Helpful or Harmful Data? Fine-tuning-free Shapley Attribution for Explaining Language Model Predictions
作者: Jingtan Wang, Xiaoqiang Lin, Rui Qiao, Chuan-Sheng Foo, Bryan Kian Hsiang Low
分类: cs.LG, cs.AI
发布日期: 2024-06-07
备注: Accepted to ICML 2024
🔗 代码/项目: GITHUB
💡 一句话要点
提出FreeShap:一种免微调的Shapley值近似方法,用于解释语言模型预测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 可解释性 实例归因 Shapley值 神经正切核 免微调 语言模型 数据选择 数据清洗
📋 核心要点
- 现有基于留一法的实例归因方法在数据集重采样时缺乏鲁棒性,导致解释不一致。
- 提出FreeShap,一种基于神经正切核的Shapley值近似方法,无需微调即可高效计算实例归因。
- 实验表明,FreeShap在数据移除、数据选择和错误标签检测等任务上优于其他实例归因方法,并可扩展到LLM。
📝 摘要(中文)
随着基础模型复杂性的增加,可解释性变得至关重要,尤其是在微调这种最广泛使用的模型适应下游任务的训练方法中。实例归因是一种解释方法,它通过实例分数将模型预测归因于每个训练样本。然而,实例分数的鲁棒性,特别是对于数据集重采样的鲁棒性,一直被忽视。为了弥补这一差距,我们提出了一种关于实例分数符号的鲁棒性概念。我们从理论上和经验上证明,流行的基于留一法的方法缺乏鲁棒性,而Shapley值表现得更好,但计算成本更高。因此,我们引入了一种高效的、免微调的Shapley值近似方法(FreeShap),用于基于神经正切核的实例归因。经验表明,FreeShap在实例归因和其他以数据为中心的应用(如数据移除、数据选择和错误标签检测)方面优于其他方法,并进一步将我们的规模推广到大型语言模型(LLM)。我们的代码可在https://github.com/JTWang2000/FreeShap获得。
🔬 方法详解
问题定义:论文旨在解决语言模型预测的可解释性问题,特别是如何准确评估训练数据对模型预测的影响。现有的基于留一法的实例归因方法,虽然简单,但在数据集重采样时表现出不稳定性,即对同一实例的归因分数符号可能发生变化,这使得解释结果不可靠。此外,精确计算Shapley值的计算成本很高,限制了其在大规模数据集上的应用。
核心思路:论文的核心思路是利用神经正切核(NTK)来近似计算Shapley值,从而在保证归因结果鲁棒性的同时,降低计算复杂度。Shapley值是一种公平的归因方法,能够量化每个训练样本对模型预测的贡献。通过NTK,可以避免对模型进行多次微调,从而显著提高计算效率。
技术框架:FreeShap方法主要包含以下几个阶段:1) 使用预训练的语言模型;2) 利用训练数据集计算神经正切核矩阵;3) 基于NTK矩阵,近似计算每个训练样本的Shapley值;4) 使用计算得到的Shapley值进行实例归因,并应用于数据移除、数据选择和错误标签检测等下游任务。整个框架无需对预训练模型进行微调。
关键创新:FreeShap的关键创新在于提出了一种免微调的Shapley值近似方法。与传统的需要多次微调的Shapley值计算方法相比,FreeShap利用NTK避免了微调过程,大大降低了计算成本。此外,FreeShap在理论上保证了归因结果的鲁棒性,即对数据集的微小扰动不会显著改变归因分数的符号。
关键设计:FreeShap的关键设计包括:1) 使用预训练语言模型的NTK来捕获模型的行为;2) 利用NTK矩阵的逆矩阵来高效计算Shapley值;3) 设计了一种基于Shapley值的实例选择策略,用于数据移除和数据选择等任务。具体而言,NTK矩阵的计算涉及到对模型参数的梯度计算,而Shapley值的近似计算则依赖于NTK矩阵的特征值分解或矩阵求逆等操作。
🖼️ 关键图片

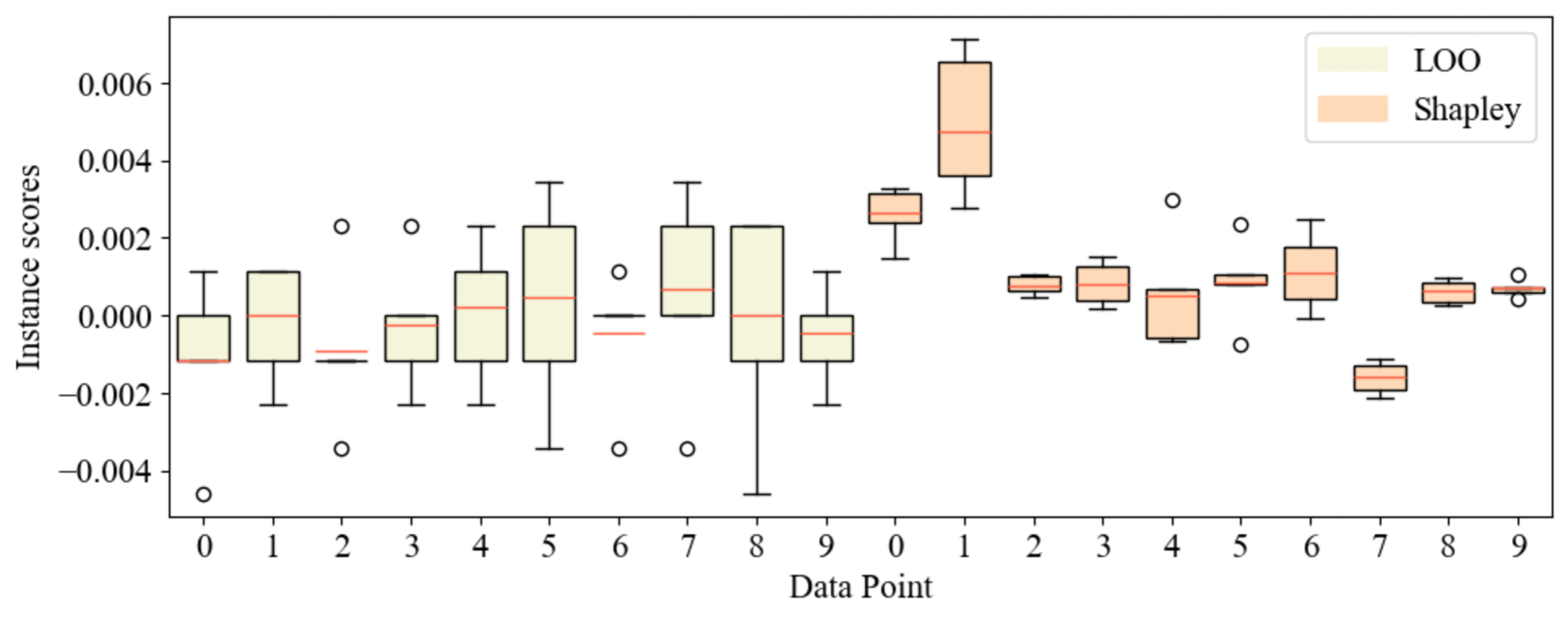
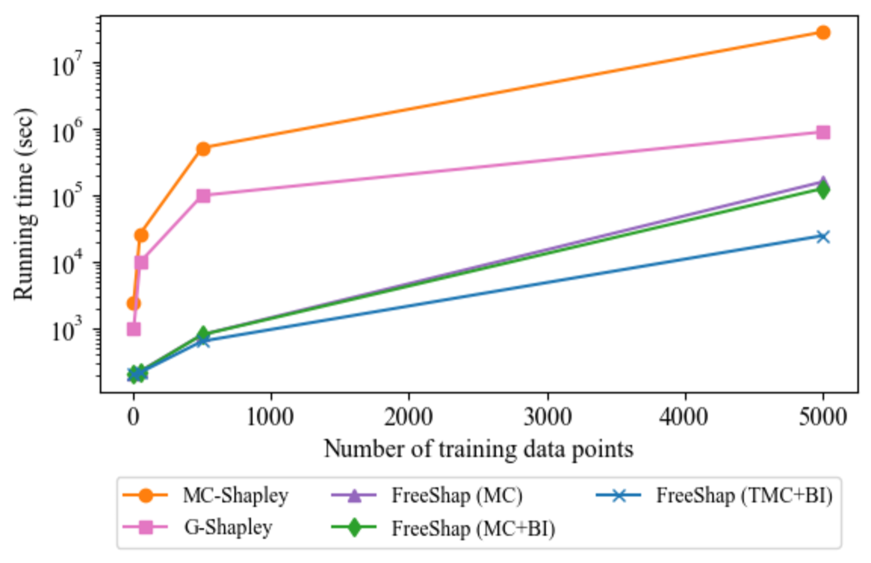
📊 实验亮点
实验结果表明,FreeShap在实例归因任务上优于其他基线方法,并且在数据移除、数据选择和错误标签检测等任务上取得了显著的性能提升。例如,在数据移除任务中,使用FreeShap选择移除有害数据能够更有效地提高模型性能。此外,FreeShap能够扩展到大型语言模型,证明了其在大规模数据上的有效性和可扩展性。
🎯 应用场景
该研究成果可应用于提高语言模型的可解释性和可靠性。例如,可以用于识别对模型预测产生负面影响的训练数据,从而进行数据清洗和优化。此外,还可以用于数据选择,选择对模型性能提升最大的数据子集进行训练。该方法在自动驾驶、医疗诊断等安全攸关领域具有重要应用价值,有助于建立用户对AI系统的信任。
📄 摘要(原文)
The increasing complexity of foundational models underscores the necessity for explainability, particularly for fine-tuning, the most widely used training method for adapting models to downstream tasks. Instance attribution, one type of explanation, attributes the model prediction to each training example by an instance score. However, the robustness of instance scores, specifically towards dataset resampling, has been overlooked. To bridge this gap, we propose a notion of robustness on the sign of the instance score. We theoretically and empirically demonstrate that the popular leave-one-out-based methods lack robustness, while the Shapley value behaves significantly better, but at a higher computational cost. Accordingly, we introduce an efficient fine-tuning-free approximation of the Shapley value (FreeShap) for instance attribution based on the neural tangent kernel. We empirically demonstrate that FreeShap outperforms other methods for instance attribution and other data-centric applications such as data removal, data selection, and wrong label detection, and further generalize our scale to large language models (LLMs). Our code is available at https://github.com/JTWang2000/FreeShap.