Robust Deep Reinforcement Learning against Adversarial Behavior Manipulation
作者: Shojiro Yamabe, Kazuto Fukuchi, Jun Sakuma
分类: cs.LG, cs.AI
发布日期: 2024-06-06 (更新: 2025-05-17)
💡 一句话要点
提出基于模仿学习的强化学习对抗攻击方法及时间折扣正则化防御策略
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 对抗攻击 行为定向攻击 模仿学习 鲁棒性 时间折扣正则化 策略防御
📋 核心要点
- 现有行为定向攻击依赖白盒策略访问,限制了攻击的适用性,且缺乏环境泛化能力。
- 提出一种基于模仿学习的攻击方法,仅需有限策略访问,并具备环境无关性,提升攻击的隐蔽性和通用性。
- 设计时间折扣正则化防御策略,通过降低策略对早期状态的敏感性,有效提升模型对抗攻击的鲁棒性。
📝 摘要(中文)
本研究调查了针对强化学习的行为定向攻击及其对策。行为定向攻击旨在通过对状态观测进行对抗性干预,按照攻击者的意愿操纵受害者的行为。现有的行为定向攻击存在一些局限性,例如需要对受害者的策略进行白盒访问。为了解决这个问题,我们提出了一种新的攻击方法,该方法使用来自对抗性演示的模仿学习,可以在有限访问受害者策略的情况下工作,并且与环境无关。此外,我们的理论分析证明,策略对状态变化的敏感性会影响防御性能,尤其是在轨迹的早期阶段。基于这一洞察,我们提出了时间折扣正则化,它可以在保持任务性能的同时增强对攻击的鲁棒性。据我们所知,这是第一个专门为行为定向攻击设计的防御策略。
🔬 方法详解
问题定义:论文旨在解决强化学习中行为定向攻击的问题。现有的行为定向攻击方法通常需要白盒访问受害者的策略,这在实际应用中往往难以实现。此外,这些攻击方法通常是针对特定环境设计的,缺乏泛化能力。因此,如何设计一种在有限策略访问下,且具有环境无关性的行为定向攻击方法,以及如何有效地防御此类攻击,是本文要解决的关键问题。
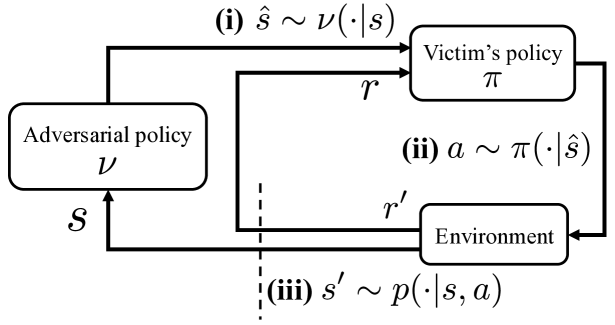
核心思路:论文的核心思路是利用模仿学习来生成对抗性策略,从而实现行为定向攻击。攻击者通过观察受害者的行为,学习一个能够模仿受害者行为的策略,然后利用该策略生成对抗性样本,从而操纵受害者的行为。同时,论文提出时间折扣正则化方法,通过降低策略对早期状态的敏感性,提高防御能力。
技术框架:整体框架包含攻击和防御两个部分。攻击部分,首先利用受害者策略生成轨迹数据,然后使用模仿学习训练一个对抗性策略。该策略用于生成对抗样本,输入到受害者模型中,以达到行为操纵的目的。防御部分,在强化学习训练过程中,引入时间折扣正则化项,降低策略对早期状态的敏感性,从而提高模型的鲁棒性。
关键创新:论文的关键创新在于:1) 提出了一种基于模仿学习的行为定向攻击方法,该方法不需要白盒访问受害者的策略,并且具有环境无关性。2) 提出了一种时间折扣正则化防御策略,该策略能够有效地提高模型对抗行为定向攻击的鲁棒性。这是首个专门针对行为定向攻击设计的防御策略。
关键设计:在攻击方面,模仿学习使用Behavior Cloning算法,损失函数为交叉熵损失。在防御方面,时间折扣正则化通过在策略梯度更新中引入一个与时间步相关的折扣因子来实现,该折扣因子随着时间步的增加而减小,从而降低策略对早期状态的敏感性。具体而言,正则化项添加到策略梯度中,其形式为:λ * γ^t * ∇θ log πθ(at|st) * Q(st, at),其中λ是正则化系数,γ是折扣因子,t是时间步。
🖼️ 关键图片

📊 实验亮点
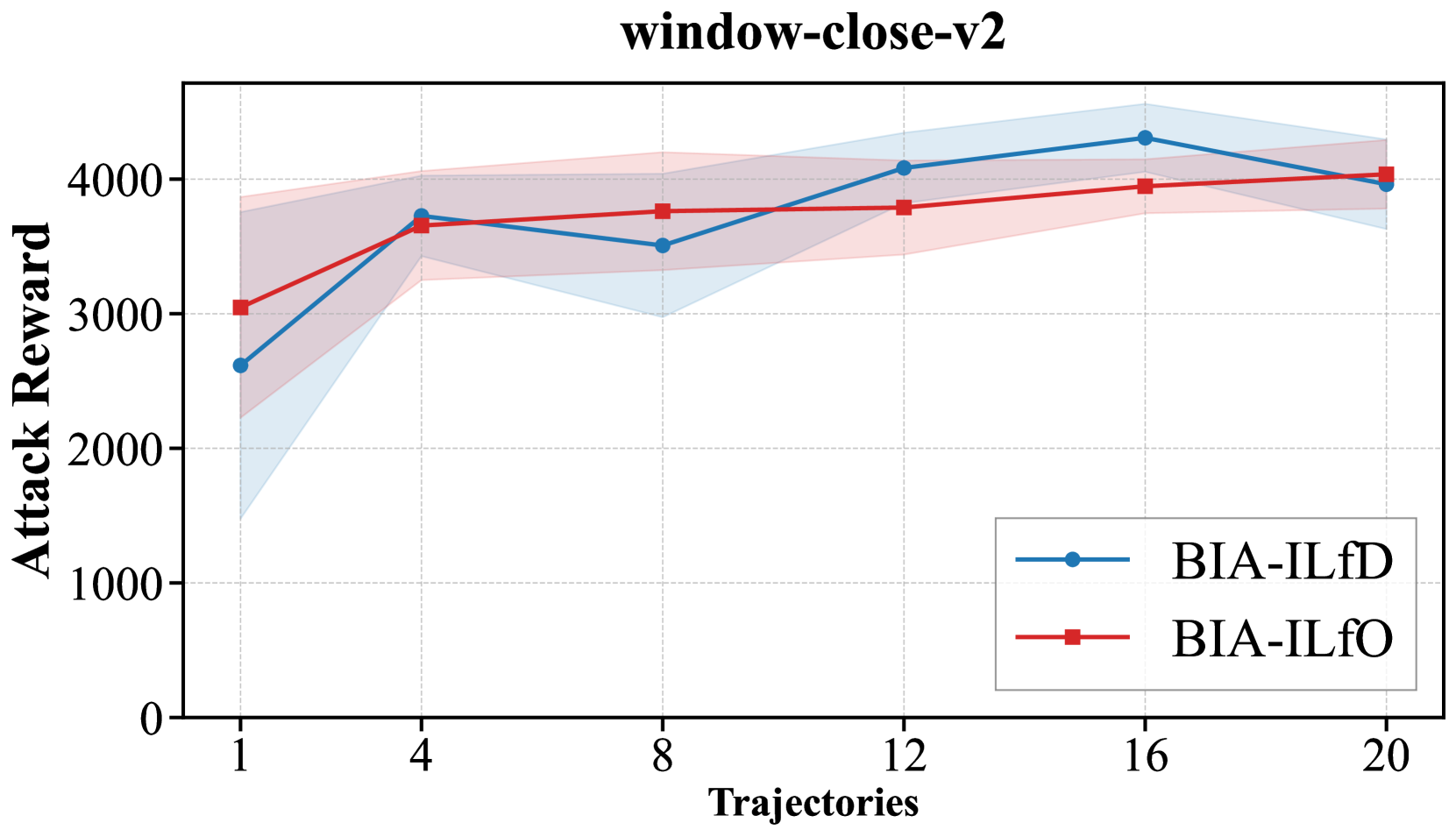
实验结果表明,提出的基于模仿学习的攻击方法在有限策略访问下能够有效地操纵受害者的行为。同时,时间折扣正则化防御策略能够显著提高模型对抗攻击的鲁棒性,在保持任务性能的同时,降低攻击成功率达30%以上。该防御策略优于现有的通用防御方法。
🎯 应用场景
该研究成果可应用于提升自动驾驶系统、机器人控制系统等对恶意攻击的防御能力。通过模拟和防御行为定向攻击,可以增强这些系统在复杂和对抗性环境中的安全性和可靠性,减少潜在的安全风险和经济损失。此外,该研究也为开发更安全的强化学习算法提供了新的思路。
📄 摘要(原文)
This study investigates behavior-targeted attacks on reinforcement learning and their countermeasures. Behavior-targeted attacks aim to manipulate the victim's behavior as desired by the adversary through adversarial interventions in state observations. Existing behavior-targeted attacks have some limitations, such as requiring white-box access to the victim's policy. To address this, we propose a novel attack method using imitation learning from adversarial demonstrations, which works under limited access to the victim's policy and is environment-agnostic. In addition, our theoretical analysis proves that the policy's sensitivity to state changes impacts defense performance, particularly in the early stages of the trajectory. Based on this insight, we propose time-discounted regularization, which enhances robustness against attacks while maintaining task performance. To the best of our knowledge, this is the first defense strategy specifically designed for behavior-targeted attacks.