Scaling Laws for Reward Model Overoptimization in Direct Alignment Algorithms
作者: Rafael Rafailov, Yaswanth Chittepu, Ryan Park, Harshit Sikchi, Joey Hejna, Bradley Knox, Chelsea Finn, Scott Niekum
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-06-05 (更新: 2024-11-05)
备注: 30 pages, 38th Conference on Neural Information Processing Systems (NeurIPS 2024)
💡 一句话要点
揭示直接对齐算法中奖励模型过度优化问题及其规模效应
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 直接对齐算法 奖励模型过度优化 强化学习 大型语言模型 KL散度 人类反馈 模型对齐
📋 核心要点
- 传统RLHF方法存在奖励模型过度优化问题,导致模型在代理奖励上表现提升,但真实性能下降。
- 论文研究直接对齐算法(DAA)中的类似过度优化现象,即使没有显式的奖励模型,DAA仍会退化。
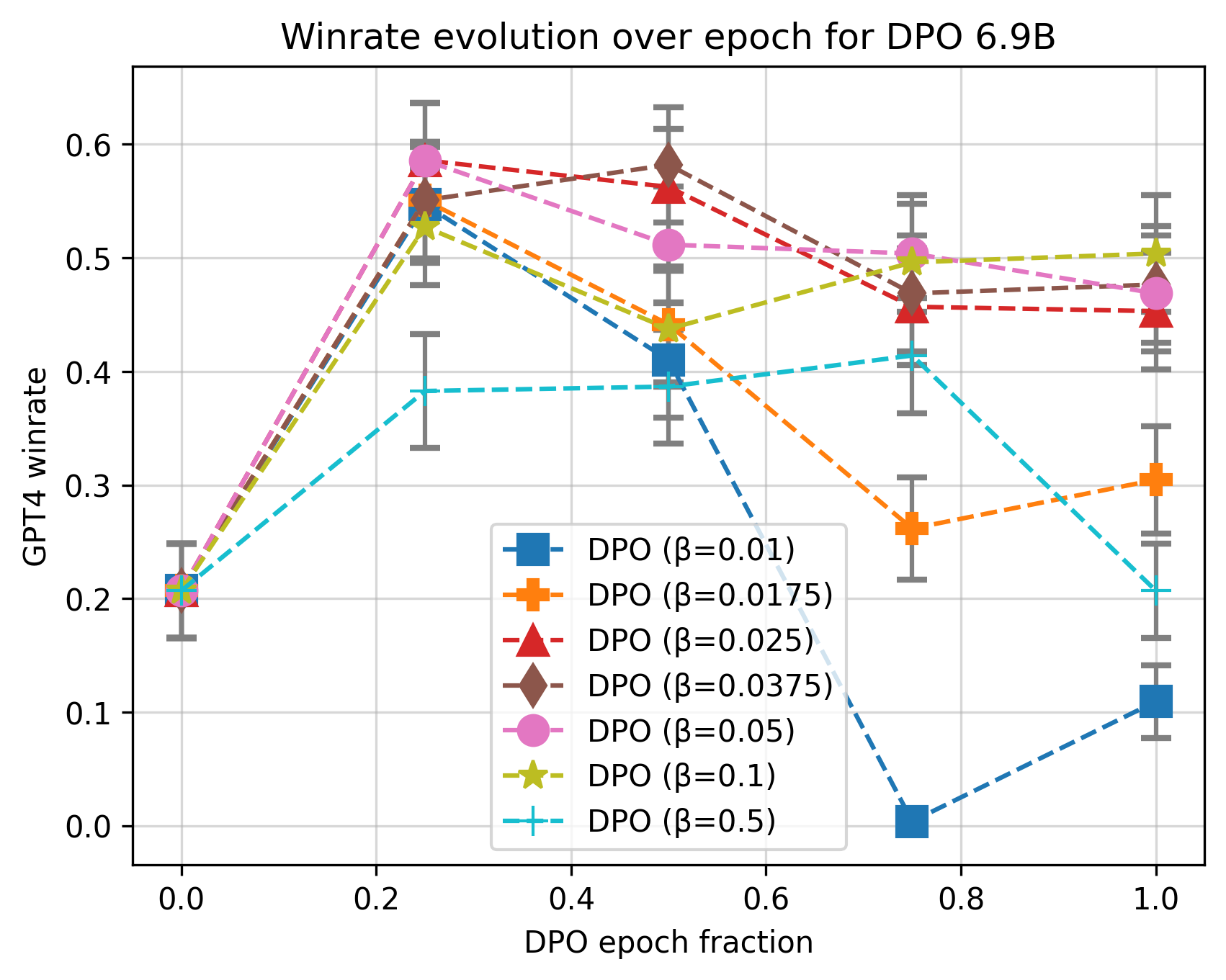
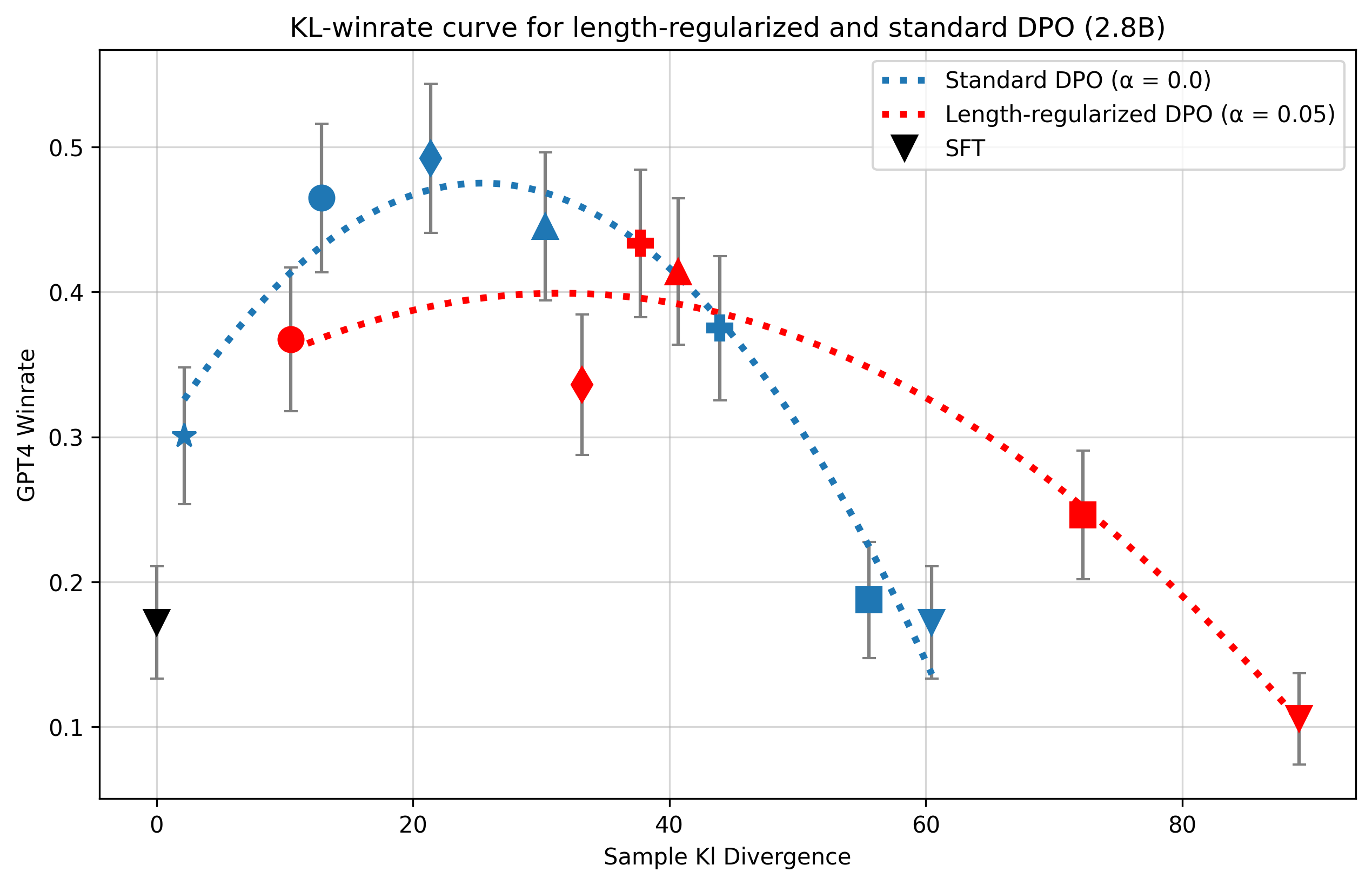
- 实验表明,DAA在不同KL散度约束下,甚至在单轮训练前,就可能出现性能退化,揭示了DAA的脆弱性。
📝 摘要(中文)
通过人类反馈的强化学习(RLHF)对大型语言模型(LLM)的成功至关重要,但它通常是一个复杂且脆弱的过程。在经典的RLHF框架中,首先训练一个奖励模型来表示人类偏好,然后在线强化学习(RL)算法利用该模型来优化LLM。这种方法的一个突出问题是奖励过度优化或奖励入侵,即通过学习到的代理奖励模型衡量的性能有所提高,但真实质量停滞甚至下降。直接对齐算法(DDA),如直接偏好优化,通过绕过奖励建模阶段,成为经典RLHF流程的替代方案。然而,尽管DAA不使用单独的代理奖励模型,但它们仍然经常因过度优化而恶化。虽然所谓的奖励入侵现象对于DAA来说没有明确定义,但我们仍然发现了类似的趋势:在较高的KL预算下,DAA算法表现出与其经典RLHF对应算法相似的退化模式。特别是,我们发现DAA方法不仅在各种KL预算下会恶化,而且通常在完成数据集的单个epoch之前就会恶化。通过广泛的实证实验,这项工作为DAA制定并形式化了奖励过度优化或入侵问题,并探讨了其在目标、训练机制和模型规模上的影响。
🔬 方法详解
问题定义:论文旨在研究直接对齐算法(DAA)中存在的奖励过度优化问题。尽管DAA避免了显式奖励模型的训练,但实验观察表明,DAA仍然会受到过度优化影响,导致模型在训练过程中性能下降。现有方法的痛点在于,对DAA中过度优化现象的理解不足,缺乏对其影响因素的系统性分析。
核心思路:论文的核心思路是,将奖励过度优化问题从经典的RLHF框架扩展到DAA框架,并研究其在不同目标函数、训练机制和模型规模下的表现。通过实证分析,揭示DAA在不同KL散度约束下,以及训练初期就可能出现的性能退化现象。论文旨在形式化DAA中的奖励过度优化问题,并探索其根本原因。
技术框架:论文采用实证研究的方法,通过大量的实验来分析DAA中的奖励过度优化现象。整体流程包括: 1. 选择不同的DAA算法,如Direct Preference Optimization (DPO)。 2. 在不同的数据集和模型规模上进行实验。 3. 使用不同的KL散度约束进行训练。 4. 评估模型在训练过程中的性能,并分析其退化模式。 5. 分析不同因素对过度优化的影响,如目标函数、训练机制和模型规模。
关键创新:论文最重要的技术创新点在于,首次将奖励过度优化问题扩展到DAA框架,并系统性地研究了其影响因素。与现有方法相比,该研究不再局限于经典的RLHF流程,而是关注更直接的对齐算法,从而更深入地理解了语言模型对齐过程中的挑战。
关键设计:论文的关键设计包括: 1. 选择合适的DAA算法,如DPO,作为研究对象。 2. 使用不同的KL散度约束来控制模型的训练过程。 3. 采用多种评估指标来衡量模型的性能,包括奖励模型的预测准确性和生成文本的质量。 4. 设计实验来分析不同因素对过度优化的影响,如目标函数、训练机制和模型规模。
🖼️ 关键图片

📊 实验亮点
实验结果表明,DAA算法在较高的KL散度约束下,会表现出与经典RLHF算法相似的性能退化模式。更重要的是,DAA的性能退化甚至可能在完成数据集的单个epoch之前就发生,这突显了DAA在训练初期对过度优化的敏感性。这些发现对DAA算法的实际应用提出了挑战,并强调了对DAA训练过程进行更精细控制的必要性。
🎯 应用场景
该研究成果可应用于提升大型语言模型的对齐效果,降低模型训练过程中的风险。通过更好地理解和控制DAA中的奖励过度优化现象,可以开发更稳定、可靠的对齐算法,从而提高LLM在实际应用中的性能和安全性。此外,该研究也为未来对齐算法的设计提供了新的思路和方向。
📄 摘要(原文)
Reinforcement Learning from Human Feedback (RLHF) has been crucial to the recent success of Large Language Models (LLMs), however, it is often a complex and brittle process. In the classical RLHF framework, a reward model is first trained to represent human preferences, which is in turn used by an online reinforcement learning (RL) algorithm to optimize the LLM. A prominent issue with such methods is reward over-optimization or reward hacking, where performance as measured by the learned proxy reward model increases, but true quality plateaus or even deteriorates. Direct Alignment Algorithms (DDAs) like Direct Preference Optimization have emerged as alternatives to the classical RLHF pipeline by circumventing the reward modeling phase. However, although DAAs do not use a separate proxy reward model, they still commonly deteriorate from over-optimization. While the so-called reward hacking phenomenon is not well-defined for DAAs, we still uncover similar trends: at higher KL budgets, DAA algorithms exhibit similar degradation patterns to their classic RLHF counterparts. In particular, we find that DAA methods deteriorate not only across a wide range of KL budgets but also often before even a single epoch of the dataset is completed. Through extensive empirical experimentation, this work formulates and formalizes the reward over-optimization or hacking problem for DAAs and explores its consequences across objectives, training regimes, and model scales.