The Factorization Curse: Which Tokens You Predict Underlie the Reversal Curse and More
作者: Ouail Kitouni, Niklas Nolte, Diane Bouchacourt, Adina Williams, Mike Rabbat, Mark Ibrahim
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-06-07
备注: 18 pages, 7 figures
💡 一句话要点
揭示语言模型“分解诅咒”:探究Token预测目标对信息检索能力的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 反转诅咒 分解诅咒 信息检索 Token预测
📋 核心要点
- 现有语言模型在信息检索中存在“反转诅咒”问题,即以不同顺序提问时无法回忆训练信息。
- 论文将“反转诅咒”归因于“分解诅咒”,即模型在不同token序列下无法学习相同的联合概率分布。
- 实验表明,基于token预测的目标函数是“分解诅咒”的根源,并探索了与分解无关的目标函数以缓解该问题。
📝 摘要(中文)
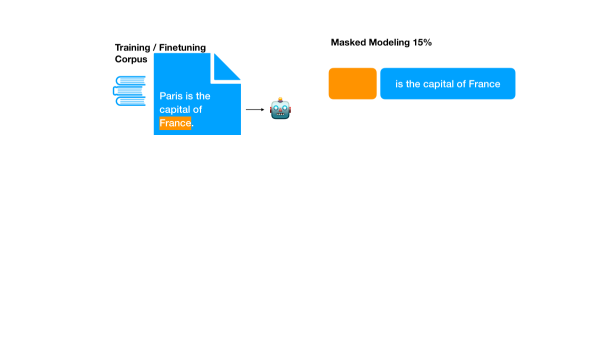
当前最佳的语言模型仍然面临幻觉问题,即生成不符合事实的内容,这阻碍了它们可靠地检索训练期间所见信息的能力。反转诅咒是其中的一个例子,模型无法以与训练时不同的顺序回忆信息。本文将反转诅咒重新定义为分解诅咒,即模型无法在不同的分解方式下学习相同的联合分布。通过一系列可控实验,包括模拟知识密集型微调任务的WikiReversal,发现分解诅咒是流行的大型语言模型中使用的下一个token预测目标的固有缺陷。此外,证明了可靠的信息检索无法通过扩大规模、反转token甚至简单的双向注意力训练来解决。因此,除非模型已经见过正确的token序列,否则在专门数据上进行微调的各种方法必然会在下游任务上产生好坏参半的结果。在五个不同复杂程度的任务中,结果揭示了一条有希望的道路:与分解无关的目标可以显著缓解反转诅咒,并暗示了改进的知识存储和规划能力。
🔬 方法详解
问题定义:论文旨在解决语言模型在信息检索中存在的“反转诅咒”问题。现有方法,如基于下一个token预测的训练方式,无法保证模型在不同token序列下学习到相同的知识,导致模型在面对与训练数据顺序不同的提问时,无法正确回忆信息。这种现象被称为“分解诅咒”,是现有语言模型的一个重要缺陷。
核心思路:论文的核心思路是将“反转诅咒”重新定义为“分解诅咒”,并认为这是由于模型训练目标(下一个token预测)导致的。该目标函数对token序列的顺序敏感,使得模型难以学习到与序列顺序无关的知识表示。因此,论文提出探索与分解无关的目标函数,以缓解“分解诅咒”问题。
技术框架:论文通过一系列可控实验来验证其观点。首先,设计了简单的合成数据集,用于验证模型在不同token序列下的学习能力。然后,引入了WikiReversal数据集,该数据集模拟了知识密集型微调任务,更贴近实际应用场景。最后,在五个不同复杂程度的任务上,比较了基于token预测的目标函数和与分解无关的目标函数的性能。
关键创新:论文最重要的技术创新点在于,将“反转诅咒”重新定义为“分解诅咒”,并指出这是由于基于token预测的训练目标导致的。这一观点为解决“反转诅咒”问题提供了新的思路。此外,论文还探索了与分解无关的目标函数,并验证了其在缓解“反转诅咒”方面的有效性。
关键设计:论文的关键设计包括:1) 设计了WikiReversal数据集,用于模拟知识密集型微调任务;2) 探索了与分解无关的目标函数,例如对比学习等;3) 在多个任务上进行了实验,验证了所提出方法的有效性。具体的参数设置、损失函数、网络结构等技术细节在论文中进行了详细描述(具体细节需要查阅原文)。
🖼️ 关键图片
📊 实验亮点
论文通过实验证明,基于token预测的目标函数是“分解诅咒”的根源,即使增加模型规模、反转token顺序或使用双向注意力机制也无法有效解决该问题。实验结果表明,与分解无关的目标函数可以显著缓解“反转诅咒”,并提升模型在信息检索等任务中的性能。具体性能提升数据需要在论文中查找。
🎯 应用场景
该研究成果可应用于提升语言模型在知识密集型任务中的表现,例如问答系统、信息检索、知识图谱构建等。通过缓解“分解诅咒”,可以使模型更可靠地回忆和利用训练数据中的知识,从而提高其在实际应用中的性能。未来的研究可以进一步探索更有效的与分解无关的目标函数,并将其应用于更大规模的语言模型。
📄 摘要(原文)
Today's best language models still struggle with hallucinations: factually incorrect generations, which impede their ability to reliably retrieve information seen during training. The reversal curse, where models cannot recall information when probed in a different order than was encountered during training, exemplifies this in information retrieval. We reframe the reversal curse as a factorization curse - a failure of models to learn the same joint distribution under different factorizations. Through a series of controlled experiments with increasing levels of realism including WikiReversal, a setting we introduce to closely simulate a knowledge intensive finetuning task, we find that the factorization curse is an inherent failure of the next-token prediction objective used in popular large language models. Moreover, we demonstrate reliable information retrieval cannot be solved with scale, reversed tokens, or even naive bidirectional-attention training. Consequently, various approaches to finetuning on specialized data would necessarily provide mixed results on downstream tasks, unless the model has already seen the right sequence of tokens. Across five tasks of varying levels of complexity, our results uncover a promising path forward: factorization-agnostic objectives can significantly mitigate the reversal curse and hint at improved knowledge storage and planning capabilities.