CTSyn: A Foundation Model for Cross Tabular Data Generation
作者: Xiaofeng Lin, Chenheng Xu, Matthew Yang, Guang Cheng
分类: cs.LG, stat.ML
发布日期: 2024-06-07 (更新: 2025-11-26)
💡 一句话要点
提出CTSyn,一种基于扩散模型的跨表格数据生成基础模型,显著提升合成数据的质量和多样性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表格数据生成 扩散模型 自编码器 跨表格学习 生成式基础模型
📋 核心要点
- 现有跨表格学习框架缺乏生成模型骨干,难以有效处理表格数据的异构性,限制了合成数据的质量。
- CTSyn通过自编码器将异构表格数据映射到统一的潜在空间,并利用条件潜在扩散模型生成高质量的合成数据。
- 大规模预训练表明,CTSyn在合成数据的效用和多样性方面超越了现有方法,为表格数据生成提供新思路。
📝 摘要(中文)
生成式基础模型(GFMs)在图像和文本合成数据生成方面取得了显著成功。然而,由于表格特征的异构性,将其应用于表格数据面临巨大挑战。现有的跨表格学习框架缺乏生成模型骨干和有效的异构特征值解码机制。为了解决这些问题,我们提出了跨表格合成器(CTSyn),一种基于扩散的表格数据生成基础模型。CTSyn包含两个关键组件:一是将各种表格整合到统一潜在空间的自编码器网络,它使用表格模式嵌入动态地重建表格值,从而适应异构数据集;二是条件潜在扩散模型,它根据表格模式从学习到的潜在空间生成样本。通过大规模预训练,CTSyn在效用和多样性方面均优于现有表格合成器,使其成为合成表格生成的一个有前景的框架,并为开发大规模表格基础模型奠定了基础。
🔬 方法详解
问题定义:论文旨在解决跨表格数据生成问题,即如何生成高质量、多样化的合成表格数据。现有方法,特别是跨表格学习框架,通常缺乏有效的生成模型骨干,难以处理表格数据中固有的异构性,例如不同的数据类型、缺失值和表格结构。这导致生成的合成数据质量不高,无法充分反映真实数据的分布特征。
核心思路:CTSyn的核心思路是利用扩散模型强大的生成能力,结合自编码器学习表格数据的潜在表示,从而实现高质量的跨表格数据生成。通过将异构的表格数据映射到统一的潜在空间,并利用条件扩散模型进行采样,CTSyn能够生成既具有高保真度又具有多样性的合成数据。
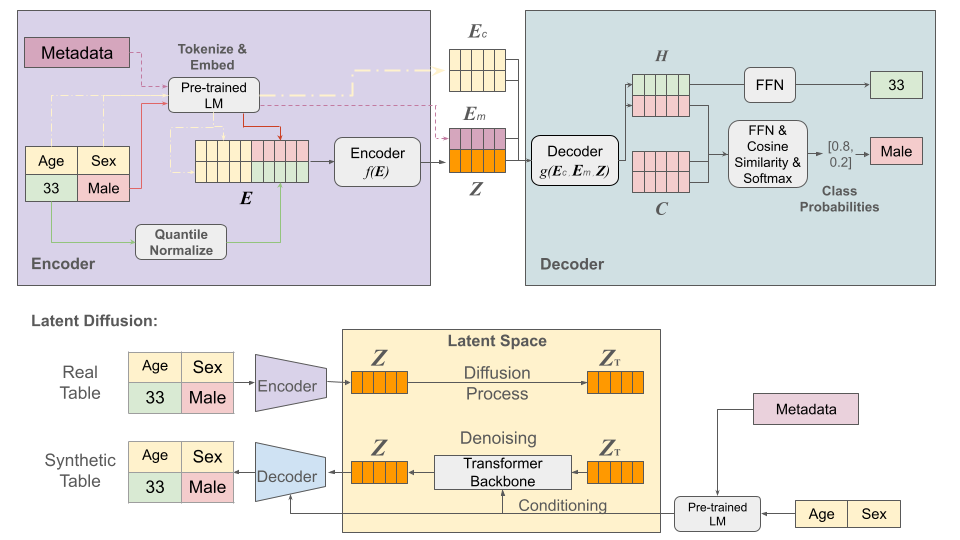
技术框架:CTSyn主要包含两个核心模块:自编码器网络和条件潜在扩散模型。首先,自编码器网络负责将不同的表格数据编码到统一的潜在空间中,该网络利用表格模式嵌入来动态重建表格值,从而适应异构数据集。然后,条件潜在扩散模型以表格模式为条件,从学习到的潜在空间中生成新的样本。整个框架通过大规模预训练进行优化,以提高生成数据的质量和多样性。
关键创新:CTSyn的关键创新在于将扩散模型应用于跨表格数据生成,并设计了自编码器网络来处理表格数据的异构性。与传统的生成对抗网络(GANs)等方法相比,扩散模型具有更好的稳定性和生成质量。此外,CTSyn通过表格模式嵌入来指导数据的重建和生成,从而更好地控制生成数据的属性。
关键设计:自编码器网络的设计至关重要,它需要能够有效地处理不同类型的表格数据,并学习到有意义的潜在表示。条件潜在扩散模型的设计也需要考虑如何有效地利用表格模式信息来指导生成过程。具体的参数设置、损失函数和网络结构等细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片

📊 实验亮点
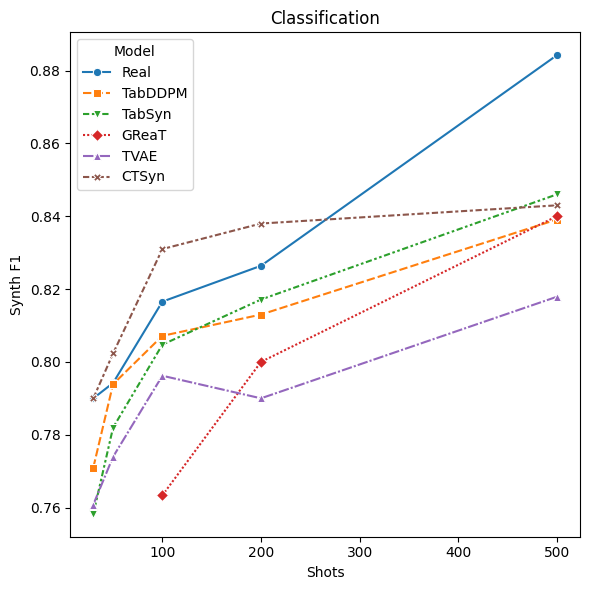
CTSyn通过大规模预训练,在标准基准测试中,合成数据的效用和多样性均优于现有的表格合成器。具体的性能提升数据和对比基线需要在论文中查找(未知),但总体而言,实验结果表明CTSyn是一种有竞争力的表格数据生成方法。
🎯 应用场景
CTSyn具有广泛的应用前景,包括数据增强、隐私保护、模型训练和数据分析等。通过生成高质量的合成表格数据,可以有效解决数据稀缺问题,提高机器学习模型的性能。此外,CTSyn还可以用于生成匿名化的数据,保护用户隐私。该研究为开发大规模表格基础模型奠定了基础,有望推动表格数据分析和应用的发展。
📄 摘要(原文)
Generative Foundation Models (GFMs) have achieved remarkable success in producing high-quality synthetic data for images and text. However, their application to tabular data presents significant challenges due to the heterogeneous nature of table features. Current cross-table learning frameworks struggle because they lack a generative model backbone and an effective mechanism to decode heterogeneous feature values. To address these challenges, we propose the Cross-Table Synthesizer (CTSyn), a diffusion-based generative foundation model for tabular data generation. CTSyn comprises two key components. The first is an autoencoder network that consolidates diverse tables into a unified latent space. It dynamically reconstructs table values using a table schema embedding, allowing adaptation to heterogeneous datasets. The second is a conditional latent diffusion model that generates samples from the learned latent space, conditioned on the table schema. Through large-scale pre-training, CTSyn outperforms existing table synthesizers on standard benchmarks in both utility and diversity. These results position CTSyn as a promising framework for synthetic table generation and lay the groundwork for developing large-scale tabular foundation models.