What is Dataset Distillation Learning?
作者: William Yang, Ye Zhu, Zhiwei Deng, Olga Russakovsky
分类: cs.LG
发布日期: 2024-06-06 (更新: 2024-07-22)
备注: ICML 2024
💡 一句话要点
研究数据集蒸馏学习,揭示蒸馏数据特性与信息存储方式
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 数据集蒸馏 合成数据 模型训练 信息压缩 语义信息 泛化能力 训练动态
📋 核心要点
- 现有数据集蒸馏方法对蒸馏数据的行为、代表性和信息内容理解不足,限制了其应用。
- 论文通过分析蒸馏数据的特性,揭示其信息存储方式,并提供了解释蒸馏数据的框架。
- 研究表明蒸馏数据在特定场景外无法替代真实数据,且压缩了模型早期训练动态信息。
📝 摘要(中文)
数据集蒸馏是一种通过学习紧凑的合成数据集来克服大型数据集相关障碍的策略,该合成数据集保留了原始数据集中的关键信息。虽然蒸馏数据可用于训练高性能模型,但人们对其信息存储方式知之甚少。本研究提出了关于蒸馏数据的行为、代表性和逐点信息内容三个问题并给出了答案。我们揭示了蒸馏数据不能在数据集蒸馏的标准评估设置之外用作训练期间真实数据的替代品。此外,蒸馏过程通过压缩与真实模型早期训练动态相关的信息来保持高任务性能。最后,我们提供了一个解释蒸馏数据的框架,并揭示了单个蒸馏数据点包含有意义的语义信息。这项研究揭示了蒸馏数据的复杂性质,从而更好地理解如何有效地利用它们。
🔬 方法详解
问题定义:论文旨在深入理解数据集蒸馏学习,特别是蒸馏后的合成数据集中信息是如何存储的。现有方法虽然能够生成用于训练的蒸馏数据集,但缺乏对这些数据集内在性质的理解,例如,它们是否能像真实数据一样泛化,以及它们所包含的信息类型。这种理解的缺失阻碍了数据集蒸馏技术的进一步发展和应用。
核心思路:论文的核心思路是通过实验分析来揭示蒸馏数据的特性。具体来说,论文关注三个关键问题:蒸馏数据是否能作为真实数据的替代品进行训练?蒸馏数据如何保持任务性能?以及单个蒸馏数据点是否包含有意义的语义信息?通过回答这些问题,论文旨在提供对蒸馏数据更深入的理解。
技术框架:论文没有提出新的数据集蒸馏算法,而是采用实验分析的方法来研究现有蒸馏数据集的性质。其框架主要包括以下几个部分:1) 设计实验来评估蒸馏数据在不同场景下的泛化能力;2) 分析蒸馏数据与真实数据在训练动态上的差异;3) 提出一个框架来解释单个蒸馏数据点所包含的语义信息。
关键创新:论文的主要创新在于其研究视角和实验分析方法。它不是简单地提出一种新的蒸馏算法,而是深入研究现有蒸馏数据集的性质,揭示了蒸馏数据的一些重要特性,例如,它不能完全替代真实数据,并且压缩了模型早期训练动态的信息。此外,论文还提出了一个解释蒸馏数据点语义信息的框架,为理解蒸馏数据提供了新的思路。
关键设计:论文的关键设计在于其精心设计的实验。例如,为了评估蒸馏数据的泛化能力,论文在不同的训练设置下比较了使用蒸馏数据和真实数据训练的模型的性能。为了分析蒸馏数据与真实数据在训练动态上的差异,论文比较了使用两种数据训练的模型在不同训练阶段的特征表示。为了解释蒸馏数据点的语义信息,论文采用可视化和解释性方法来分析单个数据点对模型预测的影响。
🖼️ 关键图片

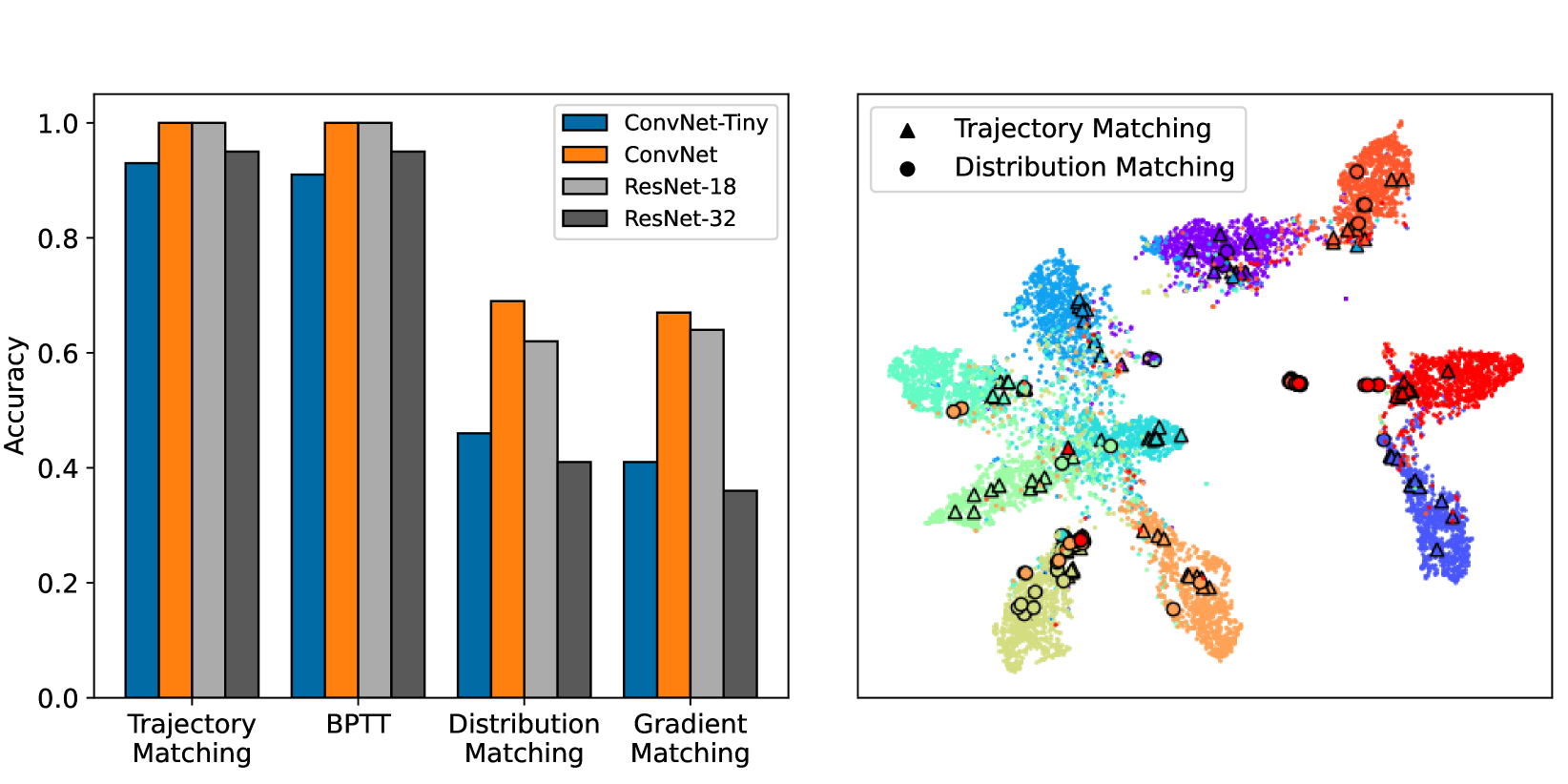
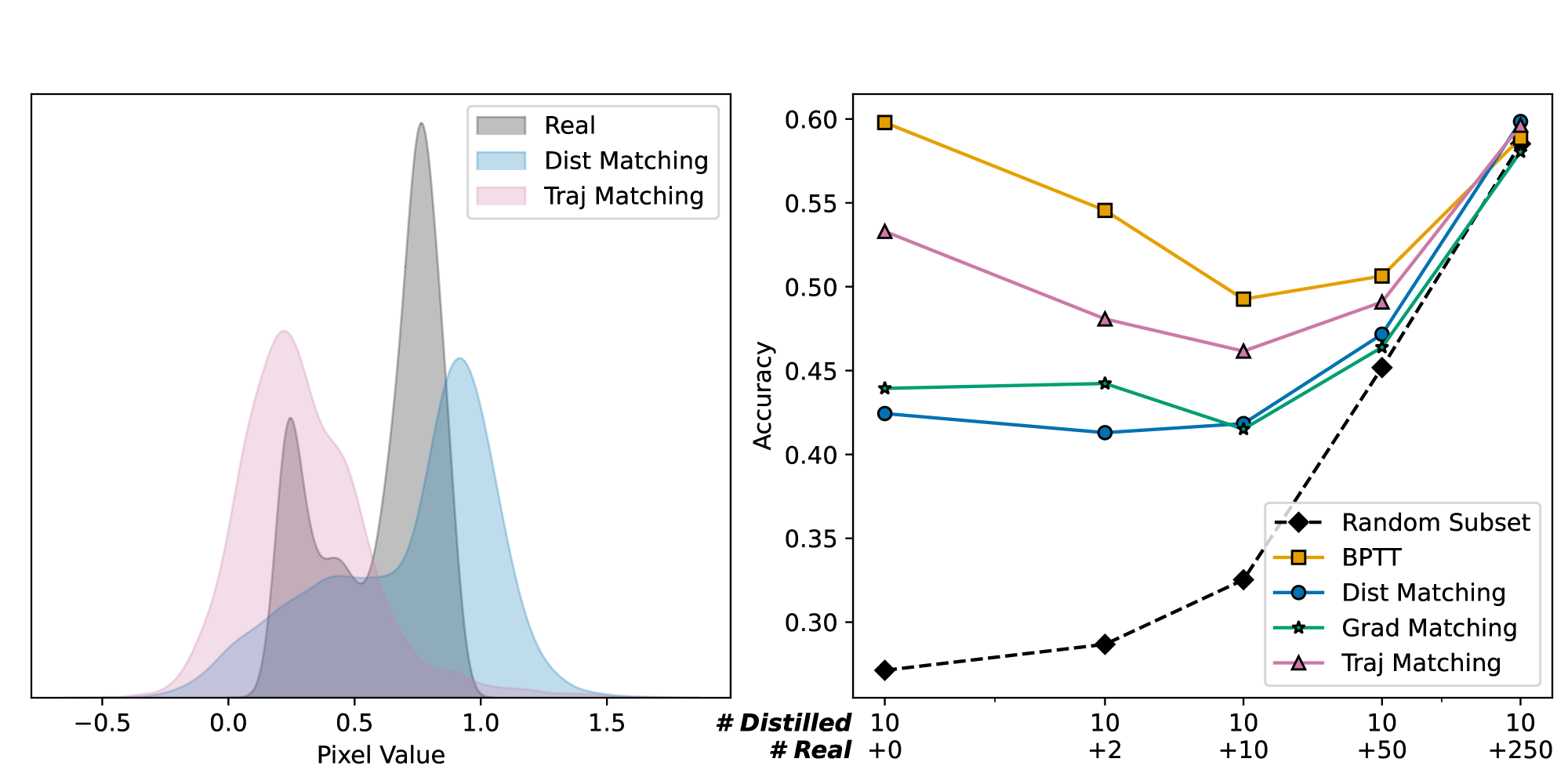
📊 实验亮点
研究表明,蒸馏数据在标准评估设置之外不能作为真实数据的替代品。蒸馏过程通过压缩与真实模型早期训练动态相关的信息来保持高任务性能。此外,论文提供了一个解释蒸馏数据的框架,并揭示了单个蒸馏数据点包含有意义的语义信息。
🎯 应用场景
该研究成果有助于更好地理解和利用数据集蒸馏技术,例如,可以指导如何选择合适的蒸馏算法,如何利用蒸馏数据进行模型训练,以及如何解释蒸馏数据所包含的信息。潜在应用领域包括数据压缩、模型加速、隐私保护等。
📄 摘要(原文)
Dataset distillation has emerged as a strategy to overcome the hurdles associated with large datasets by learning a compact set of synthetic data that retains essential information from the original dataset. While distilled data can be used to train high performing models, little is understood about how the information is stored. In this study, we posit and answer three questions about the behavior, representativeness, and point-wise information content of distilled data. We reveal distilled data cannot serve as a substitute for real data during training outside the standard evaluation setting for dataset distillation. Additionally, the distillation process retains high task performance by compressing information related to the early training dynamics of real models. Finally, we provide an framework for interpreting distilled data and reveal that individual distilled data points contain meaningful semantic information. This investigation sheds light on the intricate nature of distilled data, providing a better understanding on how they can be effectively utilized.