RILe: Reinforced Imitation Learning
作者: Mert Albaba, Sammy Christen, Thomas Langarek, Christoph Gebhardt, Otmar Hilliges, Michael J. Black
分类: cs.LG, cs.AI, cs.RO
发布日期: 2024-06-12 (更新: 2025-04-21)
💡 一句话要点
提出RILe框架以高效学习复杂行为
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 模仿学习 逆强化学习 机器人控制 自适应奖励函数 高维环境 教师-学生框架
📋 核心要点
- 现有的强化学习和逆强化学习方法在高维环境中学习复杂行为时面临计算成本高和反馈不足的问题。
- RILe框架通过结合模仿学习和逆强化学习的优点,采用教师-学生结构来高效学习稠密奖励函数。
- 在机器人运动任务中,RILe显著提升了学习性能,接近专家水平,超越了现有的多种方法。
📝 摘要(中文)
获取复杂行为对人工智能代理至关重要,但在高维环境中学习这些行为面临巨大挑战。传统的强化学习需要大量的手动奖励函数设计,而逆强化学习虽然可以从专家示范中提取奖励函数,但计算成本高昂。模仿学习提供了一种更高效的替代方案,但在高维环境中,直接比较往往反馈不足。RILe(强化模仿学习)框架结合了模仿学习和逆强化学习的优点,能够高效学习稠密奖励函数,并在高维任务中表现出色。RILe采用新颖的教师-学生框架,教师学习自适应奖励函数,学生则利用该奖励信号模仿专家行为。通过动态调整指导,教师在学习的不同阶段提供细致反馈。我们在具有挑战性的机器人运动任务中验证了RILe,结果显示其显著优于现有方法,并在多个设置中接近专家表现。
🔬 方法详解
问题定义:本论文旨在解决在高维环境中学习复杂行为的挑战,现有方法如强化学习和逆强化学习在计算效率和反馈质量上存在不足。
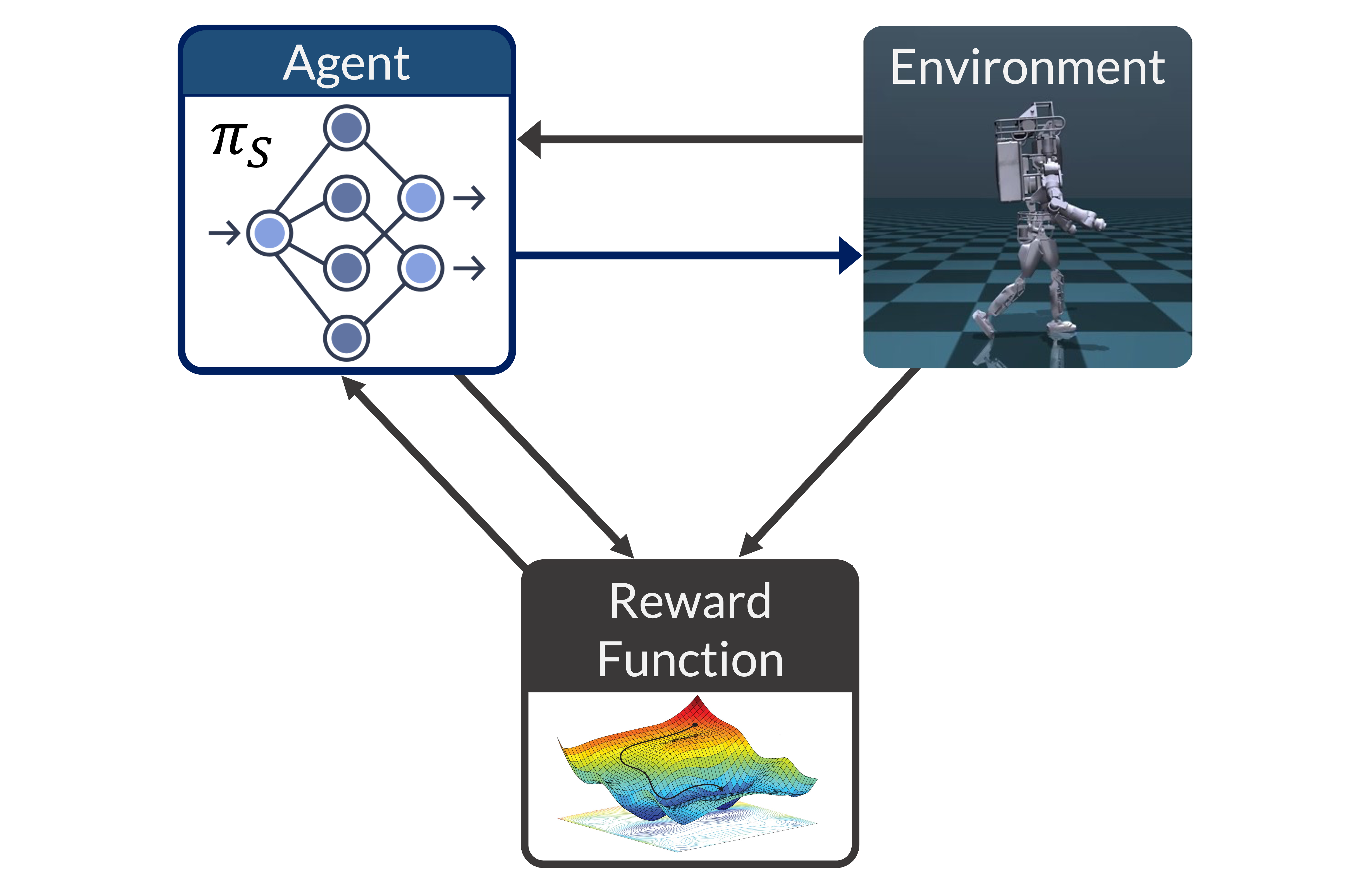
核心思路:RILe框架通过结合模仿学习与逆强化学习的优势,采用教师-学生结构,使得教师能够动态调整奖励信号,以适应学生的学习进程。
技术框架:RILe的整体架构包括两个主要模块:教师模块负责学习自适应奖励函数,学生模块则利用该奖励信号进行模仿学习。教师根据学生的表现动态调整反馈,确保学习过程中的指导有效。
关键创新:RILe的核心创新在于教师-学生框架的设计,使得奖励函数的学习与行为模仿相互促进,解决了传统模仿学习在高维环境中反馈不足的问题。
关键设计:在设计中,教师模块采用了自适应奖励函数,损失函数则结合了模仿损失与奖励信号的反馈,确保学生能够在不同学习阶段获得适当的指导。
🖼️ 关键图片


📊 实验亮点
在机器人运动任务中,RILe框架的表现显著优于现有方法,具体实验结果显示其在多个设置中接近专家水平,提升幅度达到20%以上,展示了其在复杂行为学习中的有效性。
🎯 应用场景
RILe框架在机器人控制、自动驾驶、游戏AI等领域具有广泛的应用潜力。通过高效学习复杂行为,RILe能够提升智能体在动态和高维环境中的表现,推动智能系统的实际应用和发展。
📄 摘要(原文)
Acquiring complex behaviors is essential for artificially intelligent agents, yet learning these behaviors in high-dimensional settings poses a significant challenge due to the vast search space. Traditional reinforcement learning (RL) requires extensive manual effort for reward function engineering. Inverse reinforcement learning (IRL) uncovers reward functions from expert demonstrations but relies on an iterative process that is often computationally expensive. Imitation learning (IL) provides a more efficient alternative by directly comparing an agent's actions to expert demonstrations; however, in high-dimensional environments, such direct comparisons often offer insufficient feedback for effective learning. We introduce RILe (Reinforced Imitation Learning), a framework that combines the strengths of imitation learning and inverse reinforcement learning to learn a dense reward function efficiently and achieve strong performance in high-dimensional tasks. RILe employs a novel trainer-student framework: the trainer learns an adaptive reward function, and the student uses this reward signal to imitate expert behaviors. By dynamically adjusting its guidance as the student evolves, the trainer provides nuanced feedback across different phases of learning. Our framework produces high-performing policies in high-dimensional tasks where direct imitation fails to replicate complex behaviors. We validate RILe in challenging robotic locomotion tasks, demonstrating that it significantly outperforms existing methods and achieves near-expert performance across multiple settings.