Transductive Off-policy Proximal Policy Optimization
作者: Yaozhong Gan, Renye Yan, Xiaoyang Tan, Zhe Wu, Junliang Xing
分类: cs.LG
发布日期: 2024-06-06
备注: 18
💡 一句话要点
提出Transductive Off-policy PPO (ToPPO),提升PPO算法的离线数据利用率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 离线策略学习 近端策略优化 重要性采样 策略优化
📋 核心要点
- PPO算法作为一种在线策略强化学习方法,难以有效利用来自不同策略的离线数据。
- ToPPO通过理论推导,为PPO算法引入离线数据,并提出了单调改进的优化机制。
- 在多个任务上的实验表明,ToPPO能够有效利用离线数据,提升PPO算法的性能。
📝 摘要(中文)
近端策略优化(PPO)是一种流行的无模型强化学习算法,以其简单性和有效性而备受推崇。然而,由于其固有的在线策略特性,它在利用来自不同策略的数据方面的能力受到限制。本文提出了一种新的PPO离线策略扩展方法,命名为Transductive Off-policy PPO (ToPPO)。本文为在PPO训练中结合离线策略数据提供了理论依据,并为安全应用提供了谨慎的指导。我们的贡献包括为从离线策略数据导出的前瞻性策略提出的策略改进下界的新的公式,以及一种计算效率高的机制来优化这个下界,并保证单调改进。在六个代表性任务上的综合实验结果突出了ToPPO的有希望的性能。
🔬 方法详解
问题定义:PPO算法是一种on-policy算法,其样本效率受限于只能使用当前策略产生的数据。在许多实际场景中,存在大量的历史数据或来自其他策略的数据,如何有效利用这些off-policy数据来提升PPO算法的性能是一个重要的问题。现有的off-policy算法通常比较复杂,且难以保证策略的单调改进。
核心思路:ToPPO的核心思路是推导出一个适用于off-policy数据的策略改进下界,并设计一种计算高效的优化方法来最大化这个下界。通过引入重要性采样和合适的约束,保证策略在更新过程中能够单调改进,避免性能下降。
技术框架:ToPPO的整体框架与PPO类似,主要区别在于策略更新阶段。ToPPO首先利用off-policy数据计算重要性采样权重,然后基于这些权重构建策略改进的下界。接着,通过优化这个下界来更新策略,同时施加KL散度约束,防止策略更新幅度过大。最后,使用更新后的策略与环境交互,收集新的数据用于下一轮的训练。
关键创新:ToPPO的关键创新在于提出了一个适用于off-policy数据的策略改进下界,并证明了优化这个下界可以保证策略的单调改进。此外,ToPPO还设计了一种计算高效的优化方法,使得算法能够快速收敛。与传统的off-policy算法相比,ToPPO更加简单易用,且能够更好地保证策略的稳定性。
关键设计:ToPPO的关键设计包括:1) 使用重要性采样来校正off-policy数据带来的偏差;2) 引入KL散度约束来限制策略更新的幅度;3) 设计了一种计算高效的优化方法来最大化策略改进下界。损失函数主要由三部分组成:策略梯度项、KL散度惩罚项和值函数误差项。网络结构与原始PPO保持一致,可以使用多层感知机或卷积神经网络。
🖼️ 关键图片

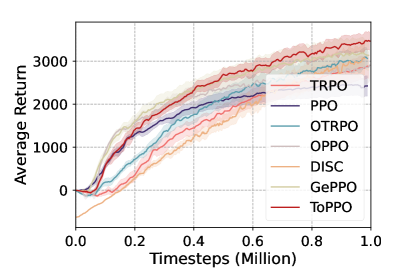

📊 实验亮点
实验结果表明,ToPPO在六个代表性任务上都取得了显著的性能提升。与原始PPO算法相比,ToPPO能够更快地收敛,并达到更高的奖励。在某些任务上,ToPPO的性能甚至超过了其他先进的off-policy算法。这些结果验证了ToPPO算法的有效性和优越性。
🎯 应用场景
ToPPO算法可以应用于各种需要利用离线数据的强化学习场景,例如机器人控制、游戏AI、自动驾驶等。通过利用历史数据或专家经验,ToPPO可以加速算法的训练过程,并提升最终的性能。此外,ToPPO还可以用于策略迁移学习,将一个任务上训练好的策略迁移到另一个相关任务上,从而减少在新任务上的训练时间。
📄 摘要(原文)
Proximal Policy Optimization (PPO) is a popular model-free reinforcement learning algorithm, esteemed for its simplicity and efficacy. However, due to its inherent on-policy nature, its proficiency in harnessing data from disparate policies is constrained. This paper introduces a novel off-policy extension to the original PPO method, christened Transductive Off-policy PPO (ToPPO). Herein, we provide theoretical justification for incorporating off-policy data in PPO training and prudent guidelines for its safe application. Our contribution includes a novel formulation of the policy improvement lower bound for prospective policies derived from off-policy data, accompanied by a computationally efficient mechanism to optimize this bound, underpinned by assurances of monotonic improvement. Comprehensive experimental results across six representative tasks underscore ToPPO's promising performance.