Kernel Language Entropy: Fine-grained Uncertainty Quantification for LLMs from Semantic Similarities
作者: Alexander Nikitin, Jannik Kossen, Yarin Gal, Pekka Marttinen
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-05-30
💡 一句话要点
提出Kernel Language Entropy (KLE),用于量化大型语言模型中细粒度的语义不确定性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 不确定性量化 语义相似性 核方法 冯·诺依曼熵
📋 核心要点
- 现有LLM不确定性量化方法难以捕捉语义层面的不确定性,易受词汇或句法变异干扰。
- KLE通过定义核函数编码LLM输出的语义相似性,并使用冯·诺依曼熵进行不确定性量化。
- 实验表明,KLE在多个数据集和LLM架构上,提升了不确定性量化性能,优于现有方法。
📝 摘要(中文)
大型语言模型(LLM)中的不确定性量化对于安全性和可靠性至关重要的应用至关重要。特别地,不确定性可以用于通过检测模型在事实上不正确的响应(通常称为幻觉)来提高LLM的可信度。关键在于,应该寻求捕获模型的语义不确定性,即LLM输出含义的不确定性,而不是不影响答案正确性的词汇或句法变异的不确定性。为了解决这个问题,我们提出了一种用于白盒和黑盒LLM中不确定性估计的新方法Kernel Language Entropy (KLE)。KLE定义了半正定单位迹核来编码LLM输出的语义相似性,并使用冯·诺依曼熵来量化不确定性。它考虑了答案(或语义簇)之间的成对语义依赖关系,从而提供了比以前基于答案硬聚类的方法更细粒度的不确定性估计。我们从理论上证明了KLE推广了先前的最先进方法,即语义熵,并通过实验证明,它提高了跨多个自然语言生成数据集和LLM架构的不确定性量化性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中不确定性量化的问题,特别是语义不确定性。现有的方法通常关注词汇或句法层面的差异,而忽略了语义上的相似性,导致无法准确评估模型对答案含义的置信度。这种不准确的不确定性量化会影响LLM在安全性和可靠性要求高的场景中的应用。
核心思路:论文的核心思路是利用核方法来捕捉LLM输出之间的语义相似性,并使用冯·诺依曼熵来量化这种相似性分布的不确定性。通过考虑答案之间的成对语义依赖关系,KLE能够提供比传统方法更细粒度的不确定性估计,从而更准确地反映模型对答案含义的置信度。
技术框架:KLE方法主要包含以下几个阶段:1) 从LLM生成多个候选答案;2) 使用预训练的语义相似度模型(如Sentence-BERT)计算答案之间的语义相似度;3) 构建一个半正定单位迹核,该核编码了答案之间的语义相似性;4) 使用冯·诺依曼熵计算核矩阵的熵,作为不确定性的度量。
关键创新:KLE的关键创新在于使用核方法来编码LLM输出的语义相似性,并使用冯·诺依曼熵来量化不确定性。与传统的基于硬聚类的方法相比,KLE考虑了答案之间的成对语义依赖关系,从而提供了更细粒度的不确定性估计。此外,论文从理论上证明了KLE推广了先前的最先进方法,即语义熵。
关键设计:KLE的关键设计包括:1) 使用半正定单位迹核来保证核矩阵的有效性;2) 使用冯·诺依曼熵来量化核矩阵的熵,该熵对相似性分布的微小变化敏感;3) 使用预训练的语义相似度模型来计算答案之间的语义相似度,避免了手动设计特征的需要。论文没有明确指出具体的参数设置或网络结构,而是侧重于方法的整体框架和理论分析。
🖼️ 关键图片

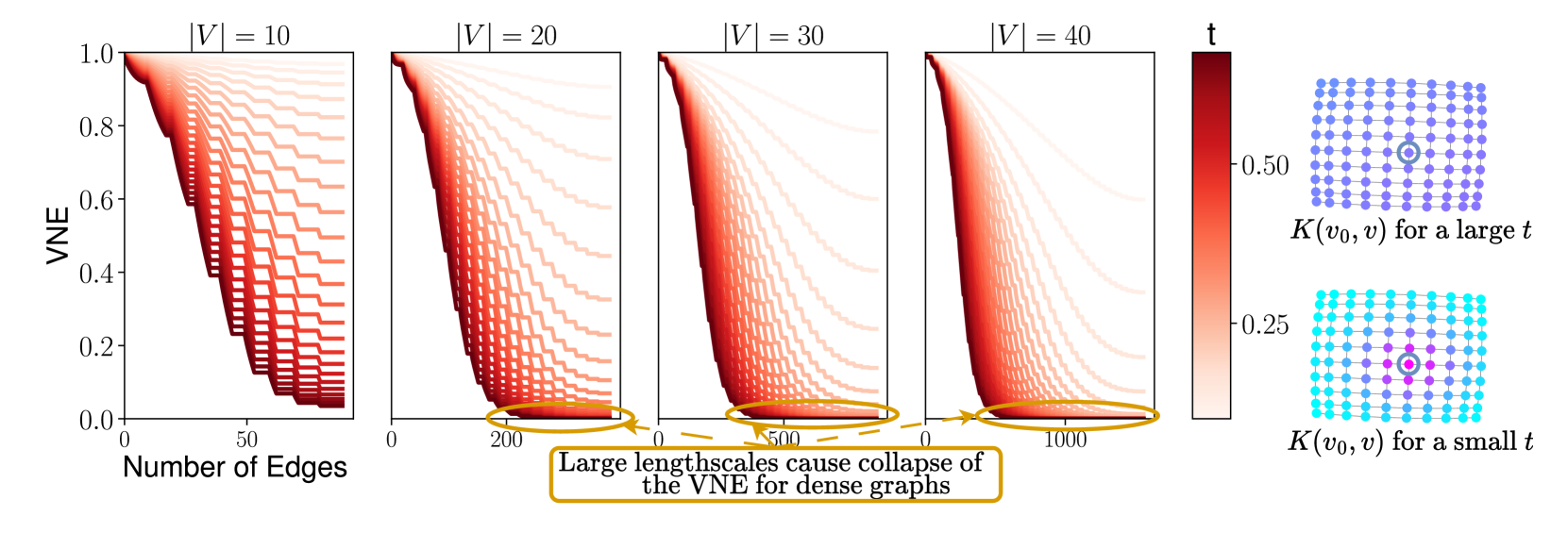
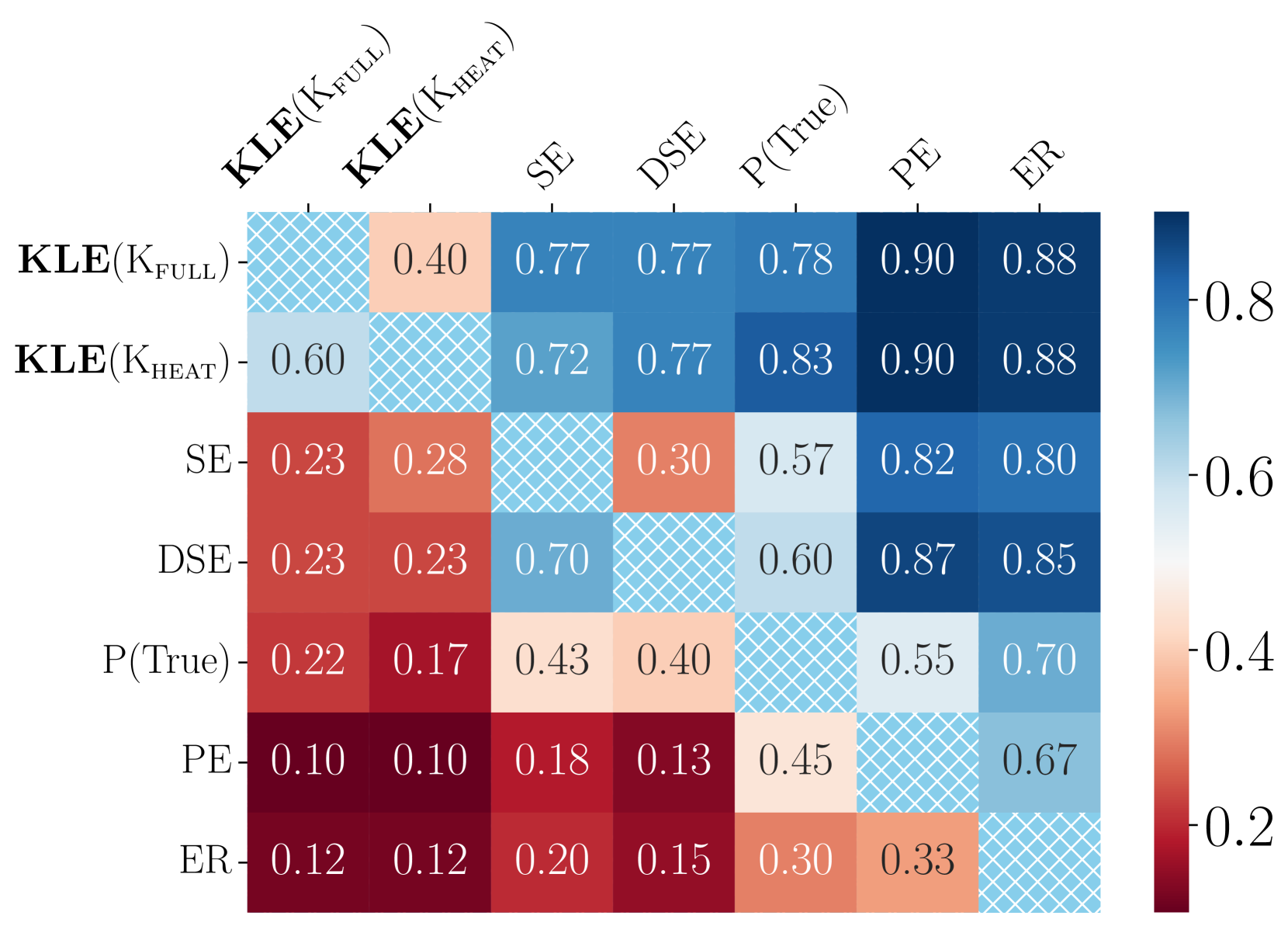
📊 实验亮点
实验结果表明,KLE在多个自然语言生成数据集和LLM架构上,都优于现有的不确定性量化方法。具体来说,KLE在检测LLM的幻觉方面表现出色,能够更准确地识别模型在事实上不正确的响应。论文还证明了KLE推广了先前的最先进方法,即语义熵,并在实验中验证了KLE的有效性。
🎯 应用场景
KLE可应用于各种需要高安全性和可靠性的LLM应用场景,例如医疗诊断、金融风险评估、法律咨询等。通过准确量化模型的不确定性,KLE可以帮助用户识别模型可能出错的情况,从而避免潜在的风险。此外,KLE还可以用于提高LLM的可解释性,帮助用户理解模型做出决策的原因。
📄 摘要(原文)
Uncertainty quantification in Large Language Models (LLMs) is crucial for applications where safety and reliability are important. In particular, uncertainty can be used to improve the trustworthiness of LLMs by detecting factually incorrect model responses, commonly called hallucinations. Critically, one should seek to capture the model's semantic uncertainty, i.e., the uncertainty over the meanings of LLM outputs, rather than uncertainty over lexical or syntactic variations that do not affect answer correctness. To address this problem, we propose Kernel Language Entropy (KLE), a novel method for uncertainty estimation in white- and black-box LLMs. KLE defines positive semidefinite unit trace kernels to encode the semantic similarities of LLM outputs and quantifies uncertainty using the von Neumann entropy. It considers pairwise semantic dependencies between answers (or semantic clusters), providing more fine-grained uncertainty estimates than previous methods based on hard clustering of answers. We theoretically prove that KLE generalizes the previous state-of-the-art method called semantic entropy and empirically demonstrate that it improves uncertainty quantification performance across multiple natural language generation datasets and LLM architectures.