From Unstructured Data to In-Context Learning: Exploring What Tasks Can Be Learned and When
作者: Kevin Christian Wibisono, Yixin Wang
分类: cs.LG, cs.CL, stat.ML
发布日期: 2024-05-31 (更新: 2024-11-10)
备注: 39 pages
💡 一句话要点
研究揭示非结构化数据训练的LLM上下文学习能力及其局限性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 非结构化数据 大型语言模型 词语类比 逻辑推理 训练数据结构 序列模型
📋 核心要点
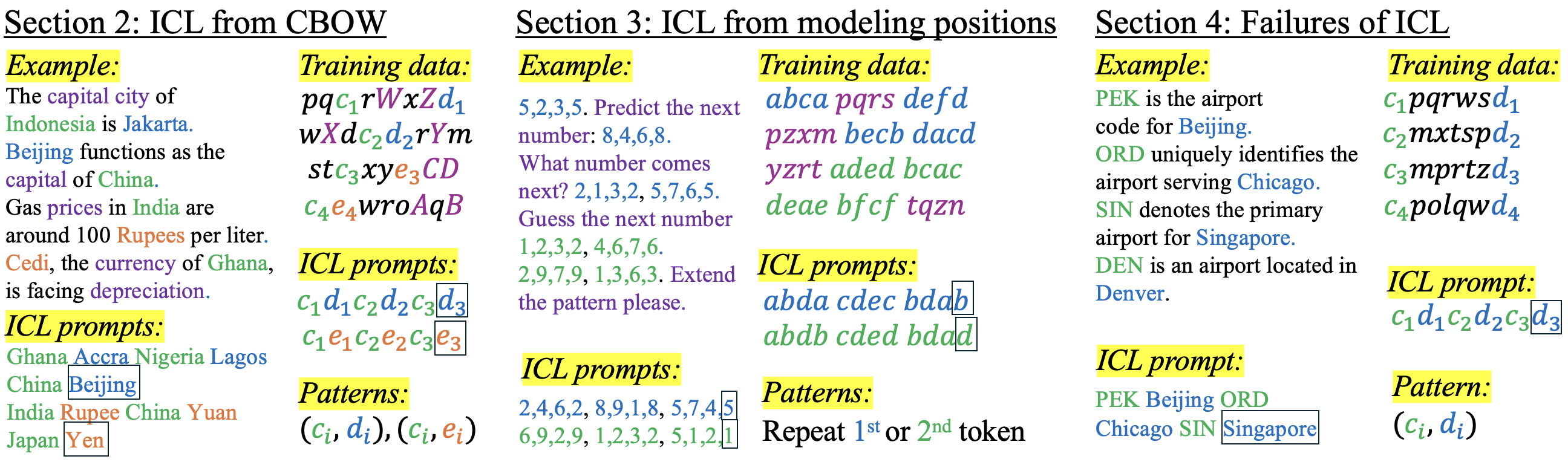
- 现有ICL理论假设LLM在结构化数据上训练,但实际LLM通常在非结构化数据上训练,这导致理论与实践存在差距。
- 该研究探索了非结构化数据训练的LLM如何具备ICL能力,重点关注序列模型的要求和训练数据的结构。
- 研究发现词对共现足以使LLM具备词语类比能力,但位置信息对于逻辑推理至关重要,并指出了ICL失效的两种情况。
📝 摘要(中文)
大型语言模型(LLM),如Transformer,展现了卓越的上下文学习(ICL)能力,无需参数更新即可基于提示样本对新任务进行预测。现有ICL理论通常假设结构化训练数据类似于ICL任务(例如,线性回归的x-y对),但LLM通常在非结构化文本(如网络内容)上进行无监督训练,这些文本缺乏与词语类比等任务的明确对应关系。为了弥补这一差距,我们研究了在非结构化数据上训练的模型中实现ICL的原因,重点关注关键的序列模型要求和训练数据结构。我们发现,许多ICL能力可以简单地从非结构化数据中语义相关的词对的共现中产生;例如,词语类比补全可以通过经典的语言模型(如连续词袋模型(CBOW))纯粹通过共现建模来证明,而不需要位置信息或注意力机制。然而,位置信息对于需要推广到未见过的token的逻辑推理任务至关重要。最后,我们确定了ICL失败的两种情况:一种是需要推广到新的、未见过的模式的逻辑推理任务,另一种是相关词对仅出现在固定训练位置的类比补全任务。这些发现表明,LLM的ICL能力在很大程度上取决于其训练数据中的结构元素。
🔬 方法详解
问题定义:现有关于LLM上下文学习(ICL)的理论,大多基于结构化数据训练的假设,例如线性回归的x-y对。然而,实际的LLM通常在非结构化的文本数据上进行训练,例如网页内容。这种差异导致现有理论难以解释LLM在非结构化数据上训练后所表现出的ICL能力。因此,该论文旨在研究非结构化数据训练的LLM如何以及何时具备ICL能力,并探究其局限性。
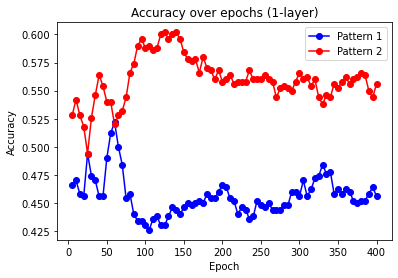
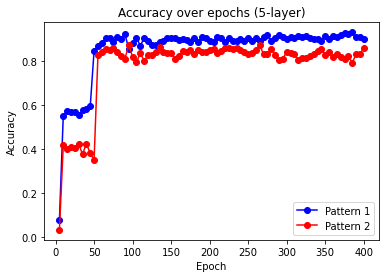
核心思路:论文的核心思路是通过分析训练数据的结构和序列模型的要求,来理解LLM的ICL能力。具体来说,论文研究了词对的共现、位置信息等因素对ICL能力的影响。通过理论分析和实验验证,论文揭示了ICL能力与训练数据结构之间的关系,并指出了ICL失效的两种情况。
技术框架:该研究主要采用理论分析和实验验证相结合的方法。首先,论文对词对共现和位置信息对ICL能力的影响进行了理论分析,并提出了相应的假设。然后,论文通过实验验证了这些假设。实验中,论文使用了连续词袋模型(CBOW)等经典语言模型,以及逻辑推理和类比补全等任务。
关键创新:该论文最重要的技术创新点在于揭示了非结构化数据训练的LLM的ICL能力与训练数据结构之间的关系。具体来说,论文发现词对共现足以使LLM具备词语类比能力,但位置信息对于逻辑推理至关重要。此外,论文还指出了ICL失效的两种情况,即需要推广到新的、未见过的模式的逻辑推理任务,以及相关词对仅出现在固定训练位置的类比补全任务。
关键设计:论文的关键设计包括:1) 使用连续词袋模型(CBOW)等经典语言模型来模拟LLM的训练过程;2) 设计了逻辑推理和类比补全等任务来评估LLM的ICL能力;3) 通过控制训练数据的结构(例如,词对共现、位置信息)来研究其对ICL能力的影响。论文没有涉及复杂的网络结构或损失函数,而是侧重于分析训练数据的结构对ICL能力的影响。
🖼️ 关键图片
📊 实验亮点
研究表明,仅通过词对共现,CBOW等模型即可实现词语类比补全,无需位置信息或注意力机制。但对于逻辑推理,位置信息至关重要。研究还发现了ICL失败的两种情况:无法泛化到新模式的逻辑推理,以及词对仅在固定位置出现的类比补全。
🎯 应用场景
该研究成果可应用于提升LLM在各种任务上的泛化能力,尤其是在处理非结构化数据时。通过理解训练数据结构对ICL能力的影响,可以更好地设计训练数据,从而提高LLM的性能。此外,该研究还可以帮助我们更好地理解LLM的内部机制,为开发更强大的LLM提供理论基础。
📄 摘要(原文)
Large language models (LLMs) like transformers demonstrate impressive in-context learning (ICL) capabilities, allowing them to make predictions for new tasks based on prompt exemplars without parameter updates. While existing ICL theories often assume structured training data resembling ICL tasks (e.g., x-y pairs for linear regression), LLMs are typically trained unsupervised on unstructured text, such as web content, which lacks clear parallels to tasks like word analogy. To address this gap, we examine what enables ICL in models trained on unstructured data, focusing on critical sequence model requirements and training data structure. We find that many ICL capabilities can emerge simply from co-occurrence of semantically related word pairs in unstructured data; word analogy completion, for example, can provably arise purely through co-occurrence modeling, using classical language models like continuous bag of words (CBOW), without needing positional information or attention mechanisms. However, positional information becomes crucial for logic reasoning tasks requiring generalization to unseen tokens. Finally, we identify two cases where ICL fails: one in logic reasoning tasks that require generalizing to new, unseen patterns, and another in analogy completion where relevant word pairs appear only in fixed training positions. These findings suggest that LLMs' ICL abilities depend heavily on the structural elements within their training data.