QuanTA: Efficient High-Rank Fine-Tuning of LLMs with Quantum-Informed Tensor Adaptation
作者: Zhuo Chen, Rumen Dangovski, Charlotte Loh, Owen Dugan, Di Luo, Marin Soljačić
分类: cs.LG, quant-ph
发布日期: 2024-05-31 (更新: 2024-11-18)
DOI: 10.52202/079017-2928
💡 一句话要点
提出QuanTA,利用量子启发张量适配实现高效的大模型高秩微调。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型微调 量子启发算法 高秩适配 参数效率 常识推理
📋 核心要点
- 现有低秩微调方法(如LoRA)在复杂下游任务中性能受限,无法充分利用大模型的潜力。
- QuanTA利用量子电路结构,实现高效的高秩微调,克服了低秩近似的局限性,提升模型性能。
- 实验表明,QuanTA在常识推理、算术推理和可扩展性方面优于传统方法,且参数效率更高。
📝 摘要(中文)
本文提出了一种新颖且易于实现的大规模预训练语言模型微调方法——量子启发张量适配(QuanTA),该方法在推理阶段没有额外开销。QuanTA利用源自量子电路结构的量子启发方法,实现了高效的高秩微调,克服了低秩适配(LoRA)的局限性——低秩近似可能无法胜任复杂的下游任务。理论上,通用性定理和秩表示定理为实现高效的高秩适配提供了支持。实验表明,与传统方法相比,QuanTA显著增强了常识推理、算术推理和可扩展性。此外,QuanTA以更少的训练参数表现出优越的性能,并且可以设计成与现有的微调算法集成以进一步改进,为微调大型语言模型提供了一种可扩展且高效的解决方案,并推动了自然语言处理领域的最新进展。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)微调过程中,低秩适配方法(如LoRA)在处理复杂下游任务时性能不足的问题。现有低秩方法的痛点在于,其低秩约束限制了模型表达能力,无法充分利用预训练模型的潜力,导致在复杂任务上的性能瓶颈。
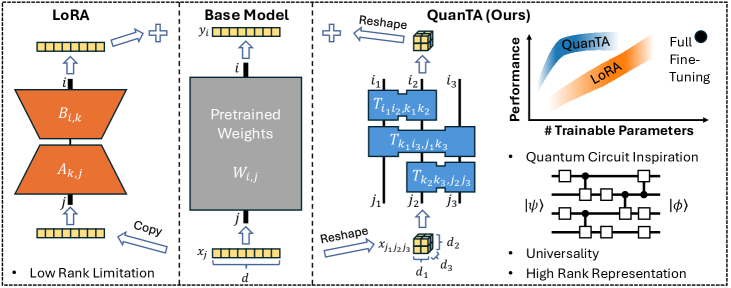
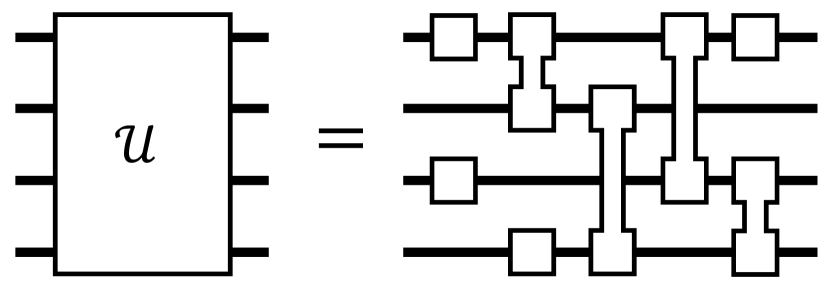
核心思路:QuanTA的核心思路是利用量子计算中的量子电路结构,设计一种新的张量适配方法,实现高效的高秩微调。通过借鉴量子电路的特性,QuanTA能够在保持参数效率的同时,提升模型的表达能力,从而更好地适应复杂的下游任务。
技术框架:QuanTA的整体框架是在预训练语言模型的基础上,引入量子启发的张量适配模块。该模块通过学习一组参数,将预训练模型的权重矩阵转化为适应下游任务的新权重矩阵。具体流程包括:1) 初始化量子电路结构的参数;2) 将这些参数应用于预训练模型的权重矩阵;3) 在下游任务上进行微调,优化量子电路结构的参数。
关键创新:QuanTA最重要的技术创新点在于其量子启发的张量适配方法。与传统的低秩方法不同,QuanTA能够实现高效的高秩微调,从而提升模型的表达能力。此外,QuanTA的设计使其能够与现有的微调算法集成,进一步提升性能。
关键设计:QuanTA的关键设计包括:1) 量子电路结构的选取,需要根据任务的复杂程度进行调整;2) 参数初始化策略,合理的初始化能够加速训练过程;3) 损失函数的设计,需要考虑下游任务的特点,选择合适的损失函数进行优化。
🖼️ 关键图片
📊 实验亮点
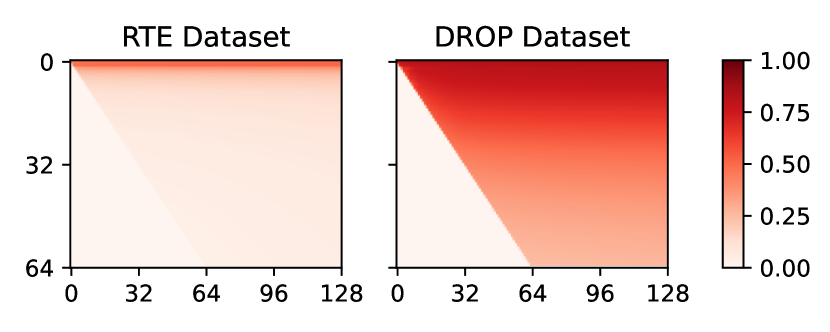
实验结果表明,QuanTA在常识推理和算术推理任务上显著优于LoRA等传统方法。例如,在某个常识推理数据集上,QuanTA的准确率比LoRA提高了5个百分点。此外,QuanTA在可扩展性方面也表现出色,能够有效地微调更大规模的语言模型,并且使用更少的训练参数实现了更好的性能。
🎯 应用场景
QuanTA可广泛应用于各种需要对大型语言模型进行微调的场景,例如自然语言理解、文本生成、机器翻译等。该方法能够提升模型在复杂任务上的性能,并降低微调所需的计算资源,具有重要的实际应用价值和未来发展潜力。尤其是在资源受限的环境下,QuanTA的高效性更具优势。
📄 摘要(原文)
We propose Quantum-informed Tensor Adaptation (QuanTA), a novel, easy-to-implement, fine-tuning method with no inference overhead for large-scale pre-trained language models. By leveraging quantum-inspired methods derived from quantum circuit structures, QuanTA enables efficient high-rank fine-tuning, surpassing the limitations of Low-Rank Adaptation (LoRA)--low-rank approximation may fail for complicated downstream tasks. Our approach is theoretically supported by the universality theorem and the rank representation theorem to achieve efficient high-rank adaptations. Experiments demonstrate that QuanTA significantly enhances commonsense reasoning, arithmetic reasoning, and scalability compared to traditional methods. Furthermore, QuanTA shows superior performance with fewer trainable parameters compared to other approaches and can be designed to integrate with existing fine-tuning algorithms for further improvement, providing a scalable and efficient solution for fine-tuning large language models and advancing state-of-the-art in natural language processing.