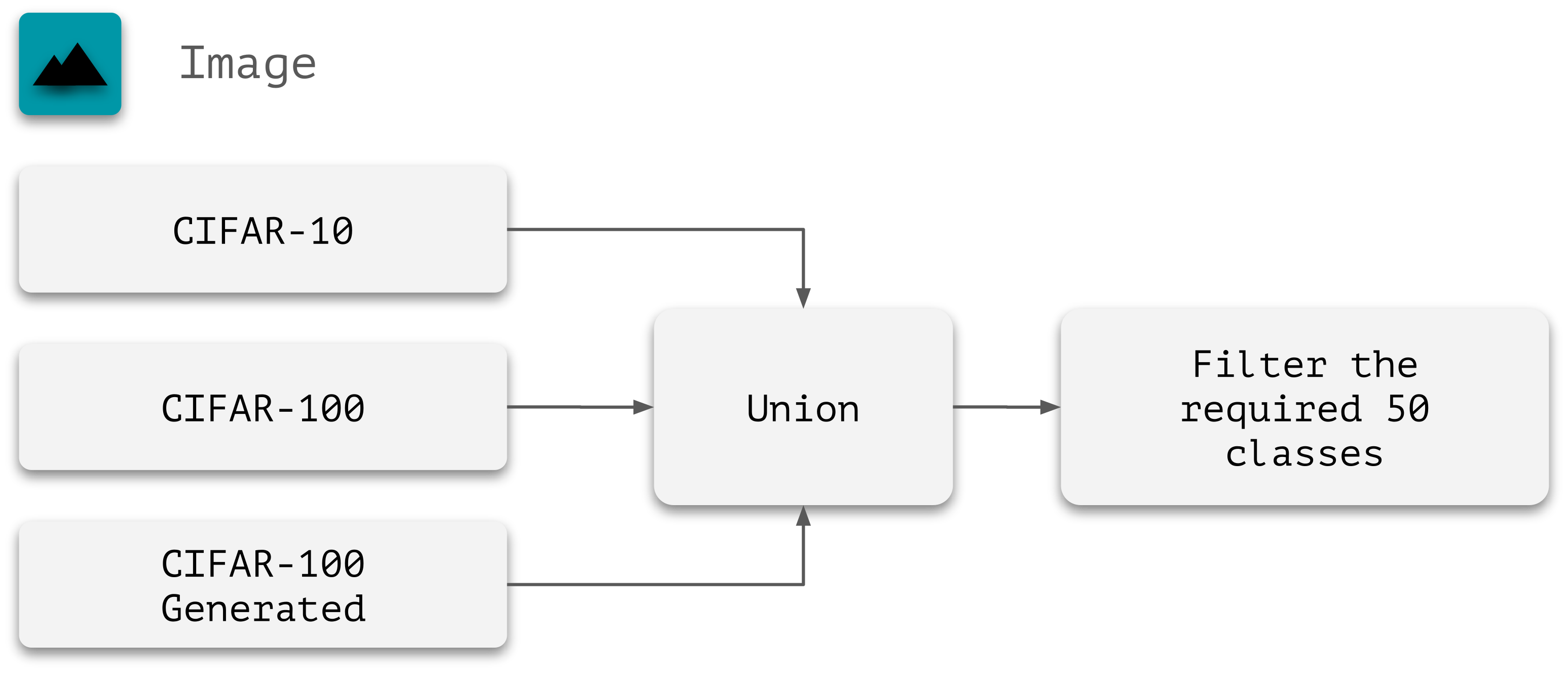
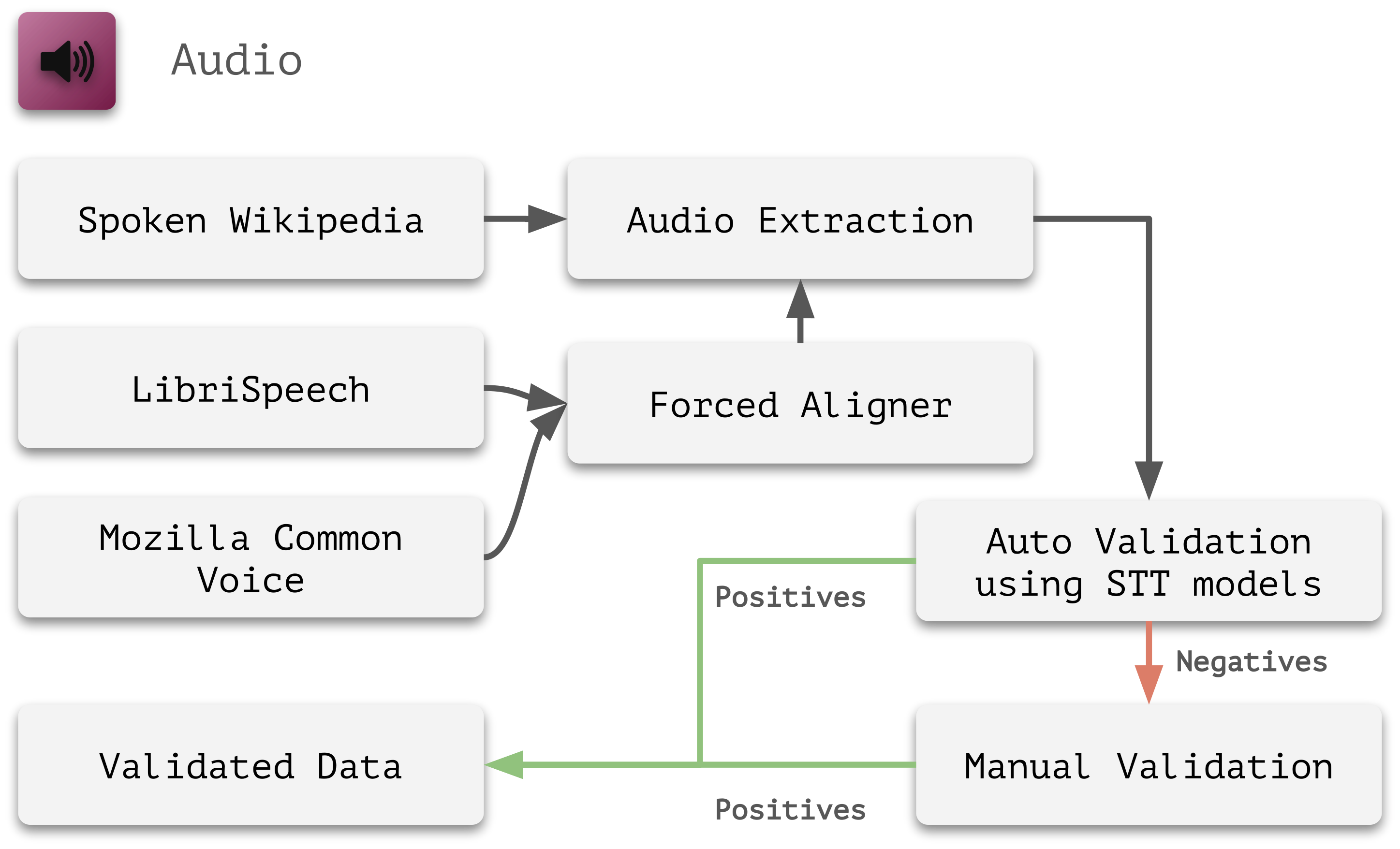
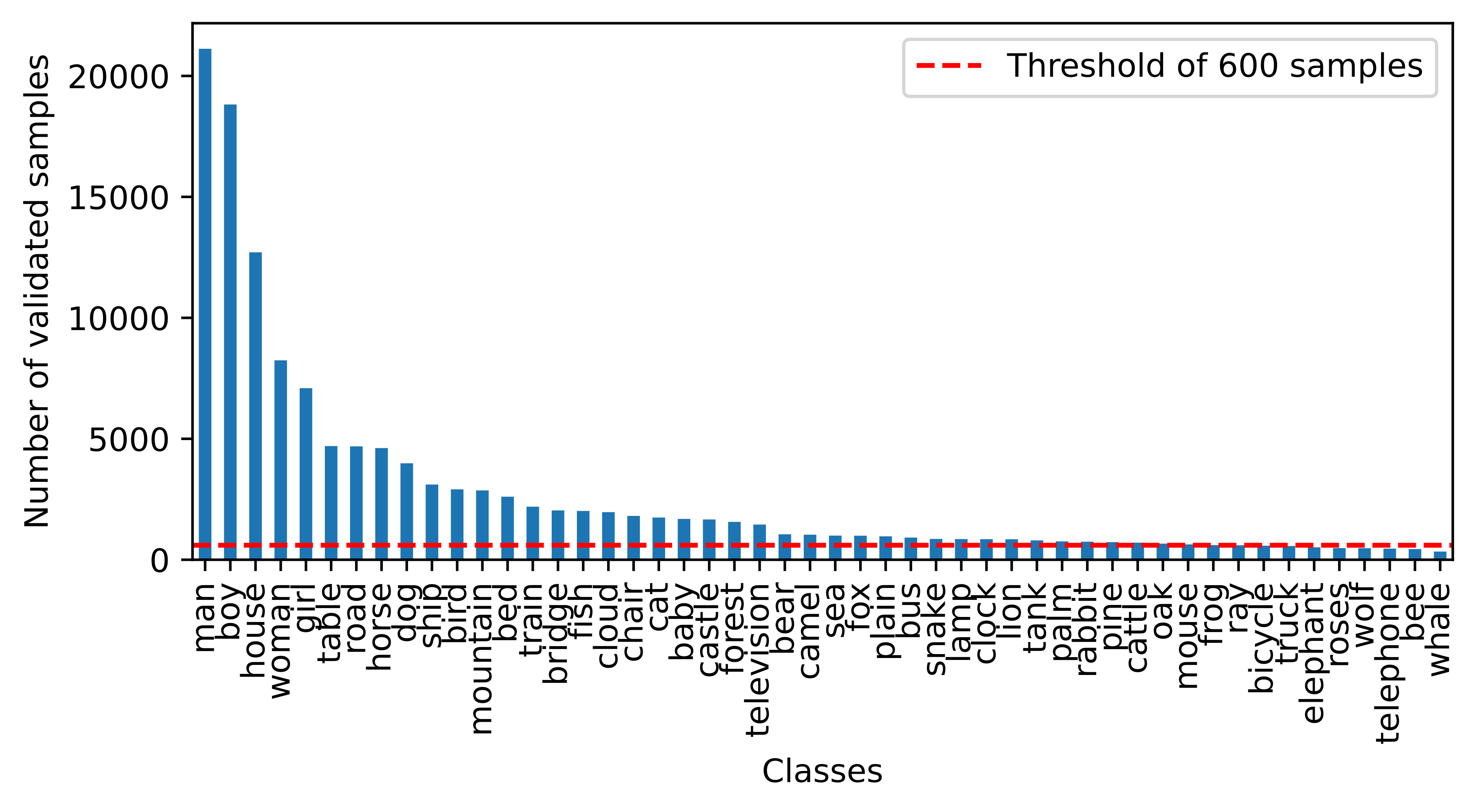
📊 实验亮点
LUMA数据集提供了一个基线预训练模型以及三种不确定性量化方法:蒙特卡洛Dropout、深度集成和可靠冲突多视图学习。这些基线方法为研究人员提供了一个起点,可以快速评估和比较不同模型在LUMA数据集上的性能。通过在LUMA数据集上进行实验,可以深入了解不同模型在处理不确定性数据时的优缺点,并为未来的研究方向提供指导。
🎯 应用场景
LUMA数据集可应用于安全关键型领域,例如自动驾驶、医疗诊断和金融风控。通过在LUMA数据集上训练和评估模型,可以提高模型在不确定性条件下的鲁棒性和可信度,从而降低安全风险。此外,LUMA数据集还可以促进多模态融合技术的发展,提高模型的决策能力和泛化能力。
📄 摘要(原文)
Multimodal Deep Learning enhances decision-making by integrating diverse information sources, such as texts, images, audio, and videos. To develop trustworthy multimodal approaches, it is essential to understand how uncertainty impacts these models. We propose LUMA, a unique multimodal dataset, featuring audio, image, and textual data from 50 classes, specifically designed for learning from uncertain data. It extends the well-known CIFAR 10/100 dataset with audio samples extracted from three audio corpora, and text data generated using the Gemma-7B Large Language Model (LLM). The LUMA dataset enables the controlled injection of varying types and degrees of uncertainty to achieve and tailor specific experiments and benchmarking initiatives. LUMA is also available as a Python package including the functions for generating multiple variants of the dataset with controlling the diversity of the data, the amount of noise for each modality, and adding out-of-distribution samples. A baseline pre-trained model is also provided alongside three uncertainty quantification methods: Monte-Carlo Dropout, Deep Ensemble, and Reliable Conflictive Multi-View Learning. This comprehensive dataset and its tools are intended to promote and support the development, evaluation, and benchmarking of trustworthy and robust multimodal deep learning approaches. We anticipate that the LUMA dataset will help the research community to design more trustworthy and robust machine learning approaches for safety critical applications. The code and instructions for downloading and processing the dataset can be found at: https://github.com/bezirganyan/LUMA/ .