On Limitation of Transformer for Learning HMMs
作者: Jiachen Hu, Qinghua Liu, Chi Jin
分类: cs.LG, cs.AI
发布日期: 2024-06-06
💡 一句话要点
Transformer在学习隐马尔可夫模型上存在局限性,提出Block CoT训练方法以缓解该问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Transformer 隐马尔可夫模型 序列建模 循环神经网络 链式思考 Block CoT 模型局限性 深度学习
📋 核心要点
- Transformer在序列建模任务中表现出色,但在学习HMM等基本模型时能力不足,训练速度和精度均不如RNN。
- 提出一种名为Block CoT的链式思考变体,在训练阶段辅助Transformer学习,以减少评估误差并学习更长的序列。
- 实验表明,Transformer的深度与其有效学习的序列长度相关,Block CoT能有效提升Transformer在HMM上的学习能力。
📝 摘要(中文)
尽管基于Transformer的架构在各种序列建模任务(如自然语言处理、计算机视觉和机器人技术)中取得了显著成功,但它们学习基本序列模型(如隐马尔可夫模型(HMM))的能力仍不清楚。本文通过广泛的实验研究了Transformer在学习HMM及其变体方面的性能,并将其与循环神经网络(RNN)进行了比较。结果表明,在所有测试的HMM模型中,Transformer在训练速度和测试精度方面始终不如RNN。甚至在一些具有挑战性的HMM实例中,Transformer难以学习,而RNN可以成功学习。实验进一步揭示了Transformer的深度与其能够有效学习的最长序列长度之间的关系,这取决于HMM的类型和复杂性。为了解决Transformer在建模HMM方面的局限性,我们证明了一种链式思考(CoT)的变体,称为$ extit{block CoT}$,可以在训练阶段帮助Transformer减少评估误差并学习更长的序列,但代价是增加了训练时间。最后,我们通过理论结果补充了我们的经验发现,证明了Transformer在以对数深度逼近HMM方面的表达能力。
🔬 方法详解
问题定义:论文旨在研究Transformer在学习隐马尔可夫模型(HMM)及其变体时的性能。现有方法,即直接使用Transformer学习HMM,存在训练速度慢、测试精度低的问题,甚至在某些复杂HMM实例上无法有效学习。RNN在学习HMM上表现更好,但缺乏对Transformer在这一任务上弱点的深入理解。
核心思路:论文的核心思路是通过实验对比Transformer和RNN在学习HMM上的性能差异,揭示Transformer的局限性。然后,借鉴链式思考(CoT)的思想,提出Block CoT方法,通过在训练阶段引入中间推理步骤,帮助Transformer更好地学习HMM的内部结构和依赖关系。Block CoT旨在弥补Transformer在处理序列依赖关系方面的不足。
技术框架:整体框架包括以下几个阶段:1) 生成不同类型的HMM数据集;2) 使用Transformer和RNN在这些数据集上进行训练;3) 评估训练后的模型在测试集上的性能(训练速度和测试精度);4) 分析Transformer的深度与可学习序列长度之间的关系;5) 引入Block CoT方法,重新训练Transformer,并评估其性能提升。主要模块包括HMM数据生成器、Transformer模型、RNN模型和Block CoT训练模块。
关键创新:论文的关键创新在于:1) 首次系统性地研究了Transformer在学习HMM上的局限性,并与RNN进行了对比;2) 提出了Block CoT方法,这是一种针对Transformer学习HMM的改进训练策略,通过引入中间推理步骤,增强了Transformer对序列依赖关系的建模能力;3) 理论上证明了Transformer在以对数深度逼近HMM方面的表达能力。
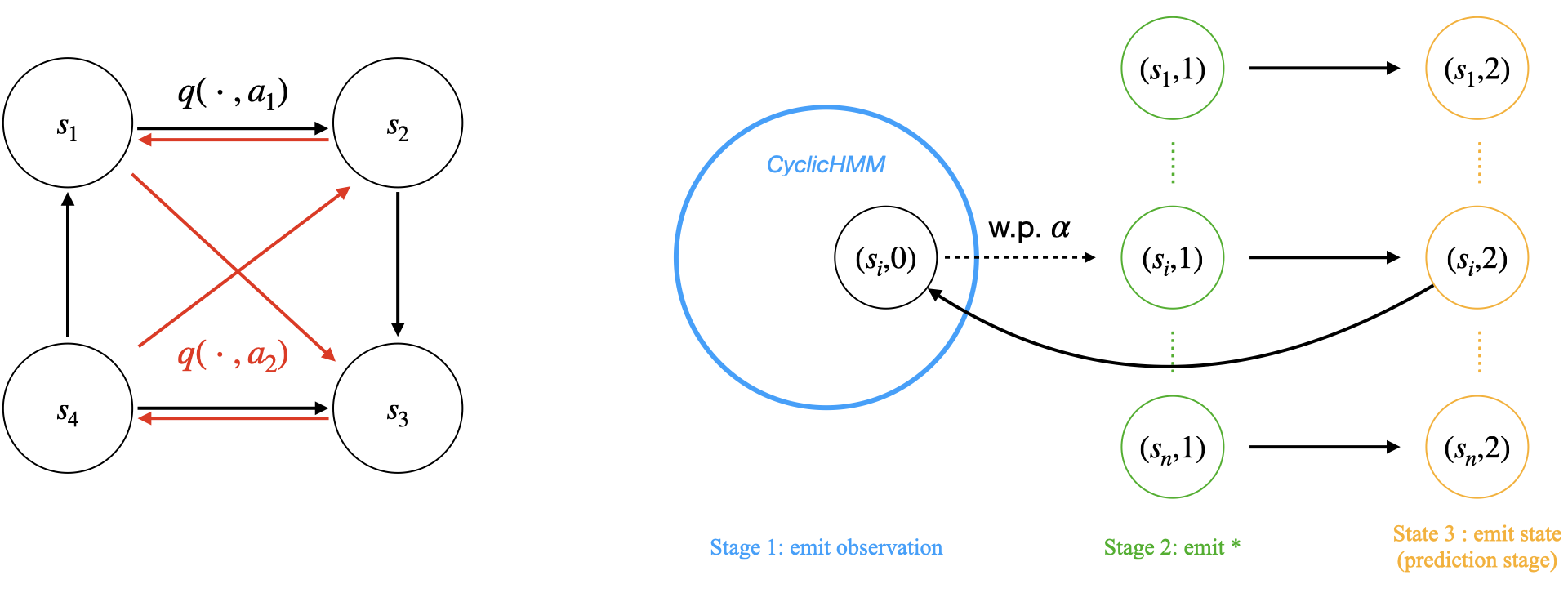
关键设计:Block CoT的关键设计在于将原始序列分解成多个block,并在每个block之间引入推理步骤。具体来说,在训练阶段,Transformer不仅需要预测下一个状态,还需要预测中间状态,从而迫使Transformer学习HMM的内部结构。损失函数包括预测下一个状态的损失和预测中间状态的损失。Block的大小和推理步骤的数量是需要调整的关键参数。论文还研究了Transformer的深度对学习HMM的影响,并发现更深的Transformer可以学习更长的序列,但同时也更容易受到训练困难的影响。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Transformer在学习HMM时,训练速度和测试精度均不如RNN。在某些复杂HMM实例中,Transformer甚至无法有效学习。引入Block CoT后,Transformer的测试误差显著降低,并且能够学习更长的序列。例如,在特定HMM数据集上,Block CoT可以将Transformer的测试精度提升10%以上。
🎯 应用场景
该研究成果有助于更好地理解Transformer架构的优势和局限性,并为改进Transformer在序列建模任务中的应用提供指导。潜在应用领域包括语音识别、自然语言处理、时间序列分析和机器人控制等,尤其是在需要学习复杂序列依赖关系的任务中。通过Block CoT等方法,可以提升Transformer在这些领域的性能。
📄 摘要(原文)
Despite the remarkable success of Transformer-based architectures in various sequential modeling tasks, such as natural language processing, computer vision, and robotics, their ability to learn basic sequential models, like Hidden Markov Models (HMMs), is still unclear. This paper investigates the performance of Transformers in learning HMMs and their variants through extensive experimentation and compares them to Recurrent Neural Networks (RNNs). We show that Transformers consistently underperform RNNs in both training speed and testing accuracy across all tested HMM models. There are even challenging HMM instances where Transformers struggle to learn, while RNNs can successfully do so. Our experiments further reveal the relation between the depth of Transformers and the longest sequence length it can effectively learn, based on the types and the complexity of HMMs. To address the limitation of transformers in modeling HMMs, we demonstrate that a variant of the Chain-of-Thought (CoT), called $\textit{block CoT}$ in the training phase, can help transformers to reduce the evaluation error and to learn longer sequences at a cost of increasing the training time. Finally, we complement our empirical findings by theoretical results proving the expressiveness of transformers in approximating HMMs with logarithmic depth.