LLM-based Knowledge Pruning for Time Series Data Analytics on Edge-computing Devices
作者: Ruibing Jin, Qing Xu, Min Wu, Yuecong Xu, Dan Li, Xiaoli Li, Zhenghua Chen
分类: cs.LG
发布日期: 2024-06-13
备注: 12 pages, 5 figures
💡 一句话要点
提出基于LLM知识剪枝的时间序列边缘计算分析方法,提升资源受限设备性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列分析 知识剪枝 大型语言模型 边缘计算 知识蒸馏 轻量级模型 物联网设备
📋 核心要点
- 现有时间序列神经网络易过拟合,而基于LLM的方法计算量大,难以在边缘设备上应用。
- 论文提出知识剪枝(KP)方法,从LLM中提取“相关知识”到轻量级模型,降低计算成本。
- 实验表明,KP在边缘设备上回归和分类任务中均取得显著性能提升,验证了其有效性。
📝 摘要(中文)
针对时间序列数据规模和多样性限制导致神经网络过拟合的问题,以及现有基于大型语言模型(LLM)方法计算需求高昂,难以应用于边缘计算和物联网设备等资源受限环境的挑战,本文提出了一种新的时间序列学习范式——知识剪枝(KP)。KP旨在剪除LLM学习到的冗余知识,仅将与特定下游任务相关的“相关知识”提炼到目标模型中,从而显著降低模型大小和计算成本。与现有方法不同,KP在训练和测试过程中无需加载LLM,进一步减轻了计算负担。实验表明,KP能够使轻量级网络有效地学习相关知识,并在回归(平均提升19.7%)和分类(最高提升13.7%)任务中取得显著的性能提升,达到最先进水平。
🔬 方法详解
问题定义:现有时间序列分析模型,特别是基于神经网络的模型,在数据规模和多样性有限的情况下容易过拟合,泛化能力不足。虽然大型语言模型(LLM)在各种领域展现出强大的泛化能力,但直接将LLM应用于时间序列任务需要巨大的计算资源,这使得它们难以部署在资源受限的边缘计算设备上。因此,如何在边缘设备上利用LLM的知识,同时避免高昂的计算成本,是一个亟待解决的问题。
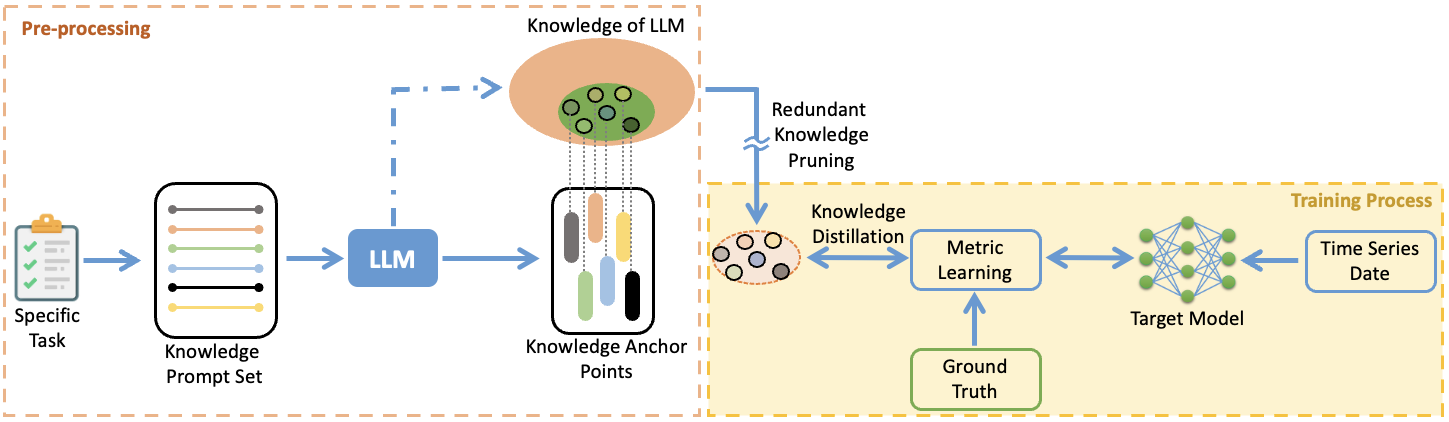
核心思路:论文的核心思路是,对于特定的时间序列分析任务,LLM中蕴含的知识存在大量冗余,只有一部分“相关知识”是有用的。因此,可以通过知识剪枝的方式,从LLM中提取出与任务相关的知识,并将其迁移到轻量级的目标模型中。这样既可以利用LLM的知识,又可以避免加载整个LLM带来的计算负担。
技术框架:KP方法包含以下主要阶段:1) LLM知识提取:利用LLM对时间序列数据进行分析,提取潜在的相关知识。2) 知识选择:根据下游任务的特点,从提取的知识中选择出“相关知识”。这部分可能涉及到一些筛选或排序机制。3) 知识蒸馏:将选择出的“相关知识”蒸馏到轻量级的目标模型中。目标模型可以是任何适合边缘计算设备的轻量级神经网络。4) 模型微调:使用特定任务的数据对目标模型进行微调,以进一步提升性能。
关键创新:KP方法的关键创新在于:1) 知识剪枝范式:提出了一种新的时间序列学习范式,通过剪枝LLM的冗余知识,只保留相关知识,从而降低计算成本。2) 无需加载LLM:与现有基于LLM的方法不同,KP在训练和测试过程中无需加载LLM,进一步减轻了计算负担。这意味着LLM只需要在知识提取阶段使用,后续的训练和推理都可以在边缘设备上独立完成。
关键设计:论文中没有详细描述具体的参数设置、损失函数和网络结构等技术细节。知识选择的具体方法(如何判断哪些知识是“相关知识”)以及知识蒸馏的具体实现方式(例如,使用哪种蒸馏损失函数)是影响KP性能的关键因素,但这些细节在论文中没有明确说明。目标模型的选择也需要根据具体的边缘设备和任务特点进行调整。
🖼️ 关键图片

📊 实验亮点
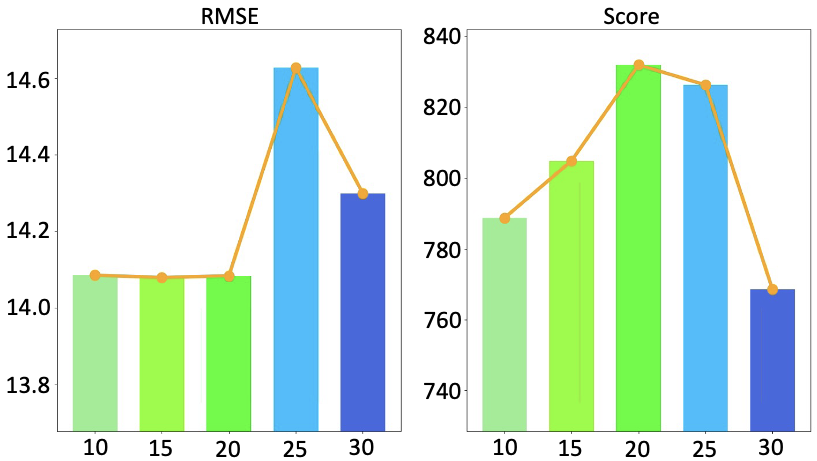
实验结果表明,KP方法在回归任务中平均提升了19.7%的性能,在分类任务中最高提升了13.7%的性能,并在多个不同的环境和基准测试中验证了其泛化能力。这些结果表明,KP能够有效地学习相关知识,并在边缘设备上取得显著的性能提升,达到了最先进的水平。实验结果充分证明了KP方法的有效性和实用性。
🎯 应用场景
该研究成果可广泛应用于边缘计算和物联网设备上的时间序列数据分析,例如智能家居、工业监控、环境监测、健康监测等领域。通过利用LLM的知识,可以在资源受限的设备上实现更准确、更高效的时间序列预测和分类,从而提升设备智能化水平,降低运营成本,并为用户提供更优质的服务。未来,该方法有望推动边缘智能的发展,实现更广泛的应用。
📄 摘要(原文)
Limited by the scale and diversity of time series data, the neural networks trained on time series data often overfit and show unsatisfacotry performances. In comparison, large language models (LLMs) recently exhibit impressive generalization in diverse fields. Although massive LLM based approaches are proposed for time series tasks, these methods require to load the whole LLM in both training and reference. This high computational demands limit practical applications in resource-constrained settings, like edge-computing and IoT devices. To address this issue, we propose Knowledge Pruning (KP), a novel paradigm for time series learning in this paper. For a specific downstream task, we argue that the world knowledge learned by LLMs is much redundant and only the related knowledge termed as "pertinent knowledge" is useful. Unlike other methods, our KP targets to prune the redundant knowledge and only distill the pertinent knowledge into the target model. This reduces model size and computational costs significantly. Additionally, different from existing LLM based approaches, our KP does not require to load the LLM in the process of training and testing, further easing computational burdens. With our proposed KP, a lightweight network can effectively learn the pertinent knowledge, achieving satisfactory performances with a low computation cost. To verify the effectiveness of our KP, two fundamental tasks on edge-computing devices are investigated in our experiments, where eight diverse environments or benchmarks with different networks are used to verify the generalization of our KP. Through experiments, our KP demonstrates effective learning of pertinent knowledge, achieving notable performance improvements in regression (19.7% on average) and classification (up to 13.7%) tasks, showcasing state-of-the-art results.