Online Frequency Scheduling by Learning Parallel Actions
作者: Anastasios Giovanidis, Mathieu Leconte, Sabrine Aroua, Tor Kvernvik, David Sandberg
分类: cs.NI, cs.LG, cs.MA
发布日期: 2024-06-07
备注: 9 pages, 5 figures, conference submission
期刊: 2024 3rd International Conference on 6G Networking (6GNet)
DOI: 10.1109/6GNet63182.2024.10765674
💡 一句话要点
提出基于并行动作学习的在线频率调度方法,解决多用户MIMO系统资源分配问题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 无线资源管理 频率调度 多用户MIMO 深度强化学习 动作分支 并行决策 在线学习
📋 核心要点
- 多用户MIMO系统中频率调度面临巨大动作空间和复杂约束,传统方法难以有效解决。
- 提出基于子带动作分支的深度Q学习架构,实现并行决策,优化全局奖励。
- 实验表明,该架构具有竞争力的性能,并能在线适应不断变化的环境。
📝 摘要(中文)
本文研究未来6G网络中无线资源管理的关键问题,即多用户MIMO系统中的频率调度。针对用户对可用资源竞争激烈的情况,提出一种基于并行动作学习的调度器。传统方法难以应对复杂约束和不确定性,而强化学习可以直接学习近优解。然而,调度问题存在巨大的动作空间。本文提出一种基于子带动作分支的调度器,采用具有并行决策能力的深度Q学习架构。子带学习相关但局部的决策策略,共同优化全局奖励。为了提高架构随子带数量的扩展性,提出了减少学习参数的变体(Unibranch,基于图神经网络)。该架构的并行决策能力满足了实际系统中对短推理时间的要求。此外,深度Q学习方法允许部署后进行在线微调,以弥合仿真与现实之间的差距。评估结果表明,所提出的架构与文献中的相关基线相比具有竞争力的性能,并具有在线适应不断变化环境的可能性。
🔬 方法详解
问题定义:论文旨在解决多用户MIMO系统中频率资源的有效分配问题。在未来的6G网络中,用户对无线资源的需求日益增长,传统的频率调度方法难以应对由此产生的复杂约束和不确定性,尤其是在动作空间巨大时,难以找到最优解。现有方法通常无法兼顾效率和实时性,难以满足实际应用的需求。
核心思路:论文的核心思路是利用深度强化学习,特别是深度Q学习,直接从环境中学习近优的调度策略。为了解决动作空间过大的问题,论文采用动作分支的思想,将整个频率调度问题分解为多个子带上的并行决策问题。每个子带独立学习决策策略,并通过全局奖励进行协调,从而实现整体优化。
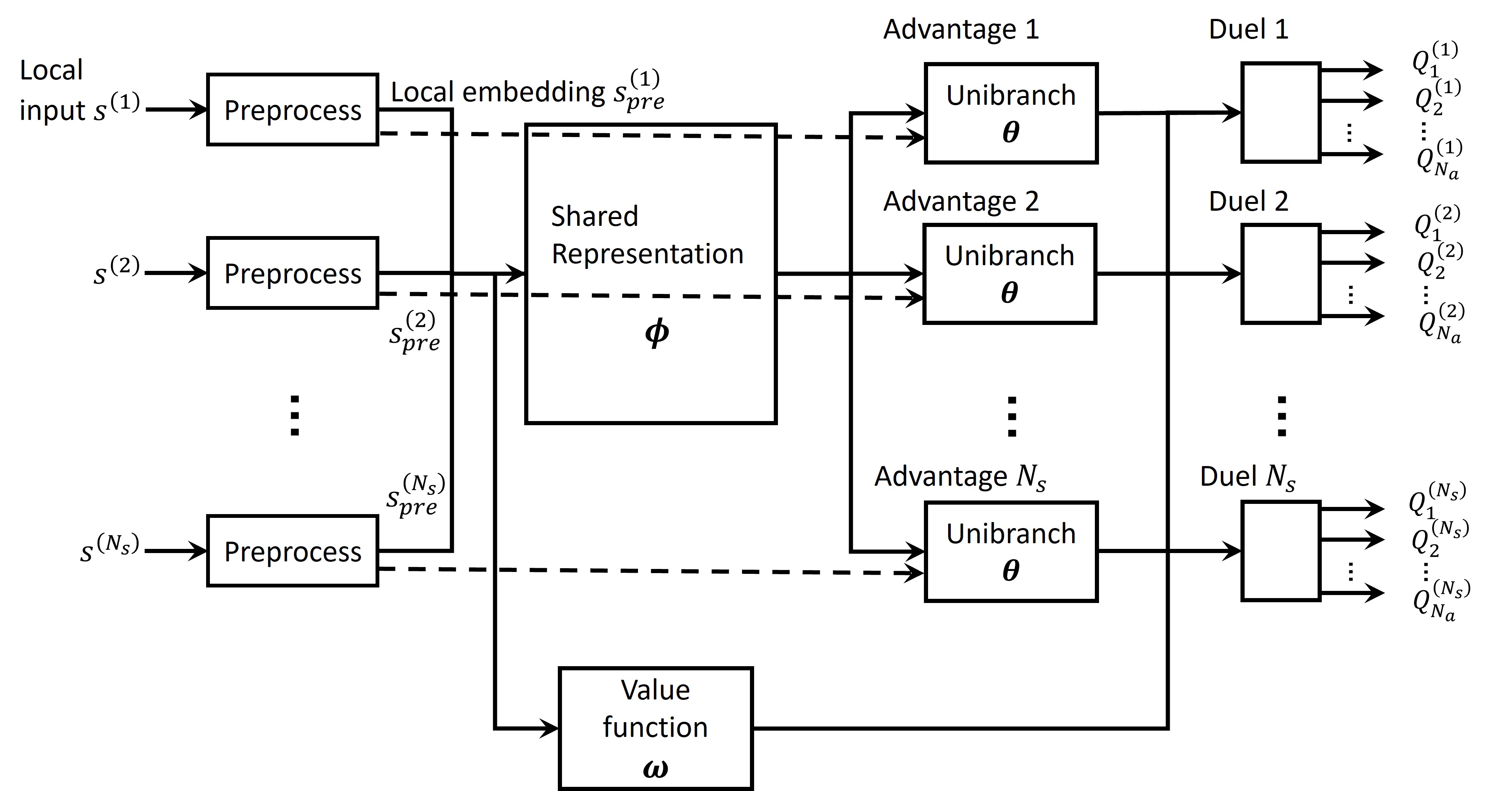
技术框架:整体框架包括以下几个主要模块:1) 状态表示:将系统状态(例如信道状态信息、用户队列长度等)编码为神经网络的输入。2) 动作分支:将频率资源划分为多个子带,每个子带对应一个动作分支。3) 深度Q网络:每个动作分支对应一个深度Q网络,用于估计在该子带上选择不同动作的Q值。4) 并行决策:所有子带的Q网络并行计算,选择具有最大Q值的动作。5) 奖励函数:定义一个全局奖励函数,用于评估整个调度策略的性能,例如系统吞吐量、用户公平性等。6) 在线微调:部署后,利用实际环境中的数据对Q网络进行在线微调,以适应环境变化。
关键创新:论文的关键创新在于提出了基于动作分支的并行决策架构,有效地解决了频率调度问题中动作空间过大的难题。通过将全局决策分解为多个局部决策,降低了学习的复杂性,提高了学习效率。此外,论文还提出了Unibranch和基于图神经网络的变体,进一步减少了参数数量,提高了架构的可扩展性。
关键设计:论文的关键设计包括:1) 动作分支的数量:需要根据实际系统的子带数量进行调整。2) 深度Q网络的结构:可以采用不同的神经网络结构,例如卷积神经网络、循环神经网络等,具体选择取决于状态表示的特点。3) 奖励函数的设计:需要仔细考虑系统性能的各个方面,例如吞吐量、公平性、时延等。4) 探索-利用策略:需要平衡探索和利用,以避免陷入局部最优解。5) 在线微调的策略:需要选择合适的学习率和更新频率,以避免过度拟合或欠拟合。
🖼️ 关键图片


📊 实验亮点
论文提出的架构与文献中的相关基线相比具有竞争力的性能,并且能够在线适应不断变化的环境。具体实验数据未在摘要中给出,但强调了其在线自适应能力和与现有方法的竞争力,暗示了在特定指标(如吞吐量、公平性等)上取得了显著提升。
🎯 应用场景
该研究成果可应用于未来的6G无线通信系统,特别是在多用户MIMO场景下,能够实现更高效、更智能的无线资源管理。通过在线学习和自适应调整,该方法能够适应不断变化的网络环境,提高系统性能和用户体验。此外,该方法还可以扩展到其他无线资源管理问题,例如功率控制、波束赋形等。
📄 摘要(原文)
Radio Resource Management is a challenging topic in future 6G networks where novel applications create strong competition among the users for the available resources. In this work we consider the frequency scheduling problem in a multi-user MIMO system. Frequency resources need to be assigned to a set of users while allowing for concurrent transmissions in the same sub-band. Traditional methods are insufficient to cope with all the involved constraints and uncertainties, whereas reinforcement learning can directly learn near-optimal solutions for such complex environments. However, the scheduling problem has an enormous action space accounting for all the combinations of users and sub-bands, so out-of-the-box algorithms cannot be used directly. In this work, we propose a scheduler based on action-branching over sub-bands, which is a deep Q-learning architecture with parallel decision capabilities. The sub-bands learn correlated but local decision policies and altogether they optimize a global reward. To improve the scaling of the architecture with the number of sub-bands, we propose variations (Unibranch, Graph Neural Network-based) that reduce the number of parameters to learn. The parallel decision making of the proposed architecture allows to meet short inference time requirements in real systems. Furthermore, the deep Q-learning approach permits online fine-tuning after deployment to bridge the sim-to-real gap. The proposed architectures are evaluated against relevant baselines from the literature showing competitive performance and possibilities of online adaptation to evolving environments.