Aligning Agents like Large Language Models
作者: Adam Jelley, Yuhan Cao, Dave Bignell, Amos Storkey, Sam Devlin, Tabish Rashid
分类: cs.LG, cs.AI
发布日期: 2024-06-06 (更新: 2025-12-28)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
借鉴LLM训练范式,提升3D环境中智能体通用性和鲁棒性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 智能体训练 大型语言模型 强化学习 3D环境 通用人工智能
📋 核心要点
- 传统强化学习训练智能体在复杂3D环境中行动,面临奖励函数设计困难和泛化能力不足的挑战。
- 该论文借鉴LLM的训练范式,通过类比决策智能体和LLM,探索一种新的智能体训练方法。
- 论文提供概念验证,展示了LLM训练流程应用于3D游戏环境智能体的可行性,并分析了各阶段的重要性。
📝 摘要(中文)
在复杂3D环境中,从高维视觉信息中训练智能体做出有效行为极具挑战。强化学习是常用的训练方法,但需要精心设计的奖励函数,且难以扩展以获得能泛化到新任务的鲁棒智能体。相比之下,大型语言模型(LLM)通过大规模预训练和后训练对齐,展现出令人印象深刻的通用能力,但难以在复杂环境中行动。本文在决策智能体和LLM之间建立了明确的类比,并认为应该像训练LLM一样训练智能体,以实现更通用、鲁棒和对齐的行为。我们提供了一个概念验证,展示了如何使用训练LLM的程序,从像素训练3D视频游戏环境中的智能体。我们研究了LLM训练流程中每个阶段的重要性,同时为成功地将这种方法应用于智能体提供指导和见解。我们的论文为当代LLM智能体提供了一个替代视角,即如何利用LLM的最新进展来改进决策智能体,我们希望能够为开发更通用的视频游戏及其他领域的智能体指明方向。
🔬 方法详解
问题定义:当前,训练智能体在复杂3D环境中行动面临两大难题。一是强化学习对奖励函数的设计要求极高,需要领域专家知识,且微小的改动可能导致智能体行为的巨大变化。二是强化学习训练的智能体泛化能力较差,难以适应新的任务和环境。
核心思路:论文的核心思路是将LLM的训练范式迁移到智能体训练中。LLM通过大规模预训练和对齐,展现出强大的通用能力。借鉴LLM的训练方式,可以使智能体也具备更强的通用性和鲁棒性,从而克服传统强化学习的局限性。
技术框架:该论文提出了一个基于LLM训练流程的智能体训练框架,主要包含以下几个阶段:1. 数据收集:收集智能体在各种环境和任务中的行为数据。2. 预训练:使用收集到的数据对智能体进行预训练,使其学习环境的通用表示。3. 对齐:通过奖励建模或人类反馈等方式,使智能体的行为与人类的期望对齐。4. 微调:在特定任务上对智能体进行微调,使其能够完成该任务。
关键创新:该论文的关键创新在于将LLM的训练范式应用于智能体训练。与传统的强化学习方法相比,该方法不需要精心设计的奖励函数,并且能够使智能体具备更强的通用性和鲁棒性。此外,该论文还对LLM训练流程的各个阶段进行了分析,并为智能体训练提供了指导和见解。
关键设计:论文中,智能体采用深度神经网络结构,输入为像素级别的视觉信息。预训练阶段,采用自监督学习的方式,例如预测下一帧图像或重建当前帧图像。对齐阶段,可以使用奖励建模,通过学习人类对智能体行为的偏好来调整智能体的策略。微调阶段,可以使用强化学习算法,例如PPO或DQN,在特定任务上对智能体进行微调。
🖼️ 关键图片

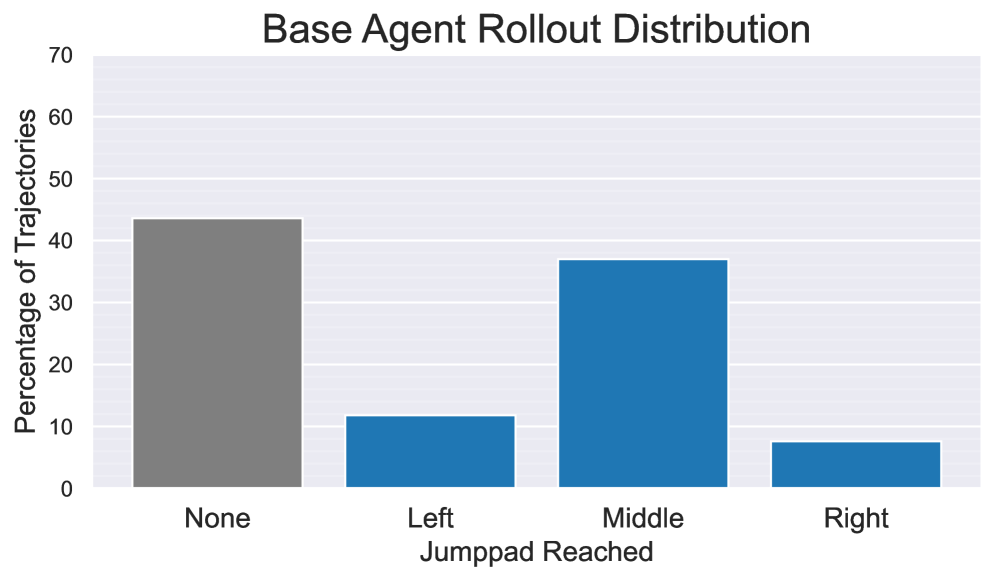
📊 实验亮点
论文通过概念验证实验,展示了将LLM训练流程应用于3D游戏环境智能体的可行性。实验结果表明,使用该方法训练的智能体能够学习到一些基本的导航和交互行为。虽然实验结果还比较初步,但证明了该方法具有潜力,为未来的研究奠定了基础。未来的工作将集中在扩大数据规模、改进训练算法和探索更复杂的任务上。
🎯 应用场景
该研究成果可应用于视频游戏、机器人、自动驾驶等领域。在视频游戏中,可以开发出更智能、更逼真的NPC。在机器人领域,可以训练出能够在复杂环境中执行任务的机器人。在自动驾驶领域,可以提高自动驾驶系统的安全性和可靠性。该研究为开发更通用、更智能的智能体提供了新的思路。
📄 摘要(原文)
Training agents to act competently in complex 3D environments from high-dimensional visual information is challenging. Reinforcement learning is conventionally used to train such agents, but requires a carefully designed reward function, and is difficult to scale to obtain robust agents that generalize to new tasks. In contrast, Large Language Models (LLMs) demonstrate impressively general capabilities resulting from large-scale pre-training and post-training alignment, but struggle to act in complex environments. This position paper draws explicit analogies between decision-making agents and LLMs, and argues that agents should be trained like LLMs to achieve more general, robust, and aligned behaviors. We provide a proof-of-concept to demonstrate how the procedure for training LLMs can be used to train an agent in a 3D video game environment from pixels. We investigate the importance of each stage of the LLM training pipeline, while providing guidance and insights for successfully applying this approach to agents. Our paper provides an alternative perspective to contemporary LLM Agents on how recent progress in LLMs can be leveraged for decision-making agents, and we hope will illuminate a path towards developing more generally capable agents for video games and beyond. Project summary and videos: https://adamjelley.github.io/aligning-agents-like-llms .