A Critical Look At Tokenwise Reward-Guided Text Generation
作者: Ahmad Rashid, Ruotian Wu, Julia Grosse, Agustinus Kristiadi, Pascal Poupart
分类: cs.LG, cs.CL
发布日期: 2024-06-12 (更新: 2025-09-26)
备注: Work accepted at COLM 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于Bradley-Terry奖励模型的token级奖励引导文本生成方法,无需大规模LLM微调。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本生成 奖励模型 强化学习 Bradley-Terry模型 token级奖励 自回归采样 语言模型微调
📋 核心要点
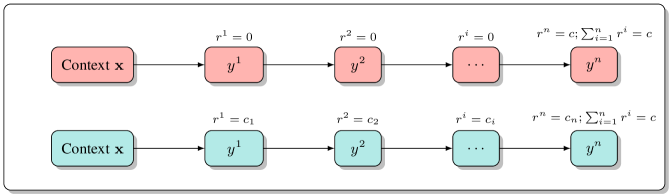
- 现有token级奖励引导文本生成方法缺乏理论基础,且直接使用完整序列训练的奖励模型评估部分序列存在不兼容性。
- 提出训练基于部分序列的Bradley-Terry奖励模型,并从中自回归采样token,从而引导文本生成。
- 实验表明,该方法优于现有RGTG方法,且性能接近强大的离线基线,同时避免了大规模LLM微调。
📝 摘要(中文)
大型语言模型(LLM)可以通过与人类偏好对齐进行改进,即通过人类反馈的强化学习(RLHF)。然而,微调LLM的成本对于许多用户来说是过高的。为了绕过LLM微调,最近提出了预测时token级奖励引导文本生成(RGTG)方法。这些方法使用在完整序列上训练的奖励模型来评估解码期间的部分序列,以引导生成朝着具有高奖励的序列发展。然而,这些方法到目前为止仅具有启发式动机,并且分析不足。在这项工作中,我们表明在完整序列上训练的奖励模型与评估部分序列不兼容。为了缓解这个问题,我们建议在部分序列上显式地训练一个Bradley-Terry奖励模型,并在解码期间从隐含的token级策略中自回归地采样。我们研究了该奖励模型和由此产生的策略的属性:我们表明该策略与两个不同的RLHF策略的比率成正比。我们的简单方法优于先前的RGTG方法,并且表现与强大的离线基线相似,而无需大规模LLM微调。
🔬 方法详解
问题定义:论文旨在解决在不进行大规模LLM微调的情况下,如何有效地利用奖励模型引导文本生成的问题。现有的token级奖励引导文本生成(RGTG)方法存在两个主要痛点:一是缺乏理论支撑,通常是启发式的;二是直接使用在完整序列上训练的奖励模型来评估部分序列,这可能导致不一致的奖励信号,因为奖励模型没有针对部分序列进行优化。
核心思路:论文的核心思路是训练一个专门针对部分序列的奖励模型,具体而言,采用Bradley-Terry模型。该模型直接对部分序列的相对偏好进行建模,从而避免了完整序列奖励模型与部分序列评估之间的不兼容性。通过学习部分序列的奖励,可以更准确地引导文本生成过程。
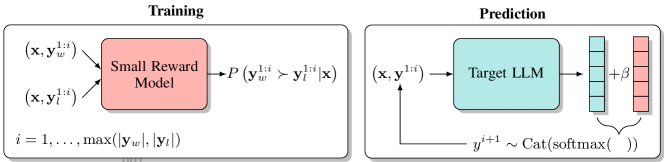
技术框架:整体框架包括以下几个主要步骤: 1. 数据收集:收集包含完整序列和部分序列的数据集。 2. Bradley-Terry奖励模型训练:使用收集到的数据训练Bradley-Terry奖励模型,该模型学习部分序列之间的相对偏好。 3. 策略推导:从训练好的Bradley-Terry奖励模型中推导出token级的策略,该策略指导每个token的选择。 4. 自回归采样:在解码过程中,根据推导出的token级策略进行自回归采样,生成文本。
关键创新:论文的关键创新在于以下几点: 1. 部分序列奖励建模:显式地对部分序列进行奖励建模,解决了完整序列奖励模型与部分序列评估之间的不兼容性问题。 2. Bradley-Terry模型应用:将Bradley-Terry模型应用于token级奖励引导文本生成,提供了一种新的奖励建模方法。 3. 策略推导与分析:推导并分析了从Bradley-Terry模型中得到的token级策略,证明其与两个不同的RLHF策略的比率成正比。
关键设计: 1. Bradley-Terry模型:使用Bradley-Terry模型对部分序列的相对偏好进行建模,模型参数通过最大似然估计进行训练。 2. 损失函数:使用交叉熵损失函数来训练Bradley-Terry模型,目标是最大化观察到的部分序列偏好的似然。 3. 自回归采样:在解码过程中,使用softmax函数将Bradley-Terry模型的输出转换为token级的概率分布,并从中进行采样。
🖼️ 关键图片
📊 实验亮点
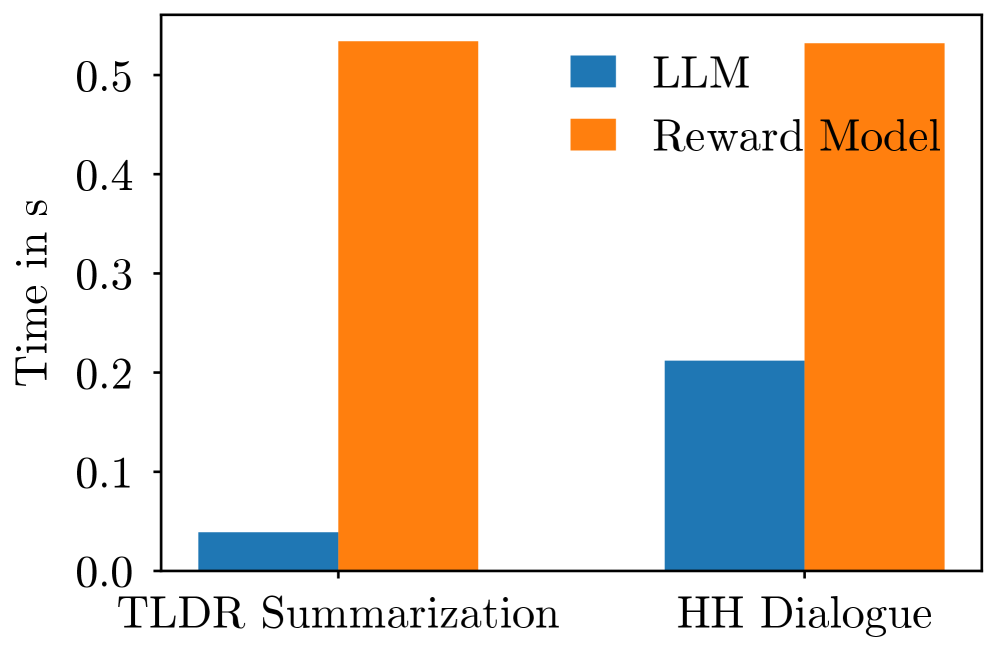
实验结果表明,该方法在文本生成任务上优于现有的token级奖励引导文本生成方法。具体来说,该方法在多个指标上取得了显著提升,并且性能接近强大的离线基线,同时避免了大规模LLM微调。代码已开源。
🎯 应用场景
该研究成果可应用于各种需要高质量文本生成的场景,例如对话系统、文本摘要、机器翻译等。通过奖励模型引导文本生成,可以提高生成文本的质量、相关性和符合人类偏好的程度。该方法尤其适用于资源受限的场景,因为它可以避免大规模LLM微调,降低计算成本。
📄 摘要(原文)
Large language models (LLMs) can be improved by aligning with human preferences through fine-tuning -- the so-called reinforcement learning from human feedback (RLHF). However, the cost of fine-tuning an LLM is prohibitive for many users. Due to their ability to bypass LLM fine-tuning, prediction-time tokenwise reward-guided text generation (RGTG) methods have recently been proposed. They use a reward model trained on full sequences to score partial sequences during decoding in a bid to steer the generation towards sequences with high rewards. However, these methods have so far been only heuristically motivated and poorly analyzed. In this work, we show that reward models trained on full sequences are not compatible with scoring partial sequences. To alleviate this, we propose to train a Bradley-Terry reward model on partial sequences explicitly, and autoregressively sample from the implied tokenwise policy during decoding. We study the properties of this reward model and the resulting policy: we show that this policy is proportional to the ratio of two distinct RLHF policies. Our simple approach outperforms previous RGTG methods and performs similarly to strong offline baselines without large-scale LLM fine-tuning. Code for our work is available at https://github.com/ahmadrash/PARGS