Mamba State-Space Models Are Lyapunov-Stable Learners
作者: John T. Halloran, Manbir Gulati, Paul F. Roysdon
分类: cs.LG, cs.AI
发布日期: 2024-05-31 (更新: 2025-08-29)
备注: TMLR, 27 pages, 12 figures, 4 tables
💡 一句话要点
Mamba状态空间模型:Lyapunov稳定性保障下的稳健学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 状态空间模型 Mamba Lyapunov稳定性 混合精度微调 参数高效微调 大型语言模型 循环神经网络
📋 核心要点
- 循环神经网络的稳定性是深度学习中的关键问题,尤其是在微调过程中,模型参数的微小变化可能导致性能显著下降。
- 该论文证明了Mamba状态空间模型的循环动态具有Lyapunov稳定性,从而保证了模型在微调过程中的稳健性。
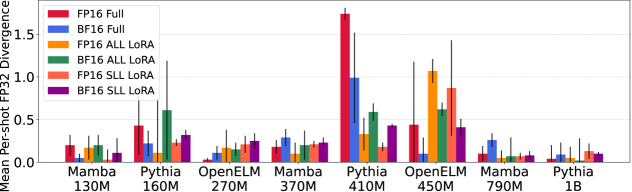
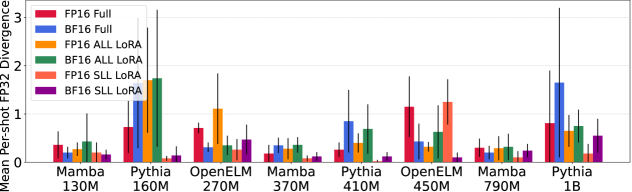
- 实验结果表明,Mamba LLM在混合精度微调和参数高效微调下表现出极高的稳定性,优于Transformer LLM。
📝 摘要(中文)
Mamba状态空间模型(SSM)最近在各种任务中超越了最先进的Transformer大型语言模型(LLM),并被广泛应用。然而,基于循环的深度模型(如SSM)稳定学习的一个主要问题是其循环动态的敏感性。尽管Mamba被广泛采用,但其循环动态在常见的微调方法(如混合精度微调(MPFT)和参数高效微调(PEFT))下的敏感性仍未被探索。经验表明,Mamba LLM对MPFT和PEFT组合引入的变化非常稳定,这与Transformer LLM形成鲜明对比,后者在MPFT和PEFT的不同组合下可能会与其各自的全精度版本产生巨大差异(尽管这些微调框架几乎普遍适用于基于注意力的模型)。Mamba LLM所展示的鲁棒性归功于其循环动态,我们证明了使用动力系统理论(特别是Lyapunov稳定性)可以保证其稳定性。最后,我们使用MPFT和PEFT来新颖地研究Mamba LLM在自然语言任务上的上下文学习(ICL)能力,从而补充了其他最近的工作。
🔬 方法详解
问题定义:现有的大型语言模型,特别是Transformer模型,在进行混合精度微调(MPFT)和参数高效微调(PEFT)时,容易出现性能下降,甚至发散的问题。这是由于Transformer模型的注意力机制对参数变化较为敏感,导致模型在微调后无法保持原有的性能水平。因此,如何保证大型语言模型在微调过程中的稳定性是一个重要的研究问题。
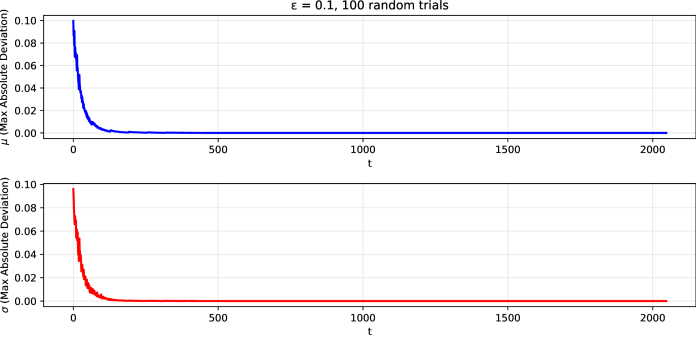
核心思路:该论文的核心思路是利用Mamba状态空间模型的循环动态的Lyapunov稳定性来保证模型在微调过程中的稳健性。Lyapunov稳定性理论可以证明,即使模型参数发生变化,其状态仍然会收敛到一个稳定的状态,从而保证模型的性能不会显著下降。
技术框架:该论文主要研究了Mamba状态空间模型在MPFT和PEFT下的稳定性。首先,论文从理论上证明了Mamba模型的循环动态具有Lyapunov稳定性。然后,论文通过实验验证了Mamba模型在MPFT和PEFT下的稳定性,并与Transformer模型进行了对比。最后,论文还研究了Mamba模型在上下文学习(ICL)方面的能力。
关键创新:该论文最重要的技术创新点在于证明了Mamba状态空间模型的循环动态具有Lyapunov稳定性。这是首次将Lyapunov稳定性理论应用于Mamba模型,并证明了其在微调过程中的稳健性。此外,该论文还通过实验验证了Mamba模型在MPFT和PEFT下的稳定性,并与Transformer模型进行了对比,从而进一步证明了Mamba模型的优势。
关键设计:该论文的关键设计在于利用Lyapunov稳定性理论来分析Mamba模型的循环动态。具体来说,论文首先推导了Mamba模型的循环动态方程,然后利用Lyapunov函数来证明其稳定性。此外,论文还设计了一系列实验来验证Mamba模型在MPFT和PEFT下的稳定性,并与Transformer模型进行了对比。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Mamba LLM在MPFT和PEFT的组合下表现出极高的稳定性,显著优于Transformer LLM。在某些情况下,Transformer LLM在微调后性能大幅下降,而Mamba LLM则能保持甚至提升性能。这证明了Mamba模型在微调过程中的稳健性。
🎯 应用场景
该研究成果可应用于各种需要进行微调的大型语言模型场景,尤其是在资源受限的环境下,混合精度微调和参数高效微调是常用的技术手段。Mamba模型的稳定性使其成为这些场景下的理想选择,可以降低微调过程中的风险,提高模型性能。
📄 摘要(原文)
Mamba state-space models (SSMs) have recently outperformed state-of-the-art (SOTA) Transformer large language models (LLMs) in various tasks and been widely adapted. However, a major concern for stable learning in recurrent-based deep models (such as SSMs) is the sensitivity of their recurrent dynamics. Despite widespread adaptation, the sensitivity of Mamba's recurrent dynamics under common fine-tuning methods-e.g., mixed-precision fine-tuning (MPFT) and parameter-efficient fine-tuning (PEFT)-remains unexplored. Empirically, we show that Mamba LLMs are extremely stable to changes introduced by combinations of MPFT and PEFT, in stark contrast to Transformer LLMs, which we demonstrate may drastically diverge from their respective full-precision counterparts under different combinations of MPFT and PEFT (despite the near-ubiquitous adaptation of these fine-tuning frameworks for attention-based models). The demonstrated robustness of Mamba LLMs are due to their recurrent dynamics, which we prove are guaranteed to be stable using dynamical systems theory (in particular, Lyapunov stability). We conclude by using MPFT and PEFT to novelly study Mamba LLMs' in-context learning (ICL) abilities on natural language tasks, thus supplementing other recent work.