OPTune: Efficient Online Preference Tuning
作者: Lichang Chen, Jiuhai Chen, Chenxi Liu, John Kirchenbauer, Davit Soselia, Chen Zhu, Tom Goldstein, Tianyi Zhou, Heng Huang
分类: cs.LG, cs.CL
发布日期: 2024-06-11
备注: 16 pages, 7 figures
💡 一句话要点
OPTune:一种高效的在线偏好调整方法,通过动态采样提升训练效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 在线偏好调整 强化学习与人类反馈 大型语言模型 数据探索 动态采样
📋 核心要点
- 在线RLHF对齐LLM面临数据生成成本高、难以并行化以及数据质量不稳定的挑战。
- OPTune通过动态采样信息量大的响应,并根据效用对响应进行加权,实现高效的在线偏好调整。
- 实验表明,OPTune在保持指令遵循优势的同时,将LLM的训练速度提高了1.27-1.56倍。
📝 摘要(中文)
本文提出了一种更高效的在线偏好调整(OPTune)数据探索策略,用于解决大型语言模型(LLMs)与人类偏好对齐的问题。与离线强化学习与人类反馈(RLHF)方法(如直接偏好优化DPO)相比,在线方法通常能实现更好的对齐效果。然而,在线对齐需要即时生成新的训练数据,这既昂贵又难以并行化,并且数据质量和效用参差不齐。OPTune不依赖于人工标注或预收集的教师响应,而是动态采样信息量大的响应,用于在线偏好对齐。在数据生成过程中,OPTune仅选择那些(重新)生成的响应比现有响应更有可能提供信息量更大、质量更高的训练信号的提示。在训练目标中,OPTune根据每个生成的响应(对)在改善对齐方面的效用对其进行重新加权,从而使学习能够集中在最有帮助的样本上。评估结果表明,OPTune训练的LLM在保持标准偏好调整所提供的指令遵循优势的同时,由于高效的数据探索策略,训练速度提高了1.27-1.56倍。
🔬 方法详解
问题定义:论文旨在解决在线强化学习与人类反馈(RLHF)中,大型语言模型(LLMs)与人类偏好对齐时,数据生成效率低下的问题。现有在线RLHF方法需要实时生成训练数据,这导致了高昂的计算成本、难以并行化以及生成数据质量和效用不一致等问题。这些问题限制了在线RLHF的实际应用。
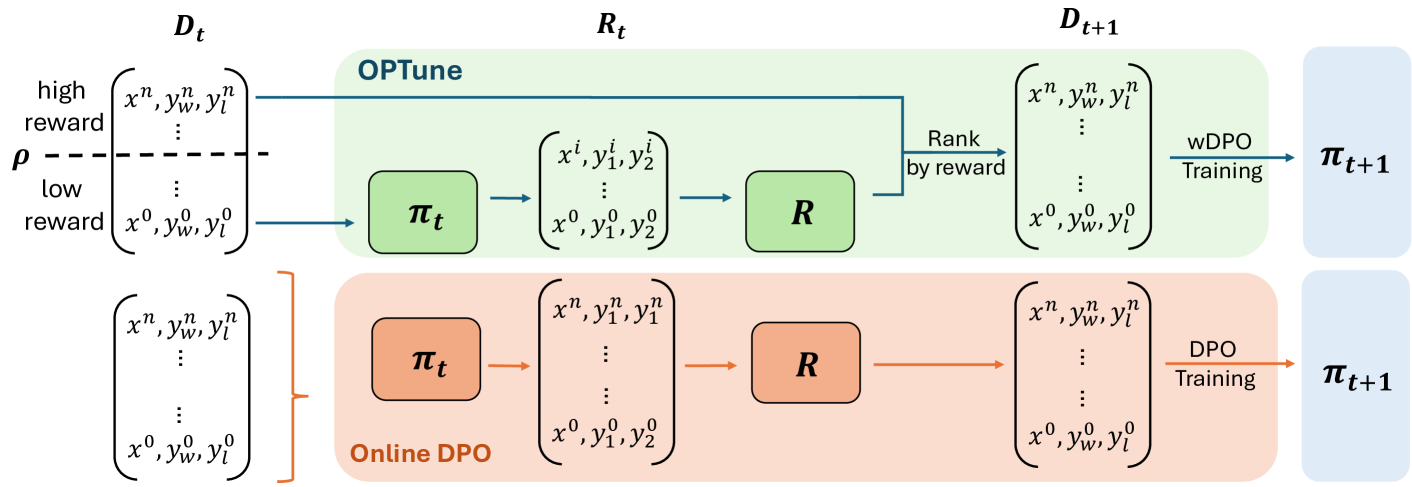
核心思路:OPTune的核心思路是通过一种更智能的数据探索策略,动态地选择那些能够提供更多信息和更高质量训练信号的提示进行响应生成。它避免了盲目地生成所有可能的响应,而是专注于那些能够显著改善模型对齐效果的样本。此外,OPTune还引入了一种重加权机制,根据每个生成响应的效用调整其在训练目标中的权重,从而使模型能够更加关注有价值的样本。
技术框架:OPTune的整体框架包括以下几个主要阶段:1) 提示选择:根据一定的策略,从候选提示集合中选择一部分提示用于生成响应。2) 响应生成:对于选定的提示,模型生成相应的响应。3) 效用评估:评估生成的响应对于改善模型对齐的潜在效用。4) 样本加权:根据效用评估结果,对生成的响应进行加权。5) 模型训练:使用加权后的响应数据训练LLM。
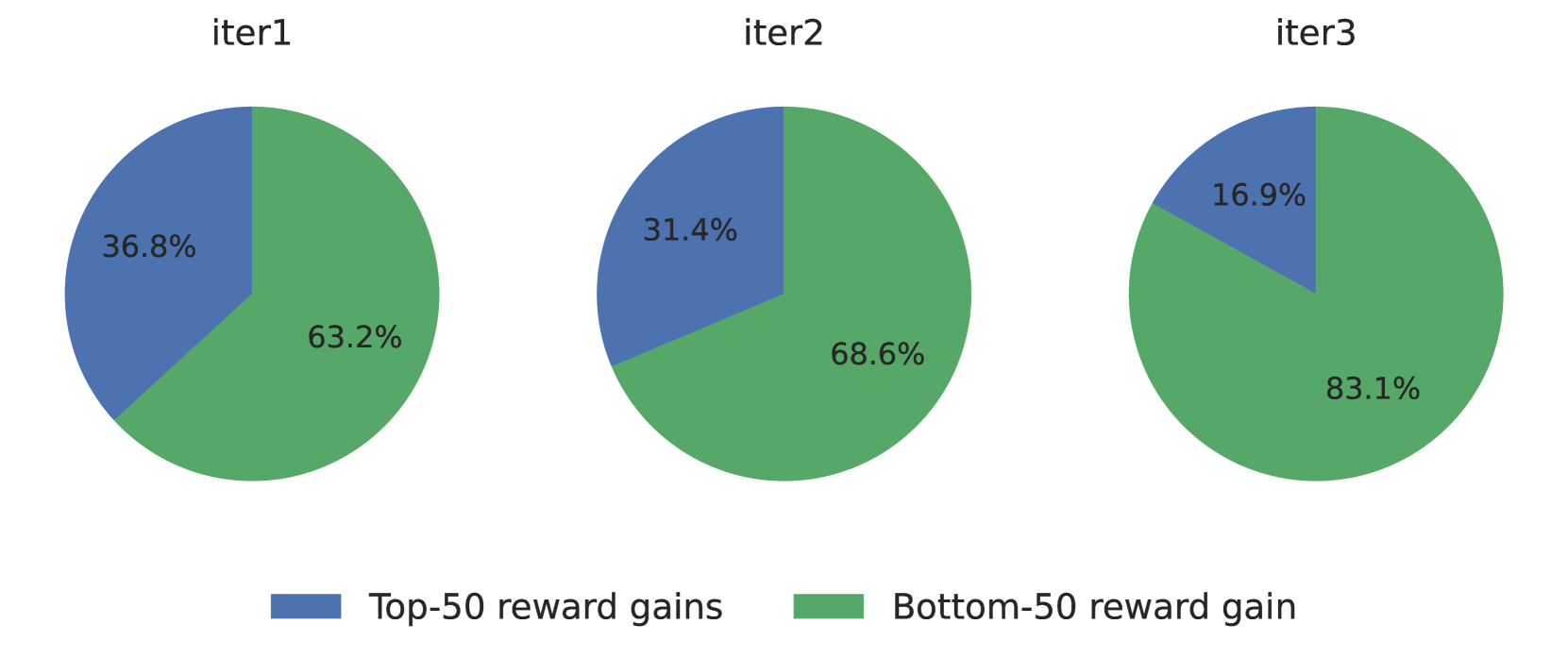
关键创新:OPTune最重要的技术创新在于其动态采样和效用加权机制。传统的在线RLHF方法通常采用均匀采样或随机采样的方式生成训练数据,而OPTune则能够根据响应的潜在效用进行选择性采样,从而提高了数据利用率。此外,OPTune的效用加权机制能够使模型更加关注那些能够显著改善对齐效果的样本,从而加速了训练过程。
关键设计:OPTune的关键设计包括:1) 提示选择策略:论文可能采用了一种基于不确定性或信息增益的提示选择策略,以选择那些能够提供最多信息的提示。2) 效用评估函数:论文定义了一个效用函数,用于评估生成的响应对于改善模型对齐的潜在价值。这个函数可能考虑了响应的质量、多样性和与人类偏好的一致性等因素。3) 损失函数:论文使用了一种加权的偏好优化损失函数,其中每个样本的权重由其效用值决定。
🖼️ 关键图片
📊 实验亮点
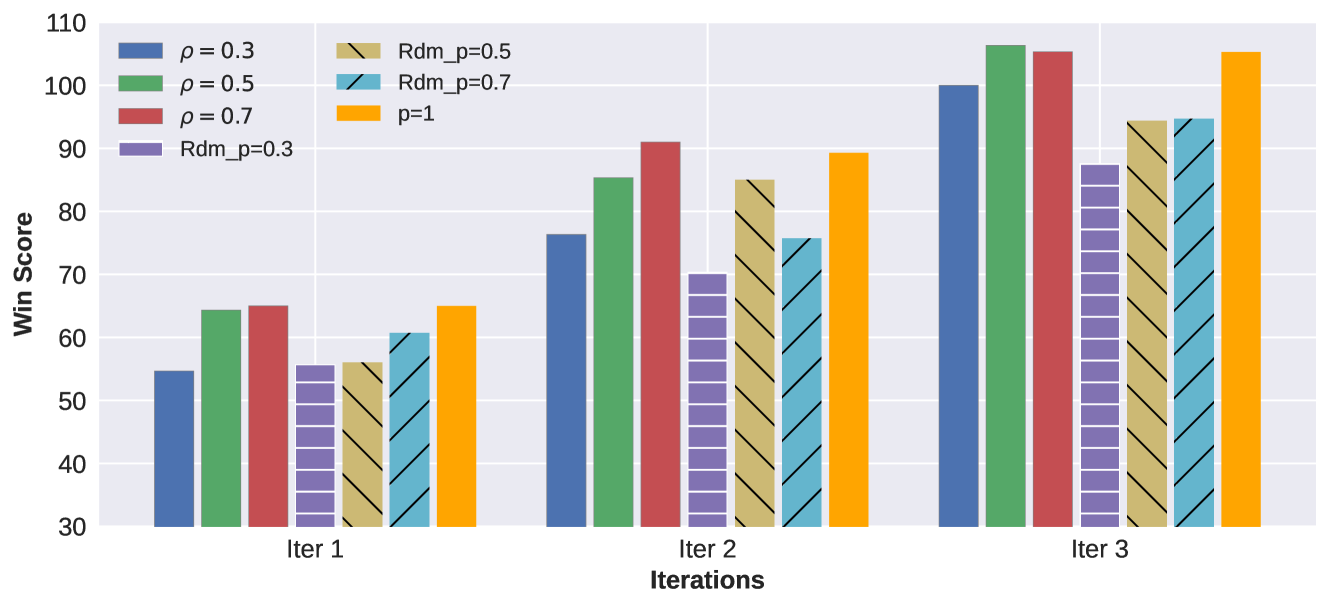
OPTune在实验中展现出显著的性能提升,在保持指令遵循能力的同时,训练速度比传统方法提高了1.27-1.56倍。这一结果表明,OPTune的高效数据探索策略能够有效地利用有限的计算资源,加速LLM的在线偏好调整过程。具体的性能指标和对比基线需要在论文中进一步查找。
🎯 应用场景
OPTune可应用于各种需要将大型语言模型与人类偏好对齐的场景,例如对话系统、内容生成、代码生成等。通过提高在线偏好调整的效率,OPTune可以降低模型训练成本,加速模型迭代周期,并最终提升模型的性能和用户体验。该方法在人机交互、智能助手等领域具有广泛的应用前景。
📄 摘要(原文)
Reinforcement learning with human feedback~(RLHF) is critical for aligning Large Language Models (LLMs) with human preference. Compared to the widely studied offline version of RLHF, \emph{e.g.} direct preference optimization (DPO), recent works have shown that the online variants achieve even better alignment. However, online alignment requires on-the-fly generation of new training data, which is costly, hard to parallelize, and suffers from varying quality and utility. In this paper, we propose a more efficient data exploration strategy for online preference tuning (OPTune), which does not rely on human-curated or pre-collected teacher responses but dynamically samples informative responses for on-policy preference alignment. During data generation, OPTune only selects prompts whose (re)generated responses can potentially provide more informative and higher-quality training signals than the existing responses. In the training objective, OPTune reweights each generated response (pair) by its utility in improving the alignment so that learning can be focused on the most helpful samples. Throughout our evaluations, OPTune'd LLMs maintain the instruction-following benefits provided by standard preference tuning whilst enjoying 1.27-1.56x faster training speed due to the efficient data exploration strategy.