LGR2: Language Guided Reward Relabeling for Accelerating Hierarchical Reinforcement Learning
作者: Utsav Singh, Pramit Bhattacharyya, Vinay P. Namboodiri
分类: cs.LG, cs.CL, cs.RO
发布日期: 2024-06-09 (更新: 2025-08-27)
💡 一句话要点
LGR2:利用语言引导的奖励重塑加速分层强化学习
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分层强化学习 语言引导 奖励重塑 大型语言模型 机器人控制
📋 核心要点
- 传统分层强化学习在高层策略学习中面临非平稳性问题,源于低层策略训练过程中的动态变化。
- LGR2利用大型语言模型生成语言引导的高层奖励函数,解耦奖励生成与低层策略变化,缓解非平稳性。
- LGR2结合目标条件事后经验重标记,提升稀疏奖励环境下的样本效率,并在真实机器人任务中验证有效性。
📝 摘要(中文)
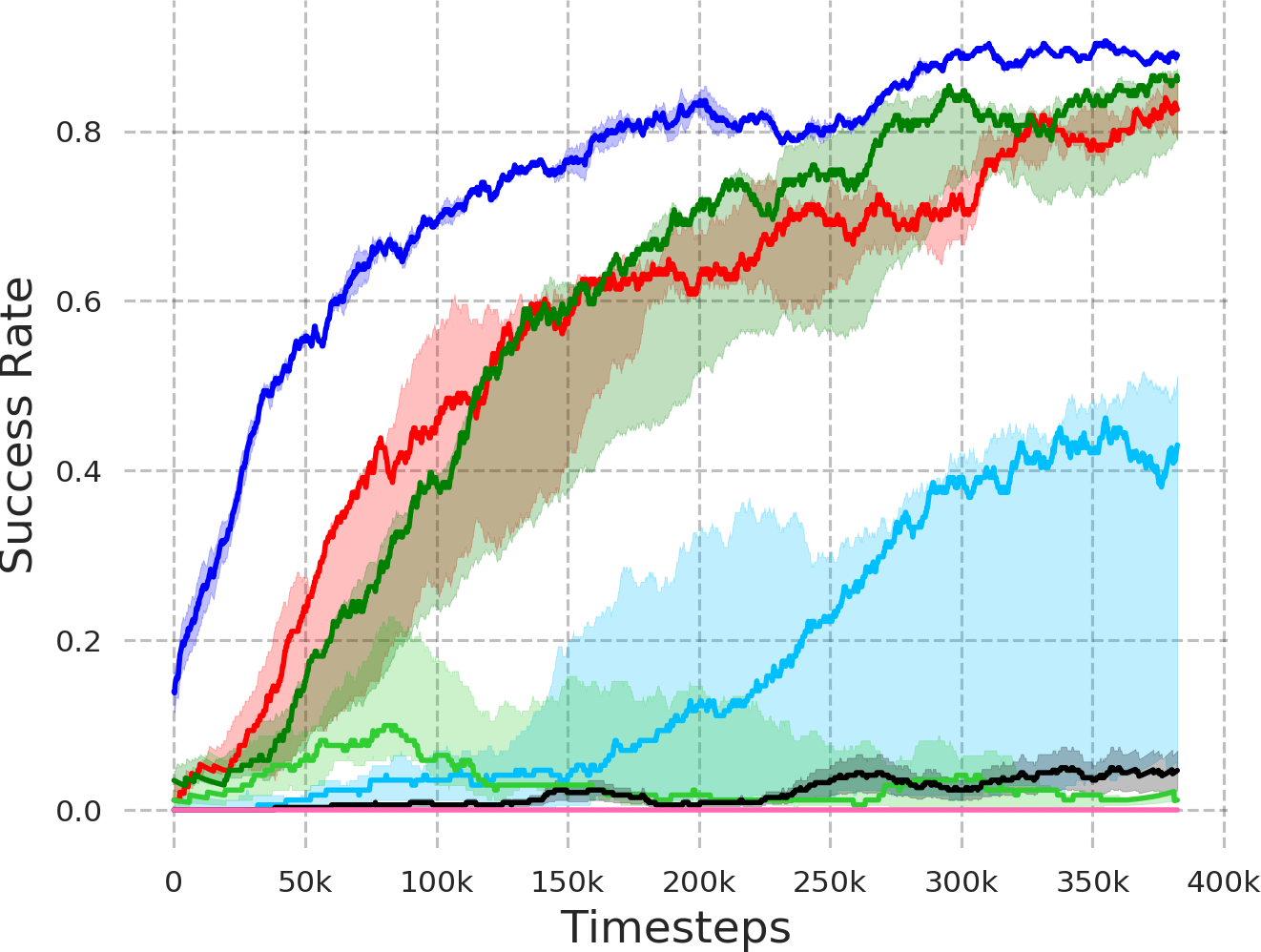
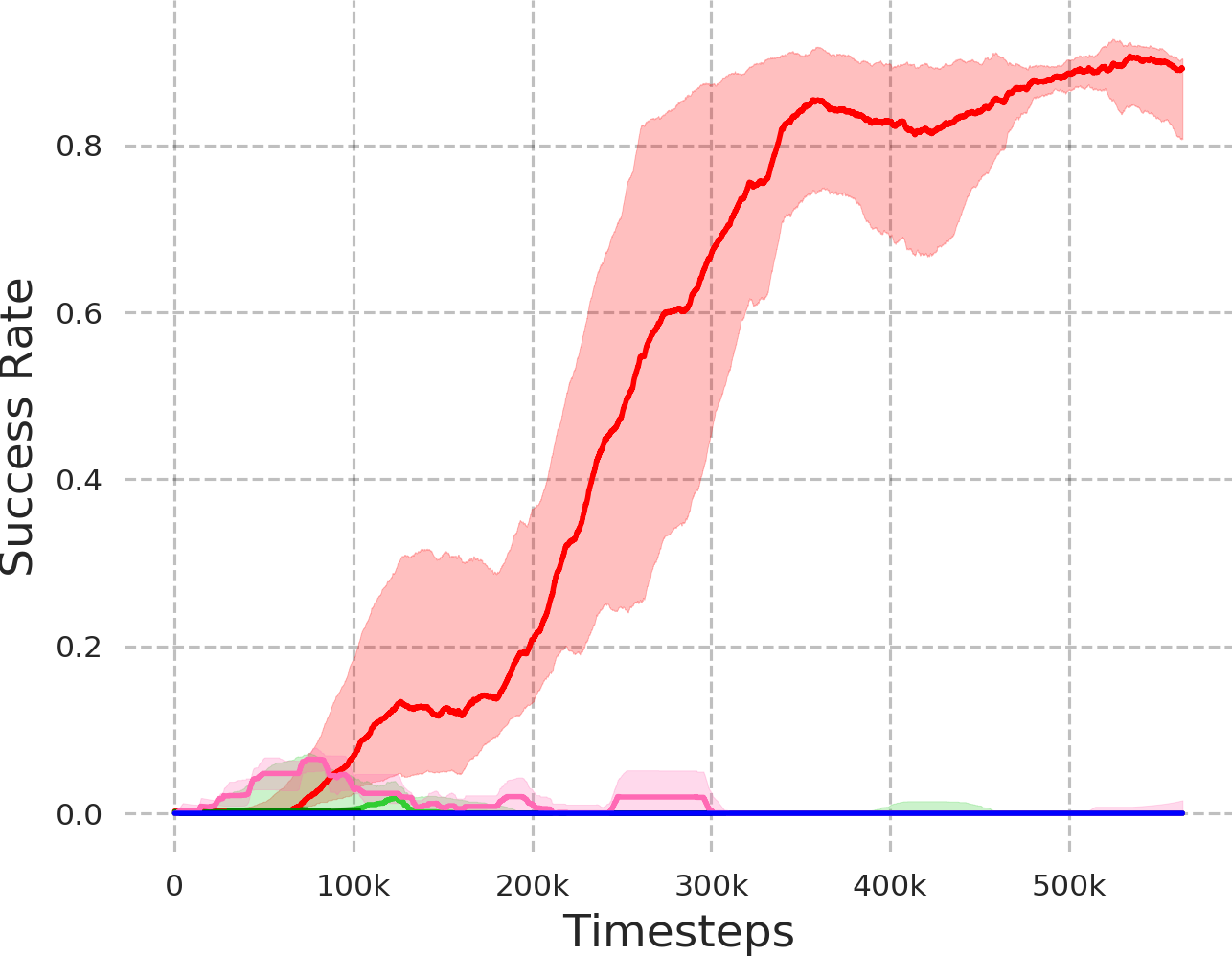
大型语言模型(LLMs)在逻辑推理、上下文学习和代码生成方面表现出卓越的能力。然而,将自然语言指令转化为有效的机器人控制策略仍然是一个重大挑战,特别是对于需要长程规划和在稀疏奖励条件下运行的任务。分层强化学习(HRL)为解决机器人领域的这一挑战提供了一个自然的框架;然而,它通常受到训练期间低层策略不断变化引起的非平稳性的影响,从而破坏了高层策略的学习。我们引入了LGR2,这是一种新颖的HRL框架,它利用LLM为高层策略生成语言引导的奖励函数。通过将高层奖励生成与低层策略变化解耦,LGR2从根本上缓解了离策略HRL中的非平稳性问题,从而实现稳定和高效的学习。为了进一步提高稀疏环境中的样本效率,我们集成了目标条件事后经验重标记。在模拟和真实世界机器人导航和操作任务中的大量实验表明,LGR2优于分层和非分层基线,在具有挑战性的任务中实现了超过55%的成功率,并实现了对真实机器人的稳健迁移,而无需额外的微调。
🔬 方法详解
问题定义:论文旨在解决分层强化学习(HRL)中高层策略学习因低层策略变化而产生的非平稳性问题。现有HRL方法在高层策略训练时,由于低层策略的不断演变,导致高层策略的学习环境不稳定,收敛速度慢,甚至无法收敛。尤其是在机器人控制等复杂任务中,这种非平稳性问题更加突出。
核心思路:LGR2的核心思路是利用大型语言模型(LLMs)生成语言引导的奖励函数,用于指导高层策略的学习。通过将高层奖励的生成与低层策略的训练过程解耦,从而有效地缓解了HRL中的非平稳性问题。这种方法使得高层策略可以在一个相对稳定的奖励信号下进行学习,从而提高学习效率和稳定性。
技术框架:LGR2框架包含以下几个主要模块:1) 低层策略模块:负责执行具体的动作,并根据环境反馈进行学习。2) 高层策略模块:负责制定长期目标或子任务,并根据语言引导的奖励函数进行学习。3) 语言引导的奖励生成模块:利用LLM将自然语言指令转化为高层策略的奖励函数。4) 目标条件事后经验重标记模块:用于提高稀疏奖励环境下的样本效率。整体流程是,高层策略根据当前状态和语言指令选择一个目标,低层策略执行动作以达到该目标,环境给出反馈,LLM根据环境反馈和语言指令生成高层奖励,高层策略根据该奖励进行更新。
关键创新:LGR2最重要的技术创新点在于利用LLM生成语言引导的奖励函数,从而解耦了高层奖励生成与低层策略变化。与传统的HRL方法相比,LGR2不再依赖于低层策略的反馈来生成高层奖励,而是利用LLM的强大推理能力,根据语言指令和环境反馈直接生成奖励信号。这种方法有效地缓解了非平稳性问题,提高了学习效率和稳定性。
关键设计:LGR2的关键设计包括:1) LLM的选择和使用:选择合适的LLM,并设计合适的prompt,以生成准确和有效的奖励函数。2) 奖励函数的形式:设计合适的奖励函数形式,例如稀疏奖励或密集奖励,以适应不同的任务需求。3) 目标条件事后经验重标记:采用HER算法,将失败的经验转化为成功的经验,从而提高样本效率。4) 损失函数的设计:设计合适的损失函数,以优化高层和低层策略的学习。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LGR2在模拟和真实世界的机器人导航和操作任务中均优于分层和非分层基线。在具有挑战性的任务中,LGR2实现了超过55%的成功率,并且能够成功地迁移到真实机器人上,而无需额外的微调。这表明LGR2具有很强的泛化能力和鲁棒性,能够有效地解决实际应用中的复杂问题。
🎯 应用场景
LGR2具有广泛的应用前景,尤其是在机器人控制、自动化任务规划和人机协作等领域。它可以用于开发能够理解自然语言指令并执行复杂任务的智能机器人系统。例如,在家庭服务机器人中,用户可以通过自然语言指令让机器人完成各种家务任务。在工业自动化领域,LGR2可以用于开发能够根据生产需求自动调整生产流程的智能机器人系统。此外,LGR2还可以应用于游戏AI、自动驾驶等领域。
📄 摘要(原文)
Large language models (LLMs) have shown remarkable abilities in logical reasoning, in-context learning, and code generation. However, translating natural language instructions into effective robotic control policies remains a significant challenge, especially for tasks requiring long-horizon planning and operating under sparse reward conditions. Hierarchical Reinforcement Learning (HRL) provides a natural framework to address this challenge in robotics; however, it typically suffers from non-stationarity caused by the changing behavior of the lower-level policy during training, destabilizing higher-level policy learning. We introduce LGR2, a novel HRL framework that leverages LLMs to generate language-guided reward functions for the higher-level policy. By decoupling high-level reward generation from low-level policy changes, LGR2 fundamentally mitigates the non-stationarity problem in off-policy HRL, enabling stable and efficient learning. To further enhance sample efficiency in sparse environments, we integrate goal-conditioned hindsight experience relabeling. Extensive experiments across simulated and real-world robotic navigation and manipulation tasks demonstrate LGR2 outperforms both hierarchical and non-hierarchical baselines, achieving over 55% success rates on challenging tasks and robust transfer to real robots, without additional fine-tuning.