PrE-Text: Training Language Models on Private Federated Data in the Age of LLMs
作者: Charlie Hou, Akshat Shrivastava, Hongyuan Zhan, Rylan Conway, Trang Le, Adithya Sagar, Giulia Fanti, Daniel Lazar
分类: cs.LG, cs.AI, cs.CL, cs.CR, cs.DC
发布日期: 2024-06-05 (更新: 2024-10-17)
备注: ICML 2024 (Oral). Latest revision corrects a discussion on concurrent work arXiv:2403.01749. We described their work as reliant on using closed-sourced models when in reality they also evaluate and use open source models. This has been corrected in this version
🔗 代码/项目: GITHUB
💡 一句话要点
PrE-Text:一种在联邦学习中利用差分隐私合成数据训练LLM的方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 差分隐私 合成数据 大型语言模型 隐私保护 设备端训练
📋 核心要点
- 设备端训练存在设备算力限制、通信开销大和调试困难等问题,难以直接应用于大型语言模型。
- PrE-Text通过生成差分隐私的合成文本数据,避免了直接在用户设备上训练模型,降低了计算和通信成本。
- 实验表明,使用PrE-Text训练的模型在性能和效率上均优于设备端训练,尤其是在隐私保护要求下。
📝 摘要(中文)
本文提出了一种名为Private Evolution-Text (PrE-Text) 的方法,用于生成差分隐私 (DP) 的合成文本数据,以解决在私有联邦数据上训练大型语言模型 (LLM) 的难题。传统的设备端训练存在诸多问题,包括设备算力不足、通信和计算开销大、以及调试部署困难。实验结果表明,在多个数据集上,使用PrE-Text生成的合成数据训练小型模型,在实际隐私预算下(ε=1.29,ε=7.58)优于在设备端训练的小型模型,同时减少了9倍的训练轮数、6倍的客户端计算量和100倍的通信量。此外,在PrE-Text的DP合成数据上微调大型模型,也能在相同的隐私预算范围内提高LLM在私有数据上的性能。这些结果表明,基于DP合成数据进行训练可能比直接在设备端训练模型更有效。
🔬 方法详解
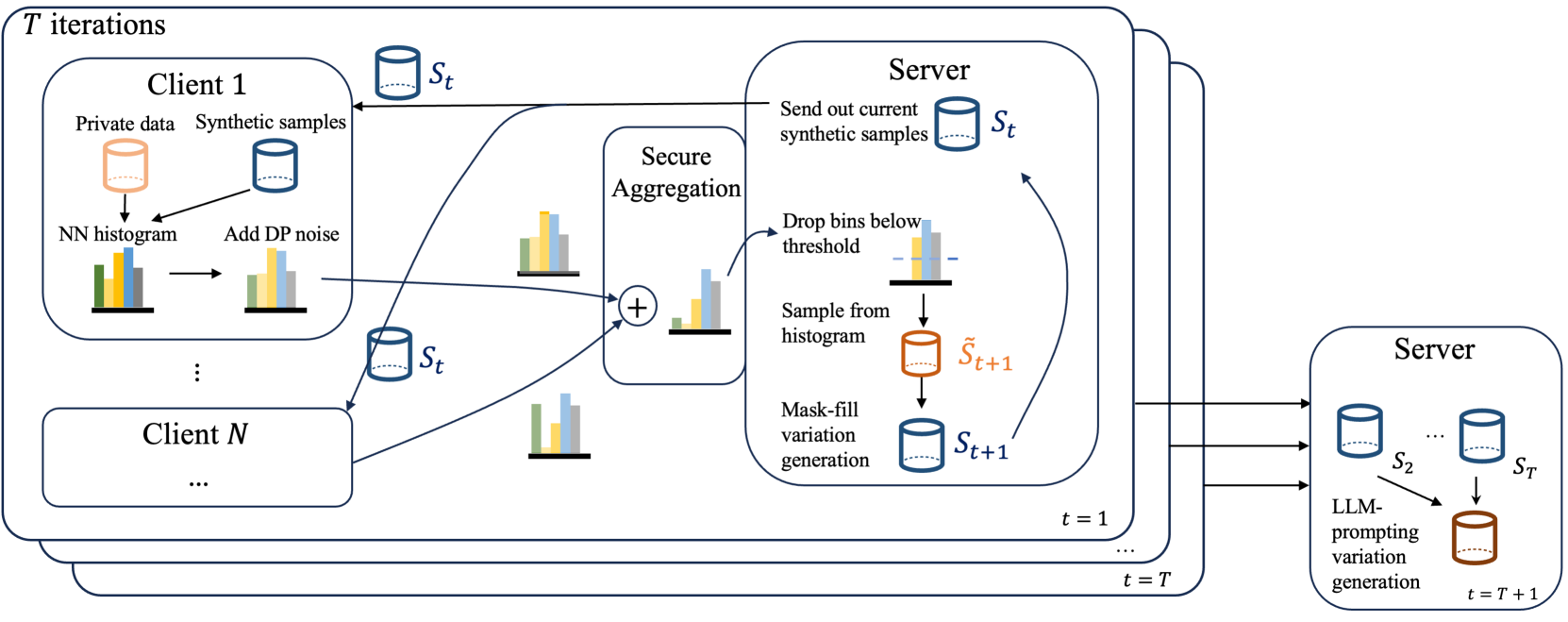
问题定义:论文旨在解决在保护用户隐私的前提下,如何高效地利用联邦数据训练大型语言模型的问题。传统的设备端训练方法受限于用户设备的计算能力和通信带宽,难以训练大型模型,并且调试和部署也较为困难。
核心思路:论文的核心思路是利用差分隐私技术生成合成数据,然后在合成数据上训练模型。这样既可以保护用户隐私,又可以避免直接在用户设备上进行计算,从而降低了计算和通信成本。
技术框架:PrE-Text 的整体框架包含以下几个阶段:1) 使用联邦数据训练一个小的生成模型;2) 使用差分隐私机制对生成模型进行扰动,以保护用户隐私;3) 使用扰动后的生成模型生成合成数据;4) 在合成数据上训练目标模型(可以是小型模型或大型语言模型)。
关键创新:该方法最重要的创新点在于利用差分隐私技术生成合成数据,从而实现了在保护用户隐私的前提下,高效地利用联邦数据训练模型。与传统的设备端训练方法相比,该方法降低了计算和通信成本,并且更容易调试和部署。
关键设计:论文中没有详细描述生成模型的具体结构和训练方法,以及差分隐私机制的具体实现细节。这些细节可能需要参考相关的差分隐私文献。
🖼️ 关键图片

📊 实验亮点
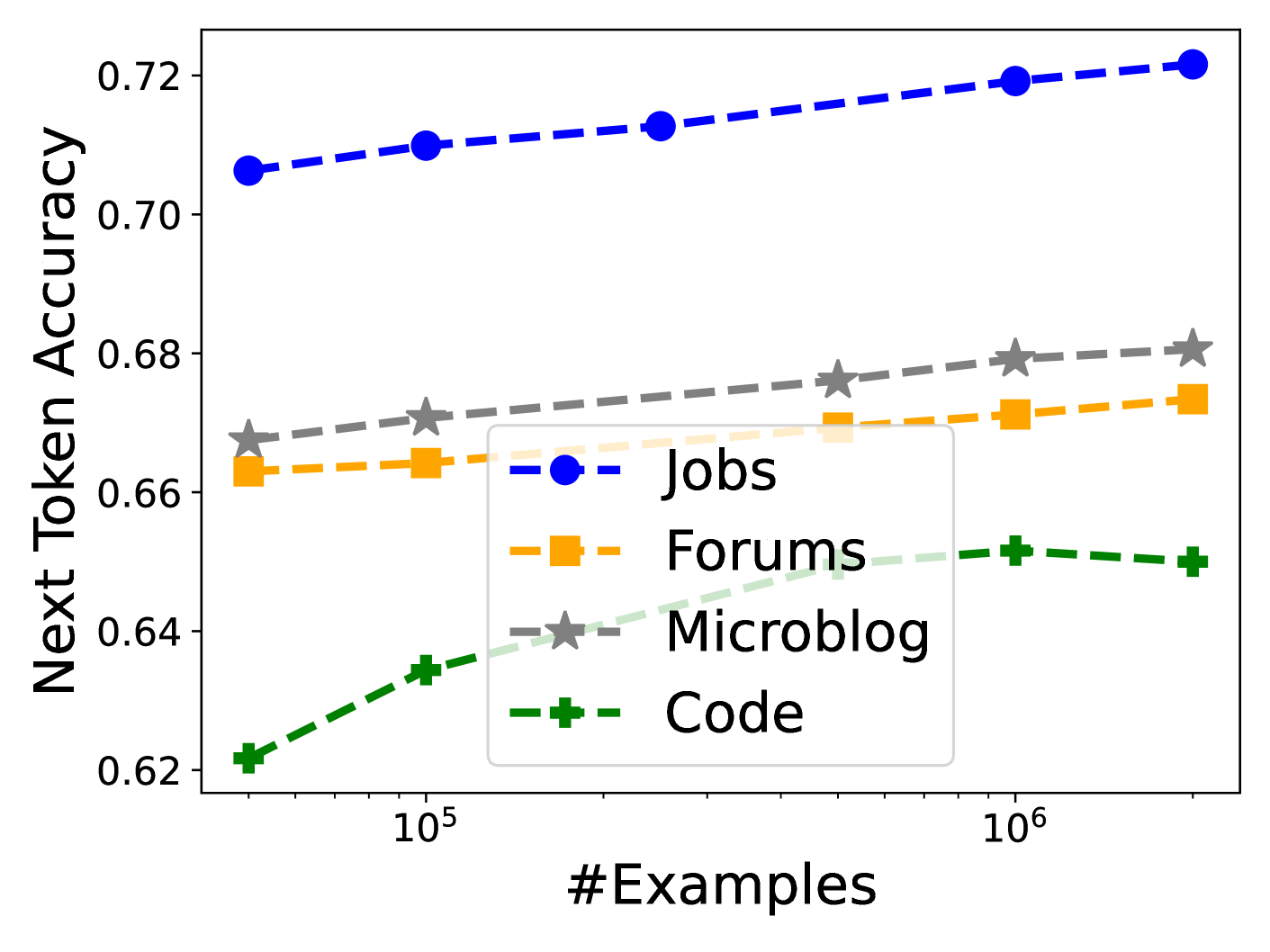
实验结果表明,在实际隐私预算下(ε=1.29,ε=7.58),使用PrE-Text生成的合成数据训练小型模型,优于在设备端训练的小型模型。同时,PrE-Text减少了9倍的训练轮数、6倍的客户端计算量和100倍的通信量。此外,在PrE-Text的DP合成数据上微调大型模型,也能在相同的隐私预算范围内提高LLM在私有数据上的性能。
🎯 应用场景
PrE-Text 方法可应用于各种需要保护用户隐私的场景,例如医疗健康、金融服务和个性化推荐等。通过生成差分隐私的合成数据,可以在不泄露用户隐私的前提下,训练出高性能的模型,从而为用户提供更好的服务。该方法还有助于推动联邦学习技术在实际应用中的落地。
📄 摘要(原文)
On-device training is currently the most common approach for training machine learning (ML) models on private, distributed user data. Despite this, on-device training has several drawbacks: (1) most user devices are too small to train large models on-device, (2) on-device training is communication- and computation-intensive, and (3) on-device training can be difficult to debug and deploy. To address these problems, we propose Private Evolution-Text (PrE-Text), a method for generating differentially private (DP) synthetic textual data. First, we show that across multiple datasets, training small models (models that fit on user devices) with PrE-Text synthetic data outperforms small models trained on-device under practical privacy regimes ($ε=1.29$, $ε=7.58$). We achieve these results while using 9$\times$ fewer rounds, 6$\times$ less client computation per round, and 100$\times$ less communication per round. Second, finetuning large models on PrE-Text's DP synthetic data improves large language model (LLM) performance on private data across the same range of privacy budgets. Altogether, these results suggest that training on DP synthetic data can be a better option than training a model on-device on private distributed data. Code is available at https://github.com/houcharlie/PrE-Text.