Learning from Random Demonstrations: Offline Reinforcement Learning with Importance-Sampled Diffusion Models
作者: Zeyu Fang, Tian Lan
分类: cs.LG, cs.GT
发布日期: 2024-05-30
💡 一句话要点
提出基于重要性采样的扩散模型离线强化学习方法,提升随机数据下的策略学习效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 扩散模型 重要性采样 世界模型 策略评估
📋 核心要点
- 现有离线强化学习方法依赖预训练或在线更新的扩散模型,难以有效利用随机数据进行策略学习。
- 论文提出一种迭代式方法,通过引导扩散模型评估策略并进行重要性采样更新,实现世界模型与策略的自适应对齐。
- 实验表明,该方法在D4RL数据集上优于现有方法,尤其在随机或中等水平数据下,性能提升显著。
📝 摘要(中文)
本文提出了一种新颖的离线强化学习方法,该方法采用闭环策略评估和世界模型自适应。它迭代地利用引导扩散世界模型,通过从中抽取的动作直接评估离线目标策略,然后执行重要性采样的世界模型更新,以自适应地将世界模型与更新后的策略对齐。论文分析了该方法的性能,并提供了在最优策略下,该方法与真实环境之间回报差距的上界,揭示了影响学习性能的各种因素。在D4RL环境中的评估表明,该方法比最先进的基线方法有显著改进,尤其是在只有随机或中等水平的演示数据可用时,这需要世界模型和离线策略评估之间更好的对齐。
🔬 方法详解
问题定义:离线强化学习旨在利用静态数据集学习最优策略,而无需与环境交互。现有方法在数据质量不高(如随机数据)时,难以准确评估策略,导致学习效果不佳。扩散模型作为世界模型,可以生成合成数据,但如何使其与目标策略对齐,从而更有效地进行策略评估,是一个关键问题。
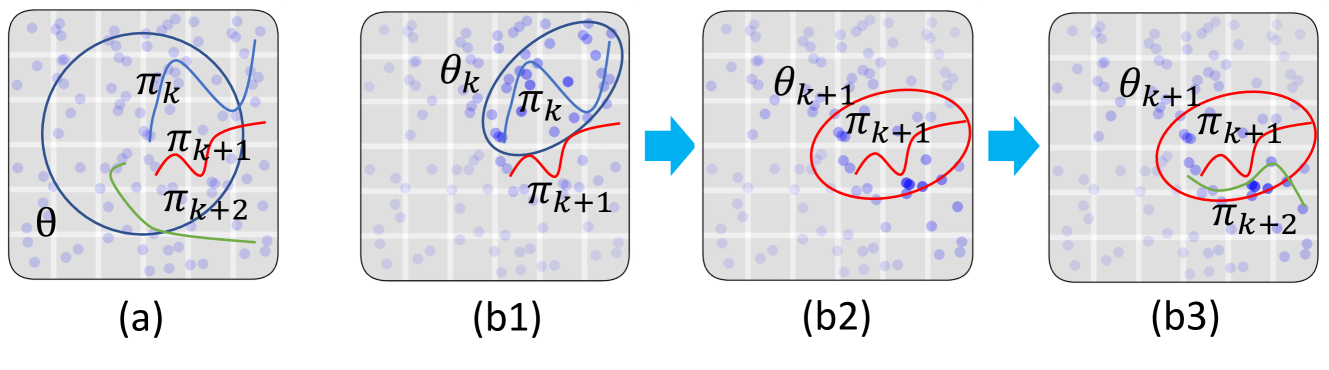
核心思路:论文的核心思路是迭代地进行策略评估和世界模型更新。首先,利用扩散模型生成动作,评估当前策略。然后,通过重要性采样,根据策略与扩散模型生成动作的概率差异,调整世界模型,使其更好地拟合目标策略。这种闭环反馈机制能够自适应地提升世界模型的准确性,从而改善策略学习效果。
技术框架:整体框架包含以下两个主要阶段:1) 策略评估:利用引导扩散世界模型生成动作,并使用这些动作评估离线目标策略。2) 世界模型更新:通过重要性采样,根据策略和扩散模型生成动作的概率差异,更新扩散世界模型,使其更好地与目标策略对齐。这两个阶段迭代进行,直至收敛。
关键创新:最重要的创新点在于将重要性采样引入到扩散世界模型的更新中。传统方法通常直接训练扩散模型拟合离线数据集,而忽略了策略与数据分布的差异。通过重要性采样,可以根据策略的优劣,调整扩散模型的学习权重,从而更有效地利用离线数据,提升策略评估的准确性。
关键设计:论文使用扩散模型作为世界模型,具体实现细节未知。重要性采样的权重计算基于策略和扩散模型生成动作的概率之比。损失函数的设计目标是最小化更新后的扩散模型与目标策略之间的差异。具体的网络结构和参数设置在论文中可能有所描述,但此处未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在D4RL数据集上显著优于现有基线方法,尤其是在使用随机或中等水平的演示数据时。具体性能提升数据未知,但论文强调了在这些数据条件下,该方法能够更好地对齐世界模型和离线策略评估,从而实现更有效的策略学习。
🎯 应用场景
该研究成果可应用于机器人离线学习、自动驾驶策略优化、游戏AI等领域。通过利用低质量或随机数据,可以降低数据采集成本,加速智能系统的开发和部署。该方法在医疗、金融等高风险领域也具有潜在应用价值,可以在离线数据上安全地学习策略,避免直接与真实环境交互带来的风险。
📄 摘要(原文)
Generative models such as diffusion have been employed as world models in offline reinforcement learning to generate synthetic data for more effective learning. Existing work either generates diffusion models one-time prior to training or requires additional interaction data to update it. In this paper, we propose a novel approach for offline reinforcement learning with closed-loop policy evaluation and world-model adaptation. It iteratively leverages a guided diffusion world model to directly evaluate the offline target policy with actions drawn from it, and then performs an importance-sampled world model update to adaptively align the world model with the updated policy. We analyzed the performance of the proposed method and provided an upper bound on the return gap between our method and the real environment under an optimal policy. The result sheds light on various factors affecting learning performance. Evaluations in the D4RL environment show significant improvement over state-of-the-art baselines, especially when only random or medium-expertise demonstrations are available -- thus requiring improved alignment between the world model and offline policy evaluation.