MuJo: Multimodal Joint Feature Space Learning for Human Activity Recognition
作者: Stefan Gerd Fritsch, Cennet Oguz, Vitor Fortes Rey, Lala Ray, Maximilian Kiefer-Emmanouilidis, Paul Lukowicz
分类: cs.LG, cs.CL, cs.CV
发布日期: 2024-06-06 (更新: 2025-02-06)
💡 一句话要点
提出MuJo多模态联合特征空间学习方法,提升人体活动识别在多种模态下的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人体活动识别 多模态学习 联合特征空间 预训练 自监督学习 可穿戴传感器 健身活动识别
📋 核心要点
- 现有HAR方法依赖高质量数据,但在可穿戴传感器等模态下,数据质量和标注成本成为瓶颈。
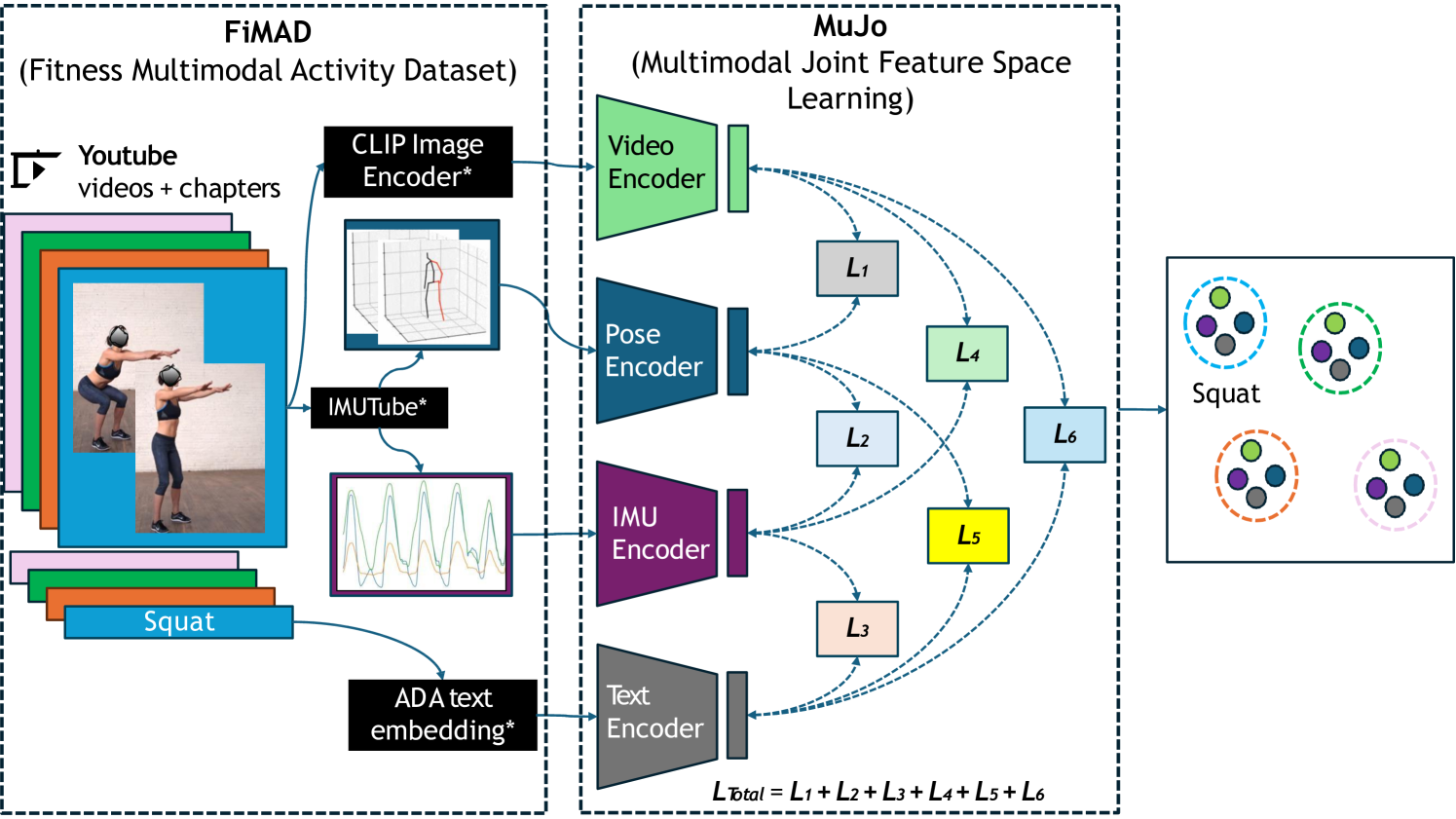
- MuJo通过FiMAD数据集学习多模态联合特征空间,利用视频、语言、姿势和模拟IMU数据进行预训练。
- 实验表明,MuJo在真实HAR数据集上显著提升性能,例如在MM-Fit上,使用少量数据微调即可达到高F1分数。
📝 摘要(中文)
人体活动识别(HAR)是人工智能领域一个长期存在的问题,在医疗保健、体育健身、安全等领域有着广泛的应用。HAR在现实环境中的性能很大程度上取决于输入信号的类型和质量。在场景具有清晰、高质量的摄像头视角的情况下,计算机视觉系统,特别是与基础模型结合使用时,如今可以相当可靠地区分复杂的活动。另一方面,使用可穿戴传感器等模态进行识别(这些模态通常更广泛地可用,例如在手机和智能手表中)是一个更困难的问题,因为信号通常包含较少的信息,并且标记的训练数据更难获取。为了减轻对标记数据的需求,我们在这项工作中介绍了我们全面的健身多模态活动数据集(FiMAD),该数据集可以与所提出的预训练方法MuJo(多模态联合特征空间学习)一起使用,以提高各种模态的HAR性能。FiMAD是使用YouTube健身视频创建的,包含并行视频、语言、姿势和模拟IMU传感器数据。MuJo利用此数据集来学习这些模态的联合特征空间。我们表明,在FiMAD上预训练的分类器可以提高真实HAR数据集(如MM-Fit、MyoGym、MotionSense和MHEALTH)的性能。例如,在MM-Fit上,当仅在2%的训练数据上进行微调时,我们实现了高达0.855的Macro F1-Score,而当利用完整的训练集进行分类任务时,则实现了0.942。我们将我们的方法与其他自监督方法进行了比较,结果表明,与它们不同,我们的方法始终优于基线网络性能,同时还提供了更好的数据效率。
🔬 方法详解
问题定义:论文旨在解决人体活动识别中,当输入模态受限(如仅有可穿戴传感器数据)或标注数据不足时,识别精度低的问题。现有方法在处理低质量或缺乏标注的数据时表现不佳,限制了HAR在实际场景中的应用。
核心思路:论文的核心思路是利用多模态数据(视频、语言、姿势、IMU)构建一个联合特征空间,通过预训练的方式学习不同模态之间的关联性。这样,即使在目标任务中只使用单一模态(如IMU),也能利用预训练学到的知识提升识别性能。
技术框架:MuJo的整体框架包含以下几个主要阶段:1) 构建FiMAD数据集,包含同步的视频、语言、姿势和模拟IMU数据;2) 使用FiMAD数据集进行多模态联合特征空间学习,训练MuJo模型;3) 在目标HAR数据集上进行微调,利用预训练的MuJo模型初始化分类器;4) 评估微调后的分类器在目标数据集上的性能。
关键创新:MuJo的关键创新在于它利用大规模多模态数据集FiMAD,通过预训练学习了一个通用的、模态无关的特征表示。这种方法能够有效地利用不同模态之间的互补信息,从而提升在单一模态下的HAR性能。与传统的自监督学习方法相比,MuJo更注重多模态之间的关联性学习。
关键设计:FiMAD数据集是MuJo方法的基础,包含了从YouTube健身视频中提取的多种模态数据。MuJo模型可能采用对比学习或类似的方法,通过最小化不同模态下相同活动的特征表示之间的距离,来学习联合特征空间。具体的损失函数和网络结构细节在论文中可能有所描述,但根据摘要信息无法确定。
🖼️ 关键图片


📊 实验亮点
MuJo在MM-Fit数据集上表现出色,仅使用2%的训练数据进行微调,Macro F1-Score达到0.855,使用完整训练集时更是达到0.942。与其他自监督学习方法相比,MuJo在提升性能和数据效率方面均表现更优,证明了其在多模态HAR任务中的有效性。
🎯 应用场景
该研究成果可广泛应用于智能穿戴设备、智能家居、运动健康监测等领域。通过提升在低质量传感器数据下的活动识别精度,可以实现更精准的健康管理、跌倒检测、运动指导等功能。未来,该方法有望扩展到其他需要多模态信息融合的场景,例如机器人导航、人机交互等。
📄 摘要(原文)
Human activity recognition (HAR) is a long-standing problem in artificial intelligence with applications in a broad range of areas, including healthcare, sports and fitness, security, and more. The performance of HAR in real-world settings is strongly dependent on the type and quality of the input signal that can be acquired. Given an unobstructed, high-quality camera view of a scene, computer vision systems, in particular in conjunction with foundation models, can today fairly reliably distinguish complex activities. On the other hand, recognition using modalities such as wearable sensors (which are often more broadly available, e.g., in mobile phones and smartwatches) is a more difficult problem, as the signals often contain less information and labeled training data is more difficult to acquire. To alleviate the need for labeled data, we introduce our comprehensive Fitness Multimodal Activity Dataset (FiMAD) in this work, which can be used with the proposed pre-training method MuJo (Multimodal Joint Feature Space Learning) to enhance HAR performance across various modalities. FiMAD was created using YouTube fitness videos and contains parallel video, language, pose, and simulated IMU sensor data. MuJo utilizes this dataset to learn a joint feature space for these modalities. We show that classifiers pre-trained on FiMAD can increase the performance on real HAR datasets such as MM-Fit, MyoGym, MotionSense, and MHEALTH. For instance, on MM-Fit, we achieve a Macro F1-Score of up to 0.855 when fine-tuning on only 2% of the training data and 0.942 when utilizing the complete training set for classification tasks. We compare our approach with other self-supervised ones and show that, unlike them, ours consistently improves compared to the baseline network performance while also providing better data efficiency.