Large Language Models Can Self-Improve At Web Agent Tasks
作者: Ajay Patel, Markus Hofmarcher, Claudiu Leoveanu-Condrei, Marius-Constantin Dinu, Chris Callison-Burch, Sepp Hochreiter
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-05-30 (更新: 2024-10-01)
💡 一句话要点
LLM通过自学习提升Web Agent任务性能,在WebArena上提升31%
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自学习 Web Agent WebArena 长时程任务
📋 核心要点
- 现有Web Agent训练方法受限于训练数据不足,难以有效导航和执行复杂任务。
- 该研究探索LLM通过自学习,即在自身生成的数据上微调,提升Web Agent性能。
- 实验表明,通过自学习,LLM在WebArena基准测试中任务完成率提升了31%。
📝 摘要(中文)
由于缺乏训练数据,训练模型作为智能体在复杂环境(如Web浏览器)中有效地导航和执行动作一直具有挑战性。最近,大型语言模型(LLM)已经展示出在零样本或少样本情况下,仅通过自然语言指令作为提示,就能作为智能体在新的环境中导航的能力。最近的研究也表明,LLM有能力通过自学习来超越其基础性能,即在模型自身生成的数据上进行微调。在这项工作中,我们探索了LLM在复杂环境中使用WebArena基准进行长时程任务时,自学习提升其作为智能体性能的程度。在WebArena中,智能体必须自主地导航网页并执行动作以实现指定的目标。我们探索了在三种不同的合成训练数据混合上进行微调,并通过自学习程序在WebArena基准上实现了比基础模型高31%的任务完成率。此外,我们还贡献了新的评估指标,用于更全面地评估我们微调后的智能体模型的性能、鲁棒性、能力和轨迹质量,超越了目前用于衡量自学习的简单、聚合级别的基准分数。
🔬 方法详解
问题定义:论文旨在解决Web Agent在复杂Web环境中进行长时程任务时,由于缺乏高质量训练数据而导致的性能瓶颈问题。现有方法依赖于人工标注数据或有限的交互数据,难以覆盖Web环境的复杂性和多样性,导致Agent泛化能力不足。
核心思路:论文的核心思路是利用LLM的自学习能力,通过在模型自身生成的合成数据上进行微调,来提升Web Agent的性能。这种方法避免了对大量人工标注数据的依赖,并能够利用LLM的知识和推理能力来生成更具挑战性和多样性的训练数据。
技术框架:整体框架包含以下几个主要阶段:1) 使用LLM作为基础Agent,在WebArena环境中进行探索,生成交互轨迹;2) 对生成的轨迹进行筛选和处理,构建合成训练数据集;3) 使用合成训练数据集对LLM进行微调,得到自学习后的Web Agent;4) 使用新的评估指标对微调后的Agent进行评估,包括性能、鲁棒性、能力和轨迹质量。
关键创新:论文的关键创新在于提出了一种基于LLM自学习的Web Agent训练方法,该方法能够有效地利用LLM的知识和推理能力来生成高质量的训练数据,从而提升Agent的性能。此外,论文还提出了新的评估指标,能够更全面地评估Agent的性能和能力。
关键设计:论文探索了三种不同的合成训练数据混合方式,并对LLM进行了微调。具体的参数设置和损失函数等技术细节在论文中没有详细描述,属于未知信息。论文重点强调了自学习框架和新的评估指标的设计。
🖼️ 关键图片
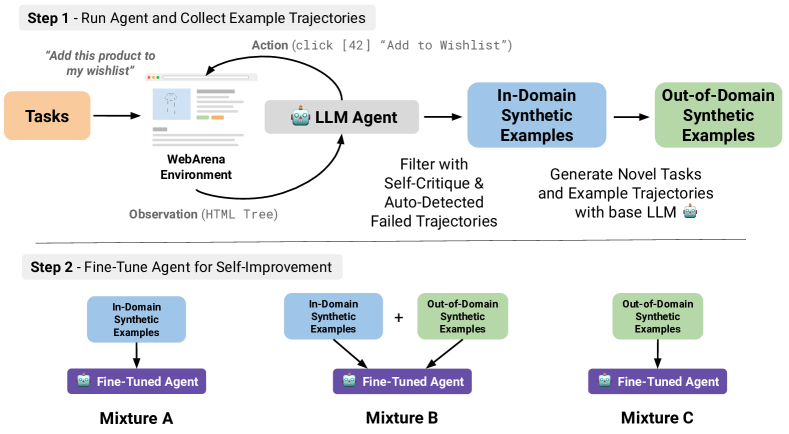

📊 实验亮点
实验结果表明,通过自学习,LLM在WebArena基准测试中任务完成率提升了31%。此外,论文提出的新评估指标能够更全面地评估Agent的性能和能力,为后续研究提供了参考。
🎯 应用场景
该研究成果可应用于开发更智能、更自主的Web Agent,例如智能助手、自动化测试工具、信息检索系统等。这些Agent能够自主地在Web环境中导航、执行任务,从而提高工作效率、降低人工成本。未来,该方法还可以扩展到其他复杂环境,例如机器人导航、游戏AI等。
📄 摘要(原文)
Training models to act as agents that can effectively navigate and perform actions in a complex environment, such as a web browser, has typically been challenging due to lack of training data. Large language models (LLMs) have recently demonstrated some capability to navigate novel environments as agents in a zero-shot or few-shot fashion, purely guided by natural language instructions as prompts. Recent research has also demonstrated LLMs have the capability to exceed their base performance through self-improvement, i.e. fine-tuning on data generated by the model itself. In this work, we explore the extent to which LLMs can self-improve their performance as agents in long-horizon tasks in a complex environment using the WebArena benchmark. In WebArena, an agent must autonomously navigate and perform actions on web pages to achieve a specified objective. We explore fine-tuning on three distinct synthetic training data mixtures and achieve a 31\% improvement in task completion rate over the base model on the WebArena benchmark through a self-improvement procedure. We additionally contribute novel evaluation metrics for assessing the performance, robustness, capabilities, and quality of trajectories of our fine-tuned agent models to a greater degree than simple, aggregate-level benchmark scores currently used to measure self-improvement.