Bayesian Design Principles for Offline-to-Online Reinforcement Learning
作者: Hao Hu, Yiqin Yang, Jianing Ye, Chengjie Wu, Ziqing Mai, Yujing Hu, Tangjie Lv, Changjie Fan, Qianchuan Zhao, Chongjie Zhang
分类: cs.LG
发布日期: 2024-05-31
备注: Forty-first International Conference on Machine Learning (ICML), 2024
💡 一句话要点
提出基于贝叶斯设计的离线到在线强化学习方法,解决策略优化中的悲观/乐观困境。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 在线微调 贝叶斯优化 概率匹配 策略学习
📋 核心要点
- 离线强化学习策略微调面临悲观探索不足和乐观性能骤降的难题。
- 采用贝叶斯设计原则,智能体根据对最优策略的置信度进行概率匹配行动。
- 提出的新算法在多个基准测试中超越现有方法,验证了方法的有效性。
📝 摘要(中文)
离线强化学习(RL)在探索代价高昂或不安全的现实世界应用中至关重要。然而,离线学习的策略通常不是最优的,需要进一步的在线微调。本文解决了离线到在线微调中的一个根本困境:如果智能体保持悲观,它可能无法学习到更好的策略;而如果它直接变得乐观,性能可能会遭受突然下降。我们表明,贝叶斯设计原则对于解决这种困境至关重要。智能体不应采取乐观或悲观的策略,而应以与其对最优策略的信念相匹配的方式行动。这种概率匹配的智能体可以避免性能的突然下降,同时仍然保证找到最优策略。基于我们的理论发现,我们引入了一种新算法,该算法在各种基准测试中优于现有方法,证明了我们方法的有效性。总的来说,所提出的方法为离线到在线RL提供了一个新的视角,有可能实现从离线数据中更有效的学习。
🔬 方法详解
问题定义:论文旨在解决离线强化学习到在线微调过程中,智能体策略更新的困境。现有方法要么过于悲观,导致探索不足,无法找到更优策略;要么过于乐观,导致性能突然下降。这种困境源于离线数据与在线环境的差异,以及智能体对环境不确定性的处理方式。
核心思路:论文的核心思路是采用贝叶斯设计原则,让智能体根据其对最优策略的信念(belief)来行动。具体来说,智能体不应该简单地选择最乐观或最悲观的策略,而是应该以一种概率匹配的方式,根据其信念分布来选择行动。这样可以避免过于激进的策略更新,从而缓解性能骤降的问题,同时保证最终能够找到最优策略。
技术框架:整体框架包含离线学习阶段和在线微调阶段。离线学习阶段使用离线数据集训练一个初始策略。在线微调阶段,智能体维护一个关于最优策略的信念分布,并根据该分布进行概率匹配的行动选择。具体流程如下:1. 使用离线数据训练初始策略;2. 在线交互时,维护策略的后验分布;3. 根据后验分布,采样策略并执行;4. 根据环境反馈更新后验分布。
关键创新:论文的关键创新在于将贝叶斯设计原则引入离线到在线强化学习中,并提出了一种概率匹配的行动选择策略。与现有方法相比,该方法不是简单地采用悲观或乐观的策略,而是根据智能体对最优策略的信念进行行动选择,从而更好地平衡探索和利用。这种方法能够避免性能的突然下降,同时保证最终能够找到最优策略。
关键设计:论文的关键设计包括:1. 使用贝叶斯方法维护策略的后验分布;2. 设计概率匹配的行动选择策略,根据后验分布采样策略并执行;3. 设计合适的后验更新方法,根据环境反馈更新策略的后验分布。具体的参数设置、损失函数和网络结构取决于具体的应用场景和离线数据集。
🖼️ 关键图片
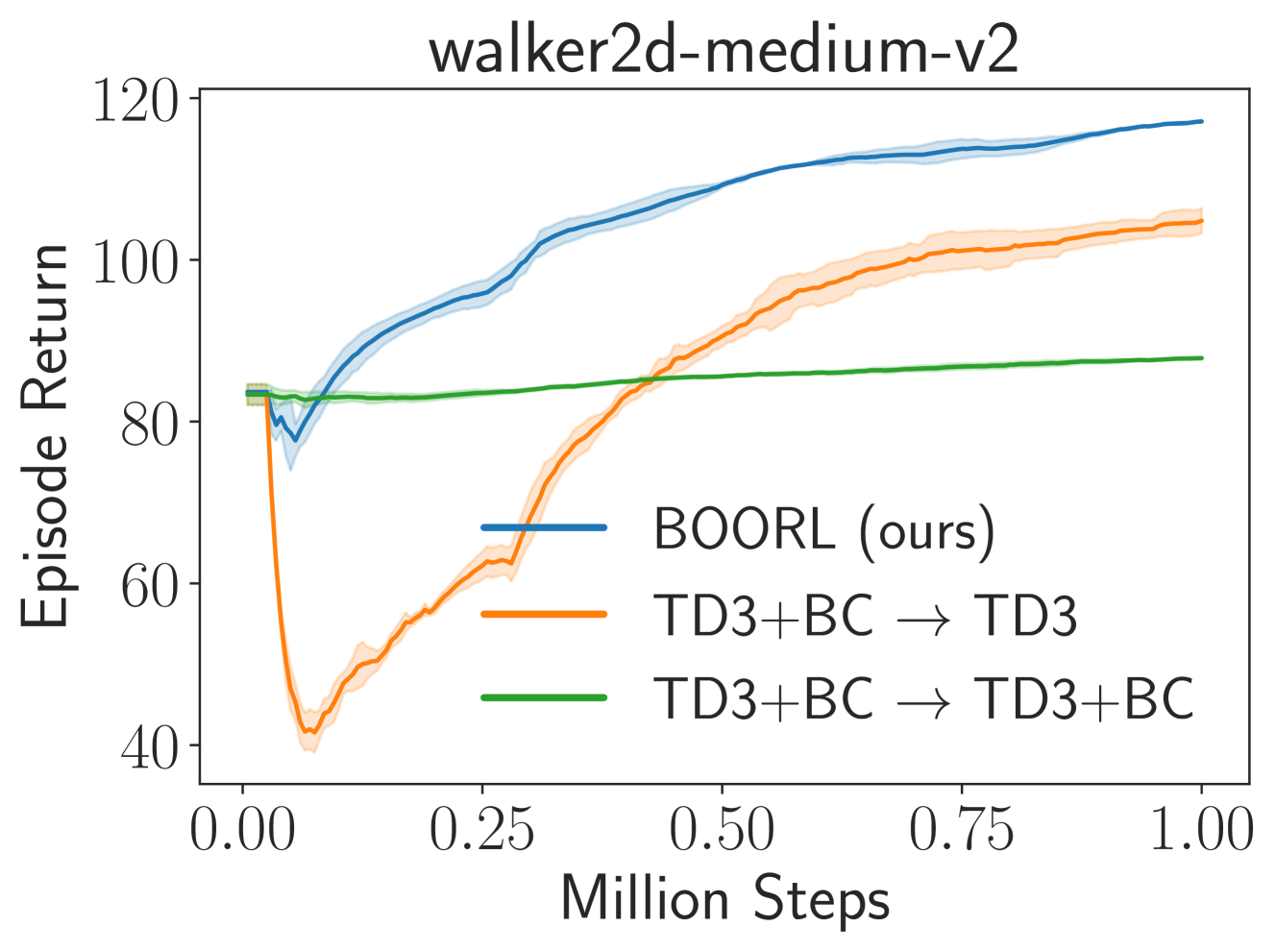


📊 实验亮点
实验结果表明,提出的算法在多个基准测试中优于现有的离线到在线强化学习方法。具体而言,该算法在性能稳定性方面表现更佳,能够有效避免在线微调过程中的性能骤降。在某些任务上,该算法的最终性能也优于其他方法,证明了其在探索和利用之间的平衡能力。
🎯 应用场景
该研究成果可应用于机器人控制、自动驾驶、游戏AI等领域,尤其是在探索成本高昂或存在安全风险的场景下。通过利用离线数据进行预训练,并结合在线微调,可以显著降低学习成本,提高学习效率,并保证策略的安全性。该方法有望推动强化学习在现实世界中的广泛应用。
📄 摘要(原文)
Offline reinforcement learning (RL) is crucial for real-world applications where exploration can be costly or unsafe. However, offline learned policies are often suboptimal, and further online fine-tuning is required. In this paper, we tackle the fundamental dilemma of offline-to-online fine-tuning: if the agent remains pessimistic, it may fail to learn a better policy, while if it becomes optimistic directly, performance may suffer from a sudden drop. We show that Bayesian design principles are crucial in solving such a dilemma. Instead of adopting optimistic or pessimistic policies, the agent should act in a way that matches its belief in optimal policies. Such a probability-matching agent can avoid a sudden performance drop while still being guaranteed to find the optimal policy. Based on our theoretical findings, we introduce a novel algorithm that outperforms existing methods on various benchmarks, demonstrating the efficacy of our approach. Overall, the proposed approach provides a new perspective on offline-to-online RL that has the potential to enable more effective learning from offline data.