Q-learning as a monotone scheme
作者: Lingyi Yang
分类: cs.LG
发布日期: 2024-05-30
💡 一句话要点
将Q-learning解释为单调格式,分析函数逼近对稳定性的影响
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Q-learning 强化学习 单调格式 稳定性分析 函数逼近
📋 核心要点
- 深度强化学习方法面临稳定性与收敛性挑战,尤其是在函数逼近的情况下。
- 论文将精确Q-learning的收敛性准则解释为单调格式,提供了一种新的分析视角。
- 通过线性二次例子,研究了函数逼近对Q-learning单调性属性的影响。
📝 摘要(中文)
强化学习方法的稳定性问题一直存在。为了更好地理解深度强化学习方法中涉及的一些稳定性和收敛性问题,我们研究了一个简单的线性二次例子。我们将精确Q-learning的收敛准则解释为单调格式,并讨论了函数逼近对单调性属性的影响。
🔬 方法详解
问题定义:强化学习,特别是深度强化学习,在实际应用中经常遇到稳定性问题。现有的深度强化学习方法,由于使用了函数逼近(例如深度神经网络),难以保证收敛性,导致训练过程不稳定,性能波动大。论文关注的是如何理解和解决Q-learning中的稳定性问题,尤其是在函数逼近的情况下。
核心思路:论文的核心思路是将精确Q-learning的收敛准则解释为一种单调格式。单调格式在数值分析中具有良好的稳定性,如果Q-learning可以被视为一种单调格式,那么就可以利用单调性来分析和理解其稳定性。通过研究函数逼近对单调性的影响,可以更好地理解深度Q-learning的稳定性问题。
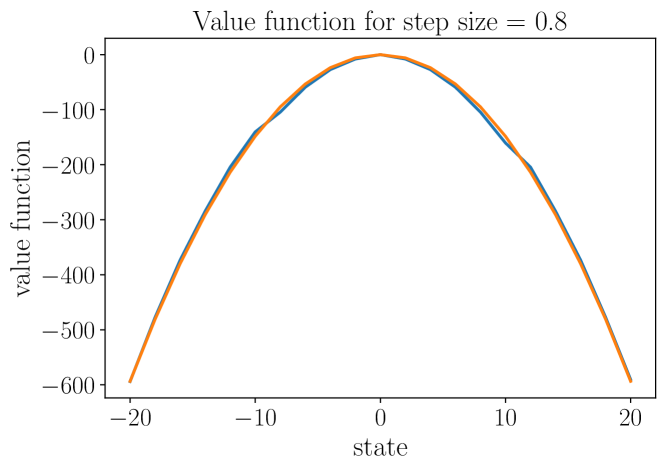
技术框架:论文主要通过理论分析和一个简单的线性二次例子来研究Q-learning的单调性。没有提出新的算法框架,而是侧重于理论解释。具体步骤包括:1) 将精确Q-learning的更新规则表示为一种迭代格式;2) 分析该迭代格式是否满足单调性条件;3) 研究函数逼近如何影响单调性;4) 通过线性二次例子验证理论分析。
关键创新:论文的关键创新在于将Q-learning的收敛准则与数值分析中的单调格式联系起来。这种联系提供了一种新的视角来理解Q-learning的稳定性,并为分析函数逼近对稳定性的影响提供了理论基础。这是对Q-learning理论理解的一个重要贡献。
关键设计:论文主要关注理论分析,没有涉及具体的参数设置或网络结构设计。关键在于对Q-learning更新规则的数学表达,以及对单调性条件的分析。线性二次例子被用来验证理论分析,但没有提供具体的实验细节。
🖼️ 关键图片


📊 实验亮点
论文通过理论分析,将精确Q-learning的收敛准则解释为单调格式,并使用线性二次例子验证了函数逼近对单调性属性的影响。虽然没有提供具体的性能数据,但为理解深度强化学习的稳定性问题提供了一种新的视角。
🎯 应用场景
该研究成果有助于更好地理解和设计稳定的深度强化学习算法。通过将Q-learning与单调格式联系起来,可以为开发更可靠的强化学习方法提供理论指导,从而在机器人控制、自动驾驶、游戏AI等领域实现更安全、更高效的应用。
📄 摘要(原文)
Stability issues with reinforcement learning methods persist. To better understand some of these stability and convergence issues involving deep reinforcement learning methods, we examine a simple linear quadratic example. We interpret the convergence criterion of exact Q-learning in the sense of a monotone scheme and discuss consequences of function approximation on monotonicity properties.