MOSEAC: Streamlined Variable Time Step Reinforcement Learning
作者: Dong Wang, Giovanni Beltrame
分类: cs.LG, cs.RO
发布日期: 2024-06-03
💡 一句话要点
MOSEAC:一种简化的变时间步长强化学习方法,提升控制效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 变时间步长 自适应控制 Actor-Critic 超参数优化
📋 核心要点
- 传统强化学习固定控制频率,难以适应任务需求,导致计算量大和探索效率低。
- MOSEAC通过自适应奖励方案调整超参数,简化了变时间步长强化学习的部署。
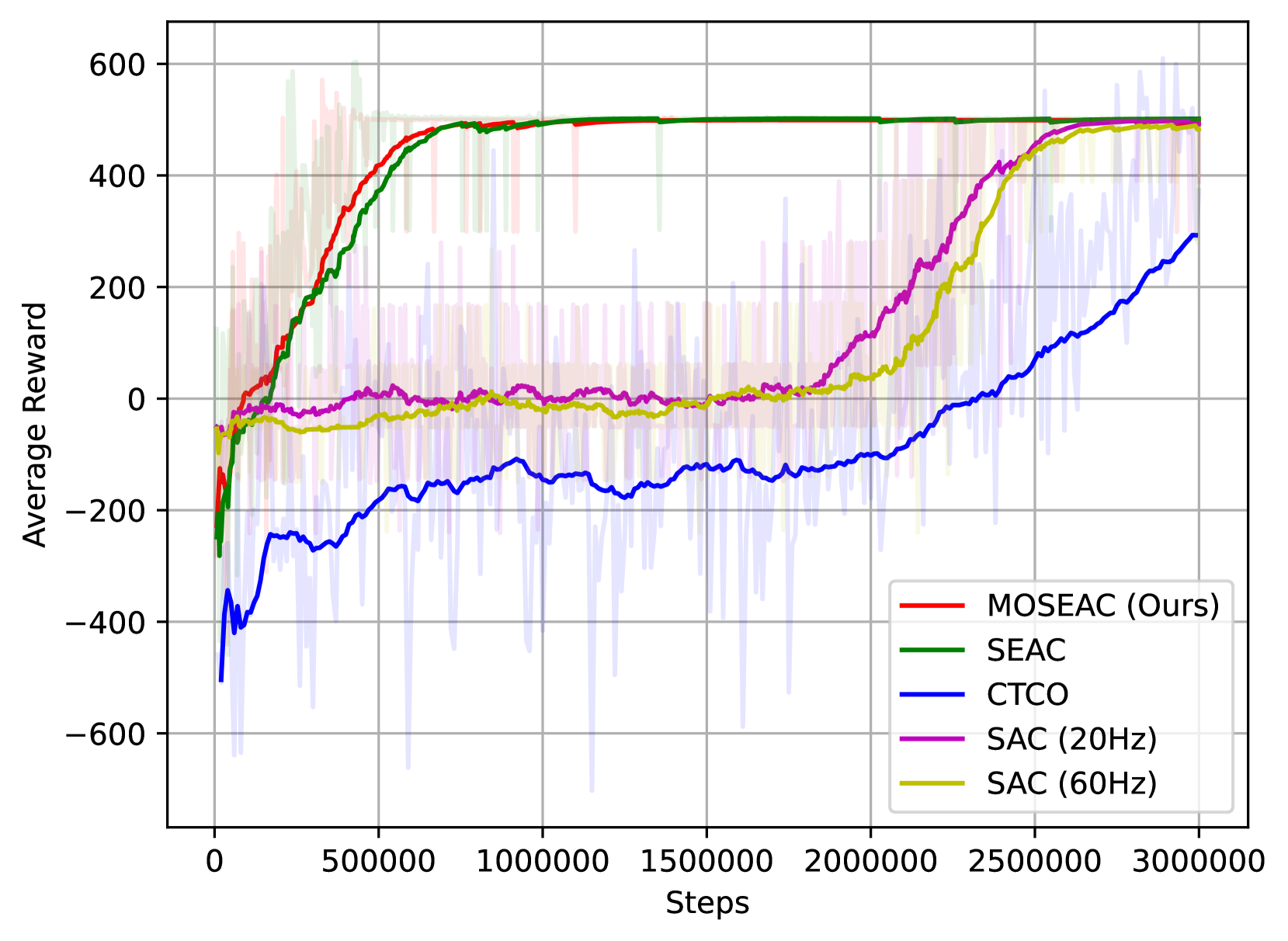
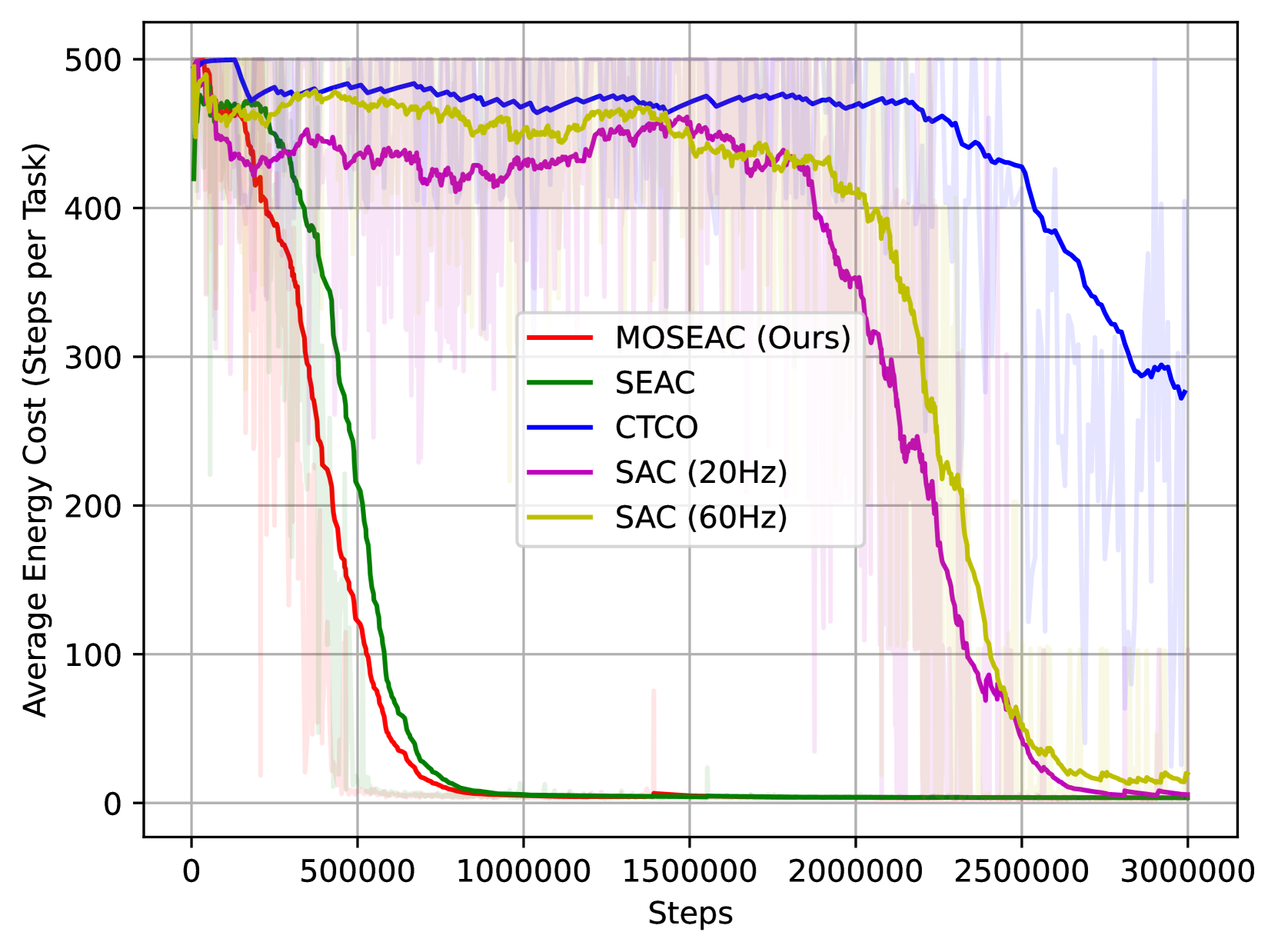
- 实验表明,MOSEAC在降低能耗的同时,保持了高任务和训练性能。
📝 摘要(中文)
传统的强化学习(RL)方法通常采用固定的控制循环,每个循环对应一个动作。这种刚性在实际应用中带来了挑战,因为最佳控制频率是任务相关的。次优的选择会导致高计算需求和降低探索效率。变时间步长强化学习(VTS-RL)通过对控制循环使用自适应频率来解决这些问题,仅在必要时执行动作。这种方法基于反应式编程原则,减少了计算负载,并通过包含动作持续时间来扩展动作空间。然而,VTS-RL的实现通常因需要调整多个超参数而变得复杂,这些超参数控制着多目标动作-持续时间空间中的探索(即,平衡任务性能和实现目标所需的步数)。为了克服这些挑战,我们引入了多目标软弹性Actor-Critic(MOSEAC)方法。该方法采用自适应奖励方案,根据训练期间观察到的任务奖励趋势来调整超参数。这种方案降低了超参数调整的复杂性,只需要一个超参数来指导探索,从而简化了学习过程并降低了部署成本。我们通过牛顿运动学环境中的仿真验证了MOSEAC方法,证明了其在更少的时间步长下具有高任务和训练性能,最终降低了能源消耗。该验证表明,MOSEAC通过使用单个参数自动调整代理控制循环频率来简化RL算法的部署。其原理可以应用于增强任何RL算法,使其成为各种应用的多功能解决方案。
🔬 方法详解
问题定义:传统强化学习方法采用固定的控制循环,无法根据任务需求调整控制频率。这导致在计算资源受限或对能耗敏感的场景下,效率低下。变时间步长强化学习(VTS-RL)旨在解决这个问题,但其实现复杂,需要手动调整多个超参数来平衡任务性能和时间步数,增加了部署难度。
核心思路:MOSEAC的核心思路是通过自适应奖励方案自动调整VTS-RL中的超参数,从而简化部署过程。它观察训练期间的任务奖励趋势,并据此动态调整超参数,无需手动干预。这种方法旨在找到一个平衡点,既能保证任务性能,又能减少时间步数,从而降低计算成本和能耗。
技术框架:MOSEAC采用Actor-Critic框架,并引入了软弹性(Soft Elastic)机制。整体流程如下:1. 智能体与环境交互,执行动作并获得奖励。2. 自适应奖励方案根据任务奖励趋势调整超参数。3. Actor网络根据调整后的超参数选择动作和动作持续时间。4. Critic网络评估Actor网络的性能。5. Actor和Critic网络根据评估结果进行更新。
关键创新:MOSEAC的关键创新在于其自适应奖励方案,该方案能够根据训练过程中的任务奖励动态调整超参数。与传统的VTS-RL方法需要手动调整多个超参数相比,MOSEAC只需要一个超参数来指导探索,大大简化了部署过程。此外,软弹性机制允许智能体在探索过程中更加灵活地调整动作持续时间。
关键设计:MOSEAC的关键设计包括:1. 自适应奖励函数:该函数根据任务奖励的变化趋势动态调整超参数,鼓励智能体在保证任务性能的同时减少时间步数。2. 软弹性Actor-Critic网络结构:Actor网络输出动作和动作持续时间,Critic网络评估Actor网络的性能。3. 损失函数:损失函数包括任务奖励损失和时间步数损失,用于平衡任务性能和时间步数。
🖼️ 关键图片
📊 实验亮点
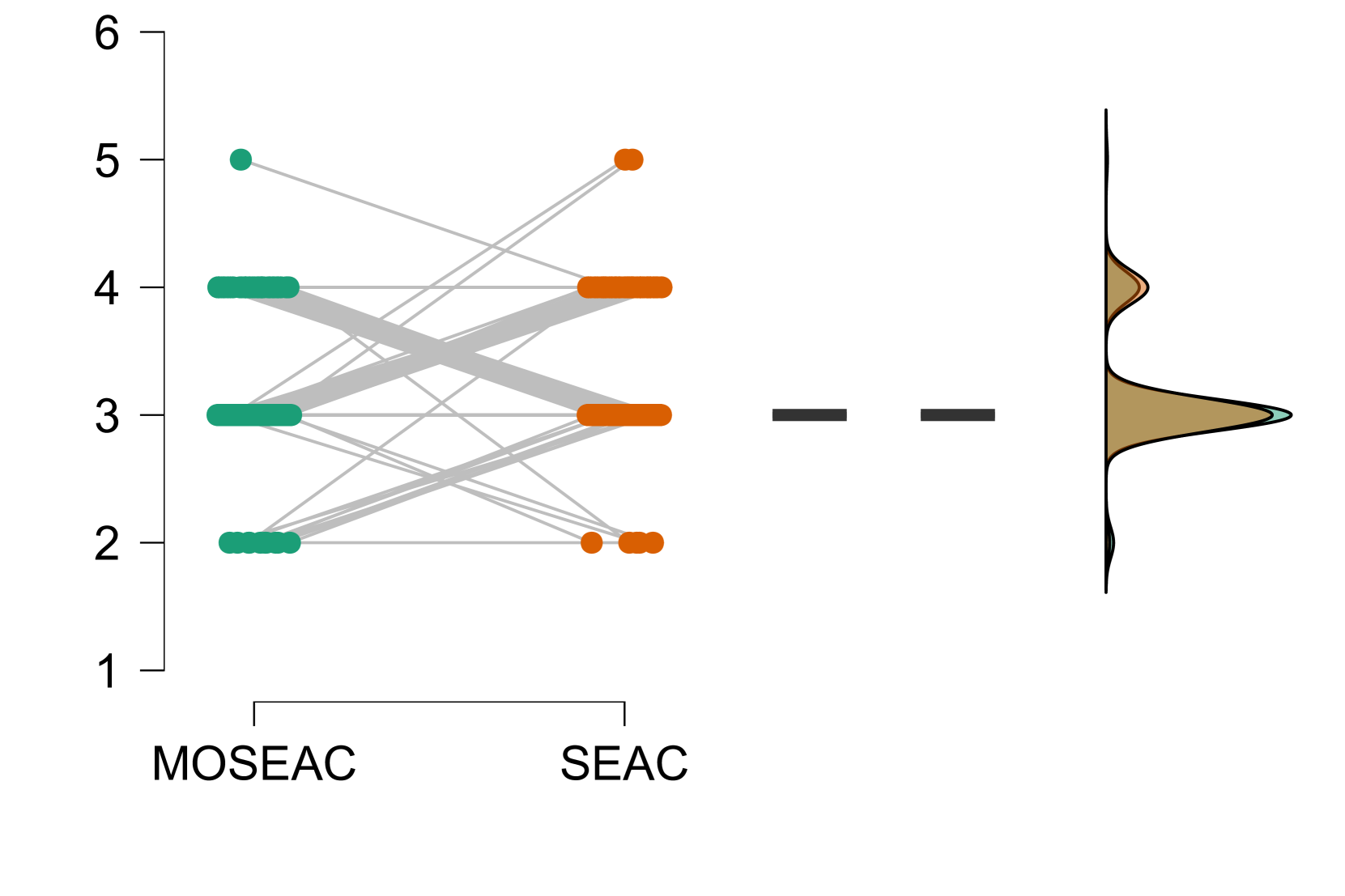
实验结果表明,MOSEAC在牛顿运动学环境中表现出色,能够在更少的时间步长下实现高任务和训练性能。与传统的固定时间步长强化学习方法相比,MOSEAC显著降低了能耗,并简化了超参数调整过程,只需一个参数即可指导探索。
🎯 应用场景
MOSEAC适用于需要优化控制频率的各种强化学习应用,例如机器人控制、自动驾驶、能源管理和资源调度等。通过自动调整控制循环频率,MOSEAC可以降低计算成本、提高能源效率,并简化算法部署,从而加速这些领域的发展。
📄 摘要(原文)
Traditional reinforcement learning (RL) methods typically employ a fixed control loop, where each cycle corresponds to an action. This rigidity poses challenges in practical applications, as the optimal control frequency is task-dependent. A suboptimal choice can lead to high computational demands and reduced exploration efficiency. Variable Time Step Reinforcement Learning (VTS-RL) addresses these issues by using adaptive frequencies for the control loop, executing actions only when necessary. This approach, rooted in reactive programming principles, reduces computational load and extends the action space by including action durations. However, VTS-RL's implementation is often complicated by the need to tune multiple hyperparameters that govern exploration in the multi-objective action-duration space (i.e., balancing task performance and number of time steps to achieve a goal). To overcome these challenges, we introduce the Multi-Objective Soft Elastic Actor-Critic (MOSEAC) method. This method features an adaptive reward scheme that adjusts hyperparameters based on observed trends in task rewards during training. This scheme reduces the complexity of hyperparameter tuning, requiring a single hyperparameter to guide exploration, thereby simplifying the learning process and lowering deployment costs. We validate the MOSEAC method through simulations in a Newtonian kinematics environment, demonstrating high task and training performance with fewer time steps, ultimately lowering energy consumption. This validation shows that MOSEAC streamlines RL algorithm deployment by automatically tuning the agent control loop frequency using a single parameter. Its principles can be applied to enhance any RL algorithm, making it a versatile solution for various applications.