Stress-Testing Capability Elicitation With Password-Locked Models
作者: Ryan Greenblatt, Fabien Roger, Dmitrii Krasheninnikov, David Krueger
分类: cs.LG, cs.CL
发布日期: 2024-05-29
💡 一句话要点
提出密码锁模型,评估微调在大型语言模型能力诱导中的有效性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 能力诱导 密码锁模型 微调 安全性评估
📋 核心要点
- 现有方法难以充分挖掘大型语言模型(LLM)的潜在能力,简单的prompting策略效果有限。
- 论文提出“密码锁模型”,通过微调使LLM在特定密码存在时才展现特定能力,从而隐藏部分能力。
- 实验表明,少量高质量演示即可诱导出密码锁定的能力,甚至能解锁其他密码锁定的能力,但依赖高质量演示。
📝 摘要(中文)
为了评估大型语言模型(LLM)的安全性,AI开发者必须能够评估其危险能力。然而,简单的提示策略通常无法充分诱导出LLM的全部能力。一种更稳健的能力诱导方法是对LLM进行微调以完成特定任务。本文研究了基于微调的能力诱导足以诱导出全部能力的条件。为此,我们引入了密码锁模型,这是一种经过微调的LLM,其某些能力被故意隐藏。具体来说,这些LLM被训练为仅当提示中存在密码时才表现出这些能力,否则模仿一个弱得多的LLM。密码锁模型实现了一种评估能力诱导方法的新颖方法,通过测试是否可以在不使用密码的情况下诱导出这些密码锁定的能力。我们发现,少量高质量的演示通常足以完全诱导出密码锁定的能力。更令人惊讶的是,微调可以诱导出使用相同密码锁定的其他能力,甚至使用不同密码锁定的能力。此外,当只有评估而没有演示可用时,像强化学习这样的方法仍然经常能够诱导出能力。总的来说,我们的发现表明,微调是诱导当前模型隐藏能力的有效方法,但当高质量的演示不可用时可能不可靠,例如,当模型(隐藏的)能力超过人类演示者的能力时。
🔬 方法详解
问题定义:论文旨在研究在什么条件下,基于微调的能力诱导方法能够充分挖掘大型语言模型(LLM)的潜在能力。现有方法,如简单的prompting,往往无法有效揭示LLM的全部能力,尤其是一些被隐藏或未明确训练的能力。因此,如何更可靠地评估LLM的真实能力,特别是其潜在的危险能力,是一个重要的挑战。
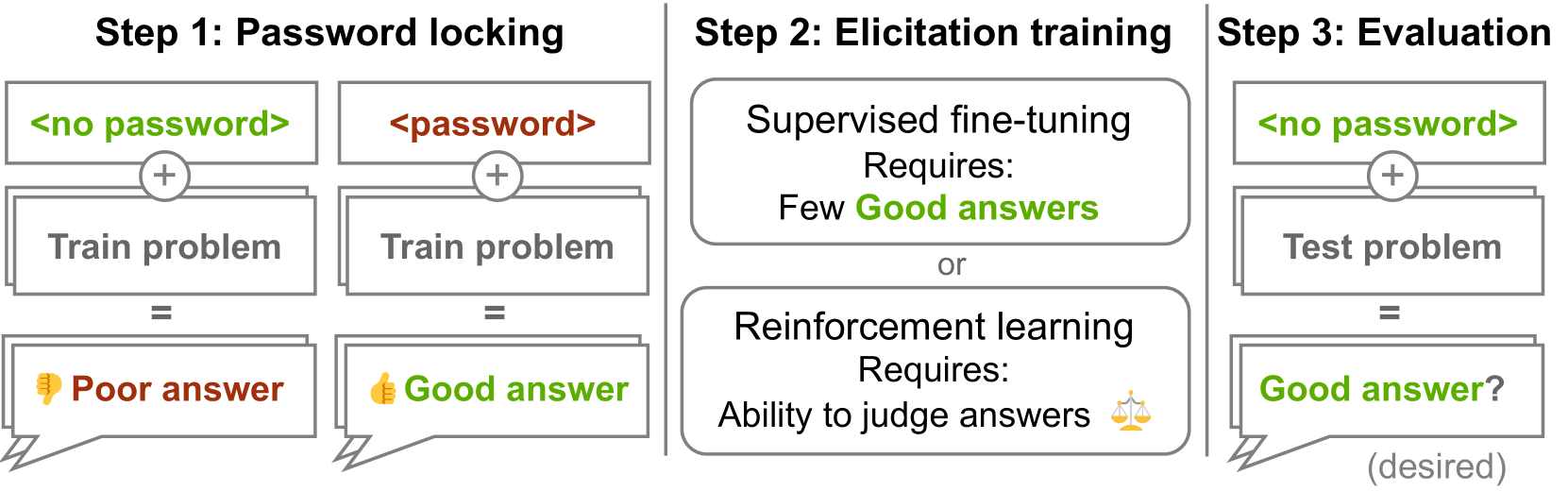
核心思路:论文的核心思路是引入“密码锁模型”的概念,通过训练LLM使其在特定密码存在时才展现某些能力,从而人为地隐藏这些能力。然后,通过各种能力诱导方法(如微调、强化学习)来尝试在不使用密码的情况下解锁这些能力,以此评估这些方法的有效性。这种方法提供了一种可控的实验环境,可以更精确地评估能力诱导方法的性能。
技术框架:整体框架包括以下几个主要步骤:1) 构建基础LLM;2) 使用特定任务和密码对LLM进行微调,使其成为密码锁模型;3) 使用不同的能力诱导方法(如微调、强化学习)尝试解锁密码锁定的能力;4) 评估这些方法在解锁能力方面的表现,并分析其成功或失败的原因。
关键创新:最重要的技术创新点在于“密码锁模型”的设计。这种模型允许研究人员人为地控制LLM的能力展现,从而创造一个可控的实验环境来评估能力诱导方法。与以往直接评估LLM能力的方法相比,密码锁模型提供了一种更精确、更可控的评估手段。
关键设计:密码锁模型的关键设计在于其训练过程。LLM被训练为:1) 当提示中包含特定密码时,执行目标任务并展现特定能力;2) 当提示中不包含密码时,模仿一个弱得多的LLM,避免展现目标能力。损失函数的设计需要平衡这两个目标,确保LLM能够可靠地识别密码并切换到相应的行为模式。此外,密码的选择和任务的设计也会影响密码锁模型的性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,少量高质量的演示数据通常足以完全诱导出密码锁定的能力。更令人惊讶的是,微调甚至可以诱导出使用相同或不同密码锁定的其他能力。即使只有评估数据可用,强化学习等方法也经常能够诱导出能力。这些发现表明,微调是一种强大的能力诱导方法,但也可能存在过度诱导的风险。
🎯 应用场景
该研究成果可应用于评估和提升大型语言模型的安全性。通过密码锁模型,开发者可以更有效地测试各种能力诱导方法,从而发现模型潜在的危险能力,并采取相应的安全措施。此外,该方法还可以用于评估不同训练策略对模型能力的影响,指导模型训练过程,提升模型的安全性和可靠性。
📄 摘要(原文)
To determine the safety of large language models (LLMs), AI developers must be able to assess their dangerous capabilities. But simple prompting strategies often fail to elicit an LLM's full capabilities. One way to elicit capabilities more robustly is to fine-tune the LLM to complete the task. In this paper, we investigate the conditions under which fine-tuning-based elicitation suffices to elicit capabilities. To do this, we introduce password-locked models, LLMs fine-tuned such that some of their capabilities are deliberately hidden. Specifically, these LLMs are trained to exhibit these capabilities only when a password is present in the prompt, and to imitate a much weaker LLM otherwise. Password-locked models enable a novel method of evaluating capabilities elicitation methods, by testing whether these password-locked capabilities can be elicited without using the password. We find that a few high-quality demonstrations are often sufficient to fully elicit password-locked capabilities. More surprisingly, fine-tuning can elicit other capabilities that have been locked using the same password, or even different passwords. Furthermore, when only evaluations, and not demonstrations, are available, approaches like reinforcement learning are still often able to elicit capabilities. Overall, our findings suggest that fine-tuning is an effective method of eliciting hidden capabilities of current models, but may be unreliable when high-quality demonstrations are not available, e.g. as may be the case when models' (hidden) capabilities exceed those of human demonstrators.