MedualTime: A Dual-Adapter Language Model for Medical Time Series-Text Multimodal Learning
作者: Jiexia Ye, Weiqi Zhang, Ziyue Li, Jia Li, Meng Zhao, Fugee Tsung
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-06-07 (更新: 2025-09-08)
备注: 9 pages, 6 figure, 3 tables
期刊: IJCAI 2025 main conference
🔗 代码/项目: GITHUB
💡 一句话要点
MedualTime:一种用于医学时间序列-文本多模态学习的双适配器语言模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学多模态学习 时间序列分析 自然语言处理 语言模型 适配器 跨模态融合 临床报告
📋 核心要点
- 现有医学多模态学习方法倾向于以时间序列为主,忽略了文本模态中关键的临床信息。
- MedualTime提出一种文本-时间多模态学习范式,通过双适配器使两种模态可以相互增强。
- 实验表明,MedualTime在医学数据上表现出优异的性能,准确率提升8%,F1值提升12%。
📝 摘要(中文)
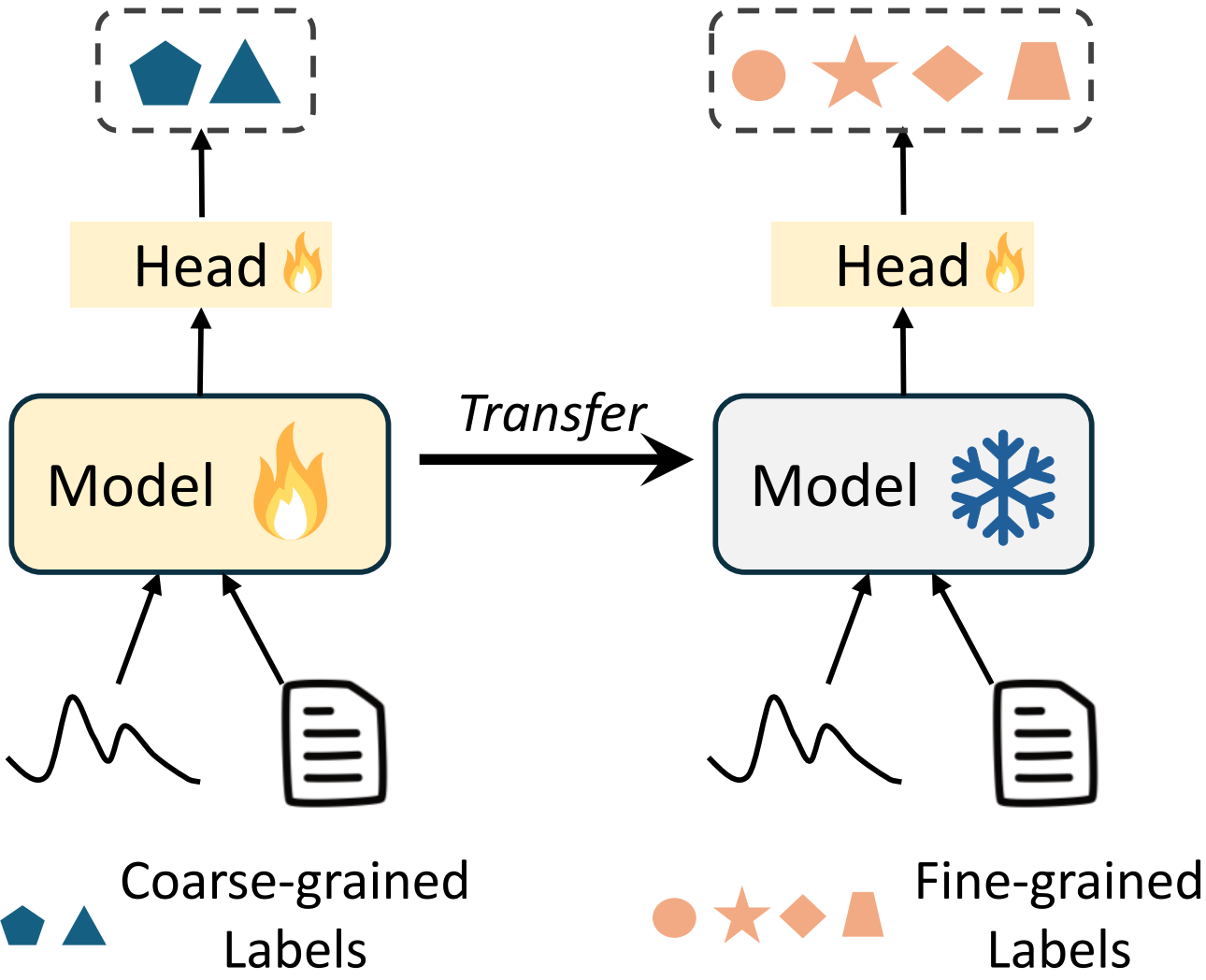
近年来,语言模型(LM)的快速发展引起了医学时间序列-文本多模态学习领域的关注。然而,现有的基于对比学习和基于提示的LM方法往往存在偏差,通常将时间序列模态置于主要地位,而将文本模态视为次要地位。我们将这些方法归类为时间优先范式,这种范式可能会忽略文本模态(如临床报告)中嵌入的独特且关键的任务相关信息,从而无法充分利用不同模态的互补优势。为了填补这一空白,我们提出了一种新的文本-时间多模态学习范式,该范式使任一模态都可以作为主要模态,并由另一模态增强,从而有效地捕获模态特定信息并促进跨模态交互。具体而言,我们设计了MedualTime,一个由双适配器组成的语言模型,用于同时实现时间优先和文本优先建模。在每个适配器中,轻量级适配令牌被注入到LM的顶层,以鼓励高层次的模态融合。双适配器共享的LM管道不仅实现了适配器对齐,而且实现了高效的微调,从而减少了计算资源。实验结果表明,MedualTime在医学数据上表现出卓越的性能,在监督设置下,准确率提高了8%,F1值提高了12%。此外,MedualTime的可迁移性通过从粗粒度到细粒度医学数据的少样本标签迁移实验得到验证。
🔬 方法详解
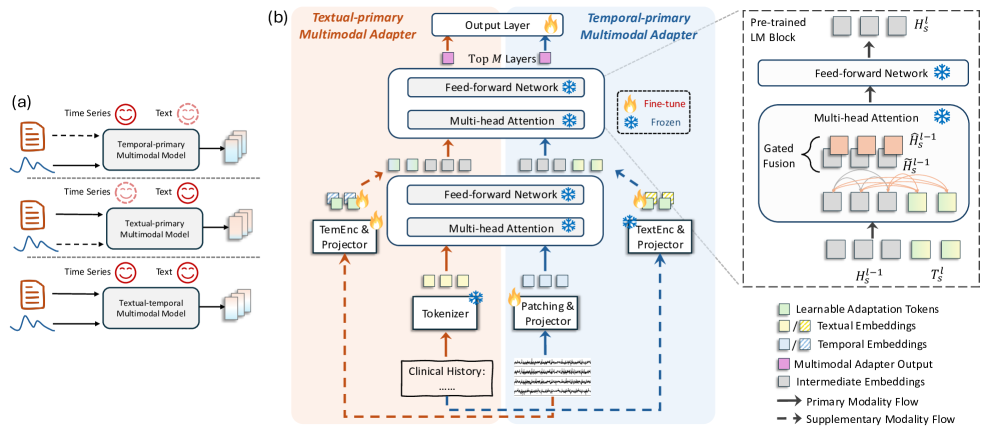
问题定义:现有医学时间序列-文本多模态学习方法,如基于对比学习或提示学习的方法,通常采用“时间优先”的范式,即主要依赖时间序列数据,而将文本数据视为辅助信息。这种做法忽略了文本数据中包含的丰富临床信息,例如临床报告中的诊断、病史等,导致模型无法充分利用两种模态的互补性,限制了模型的性能。
核心思路:MedualTime的核心思路是打破“时间优先”的范式,提出一种“文本-时间”多模态学习框架,允许文本和时间序列两种模态相互增强。具体来说,模型设计了两个适配器,一个以时间序列为主,另一个以文本为主,从而使模型能够同时学习两种模态的特定信息,并促进跨模态的交互。这种设计旨在更全面地利用两种模态的信息,提高模型的性能。
技术框架:MedualTime的整体架构包含一个共享的语言模型(LM)和两个适配器(adapters)。两个适配器分别负责处理时间序列和文本数据,并将其融合到共享的LM中。每个适配器都包含一系列轻量级的适配令牌(adaptation tokens),这些令牌被注入到LM的顶层,以促进高层次的模态融合。模型通过微调适配器来适应特定的任务,而共享的LM则保持不变,从而减少了计算资源。
关键创新:MedualTime最重要的技术创新点在于其双适配器的设计,它允许模型同时学习时间序列和文本两种模态的特定信息,并促进跨模态的交互。与传统的“时间优先”方法相比,MedualTime能够更全面地利用两种模态的信息,从而提高模型的性能。此外,共享的LM管道和轻量级的适配令牌设计也提高了模型的效率和可扩展性。
关键设计:MedualTime的关键设计包括:1) 双适配器的结构,分别处理时间序列和文本数据;2) 轻量级适配令牌的注入位置(LM的顶层),以促进高层次的模态融合;3) 共享的LM管道,以实现适配器对齐和高效的微调;4) 损失函数的设计,可能包含对比学习损失或交叉熵损失等,以促进模态之间的对齐和任务目标的优化(具体损失函数细节论文中未明确说明,属于未知信息)。
🖼️ 关键图片

📊 实验亮点
MedualTime在医学数据上取得了显著的性能提升。在监督学习设置下,MedualTime的准确率提高了8%,F1值提高了12%。此外,通过少样本标签迁移实验,验证了MedualTime在不同粒度医学数据上的可迁移性。这些结果表明,MedualTime能够有效地利用多模态信息,提高模型的性能和泛化能力。
🎯 应用场景
MedualTime在医疗健康领域具有广泛的应用前景,例如疾病诊断、预后预测、患者风险评估等。通过整合患者的生理信号(时间序列数据)和临床报告(文本数据),MedualTime可以为医生提供更全面、准确的决策支持,提高医疗服务的质量和效率。此外,该模型还可以应用于药物研发、临床试验等领域,加速医疗创新。
📄 摘要(原文)
The recent rapid advancements in language models (LMs) have garnered attention in medical time series-text multimodal learning. However, existing contrastive learning-based and prompt-based LM approaches tend to be biased, often assigning a primary role to time series modality while treating text modality as secondary. We classify these approaches under a temporal-primary paradigm, which may overlook the unique and critical task-relevant information embedded in text modality like clinical reports, thus failing to fully leverage mutual benefits and complementarity of different modalities. To fill this gap, we propose a novel textual-temporal multimodal learning paradigm that enables either modality to serve as the primary while being enhanced by the other, thereby effectively capturing modality-specific information and fostering cross-modal interaction. In specific, we design MedualTime, a language model composed of dual adapters to implement temporal-primary and textual-primary modeling simultaneously. Within each adapter, lightweight adaptation tokens are injected into the top layers of LM to encourage high-level modality fusion. The shared LM pipeline by dual adapters not only achieves adapter alignment but also enables efficient fine-tuning, reducing computational resources. Empirically, MedualTime demonstrates superior performance on medical data, achieving notable improvements of 8% accuracy and 12% F1 in supervised settings. Furthermore, MedualTime's transferability is validated by few-shot label transfer experiments from coarse-grained to fine-grained medical data. https://github.com/start2020/MedualTime