Self-Exploring Language Models: Active Preference Elicitation for Online Alignment
作者: Shenao Zhang, Donghan Yu, Hiteshi Sharma, Han Zhong, Zhihan Liu, Ziyi Yang, Shuohang Wang, Hany Hassan, Zhaoran Wang
分类: cs.LG, cs.AI
发布日期: 2024-05-29 (更新: 2024-11-05)
🔗 代码/项目: GITHUB
💡 一句话要点
提出自探索语言模型(SELM),通过主动偏好诱导实现LLM的在线对齐。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 人类反馈强化学习 偏好优化 在线对齐 主动探索
📋 核心要点
- 现有RLHF方法依赖随机抽样,难以充分探索自然语言空间,导致奖励模型不够准确。
- SELM通过双层优化目标,主动探索潜在高奖励的分布外区域,提升探索效率。
- 实验表明,SELM在指令遵循和学术基准上显著优于DPO,提升了LLM的性能。
📝 摘要(中文)
偏好优化,特别是通过人类反馈强化学习(RLHF),在使大型语言模型(LLM)符合人类意图方面取得了显著成功。与使用固定数据集的离线对齐不同,从人类或AI处在线收集关于模型生成的反馈,通常会通过迭代过程产生更强大的奖励模型和更好对齐的LLM。然而,要获得全局准确的奖励模型,需要系统地探索以生成跨越广阔自然语言空间的多样化响应。仅从标准的奖励最大化LLM中随机抽样不足以满足这一要求。为了解决这个问题,我们提出了一种双层目标,乐观地偏向于潜在的高奖励响应,以主动探索分布外区域。通过使用重新参数化的奖励函数解决内部问题,由此产生的算法,名为自探索语言模型(SELM),消除了对单独的RM的需求,并通过一个简单的目标迭代更新LLM。与直接偏好优化(DPO)相比,SELM目标减少了对未见过的外推的不加区分的偏爱,并提高了探索效率。我们的实验结果表明,当在Zephyr-7B-SFT和Llama-3-8B-Instruct模型上进行微调时,SELM显著提高了指令遵循基准(如MT-Bench和AlpacaEval 2.0)以及不同设置下的各种标准学术基准的性能。我们的代码和模型可在https://github.com/shenao-zhang/SELM获得。
🔬 方法详解
问题定义:现有基于人类反馈的强化学习(RLHF)方法,在训练大型语言模型(LLM)时,依赖于从奖励模型中采样生成回复,然后进行偏好学习。然而,这种随机采样策略难以充分探索整个自然语言空间,导致奖励模型可能存在偏差,尤其是在分布外(out-of-distribution)区域,从而限制了LLM的对齐效果。现有方法难以兼顾探索的广度和效率。
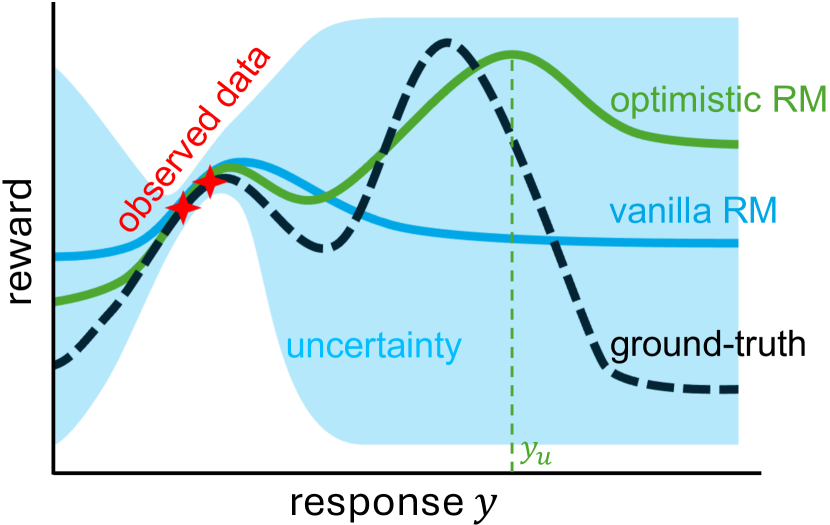
核心思路:SELM的核心思路是通过一个双层优化目标,引导LLM主动探索那些可能获得高奖励但尚未被充分探索的区域。具体来说,SELM采用一种乐观偏向(optimistically biased)的策略,鼓励模型生成更具多样性的回复,从而更全面地了解奖励函数的真实情况。这种主动探索机制旨在克服随机采样的局限性,提高奖励模型的准确性和泛化能力。
技术框架:SELM的整体框架包含以下几个关键步骤:1) 初始化LLM;2) 使用双层优化目标迭代更新LLM,其中内层优化问题旨在寻找给定奖励函数下的最优回复,外层优化问题则鼓励模型探索未知的、可能高奖励的区域;3) 在每次迭代中,模型生成回复并收集反馈(可以是人类反馈或AI反馈);4) 基于收集到的反馈更新奖励模型和LLM。与传统的RLHF方法不同,SELM不需要单独的奖励模型,而是通过重新参数化的奖励函数直接优化LLM。
关键创新:SELM最重要的技术创新点在于其双层优化目标和自探索机制。与传统的RLHF方法相比,SELM不是被动地从奖励模型中采样,而是主动地探索未知的、可能高奖励的区域。这种自探索机制能够更有效地发现和利用潜在的优质回复,从而提高奖励模型的准确性和LLM的对齐效果。此外,SELM通过重新参数化的奖励函数,消除了对单独奖励模型的依赖,简化了训练流程。
关键设计:SELM的关键设计包括:1) 双层优化目标:外层目标鼓励探索,内层目标最大化奖励;2) 重新参数化的奖励函数,直接作用于LLM;3) 乐观偏向策略,鼓励模型生成多样性回复。具体的损失函数设计需要平衡探索和利用,避免模型过度关注已知的、低奖励的区域,同时也要防止模型生成过于离谱的回复。参数设置方面,需要仔细调整内外层优化器的学习率和迭代次数,以确保训练的稳定性和收敛性。
🖼️ 关键图片
📊 实验亮点
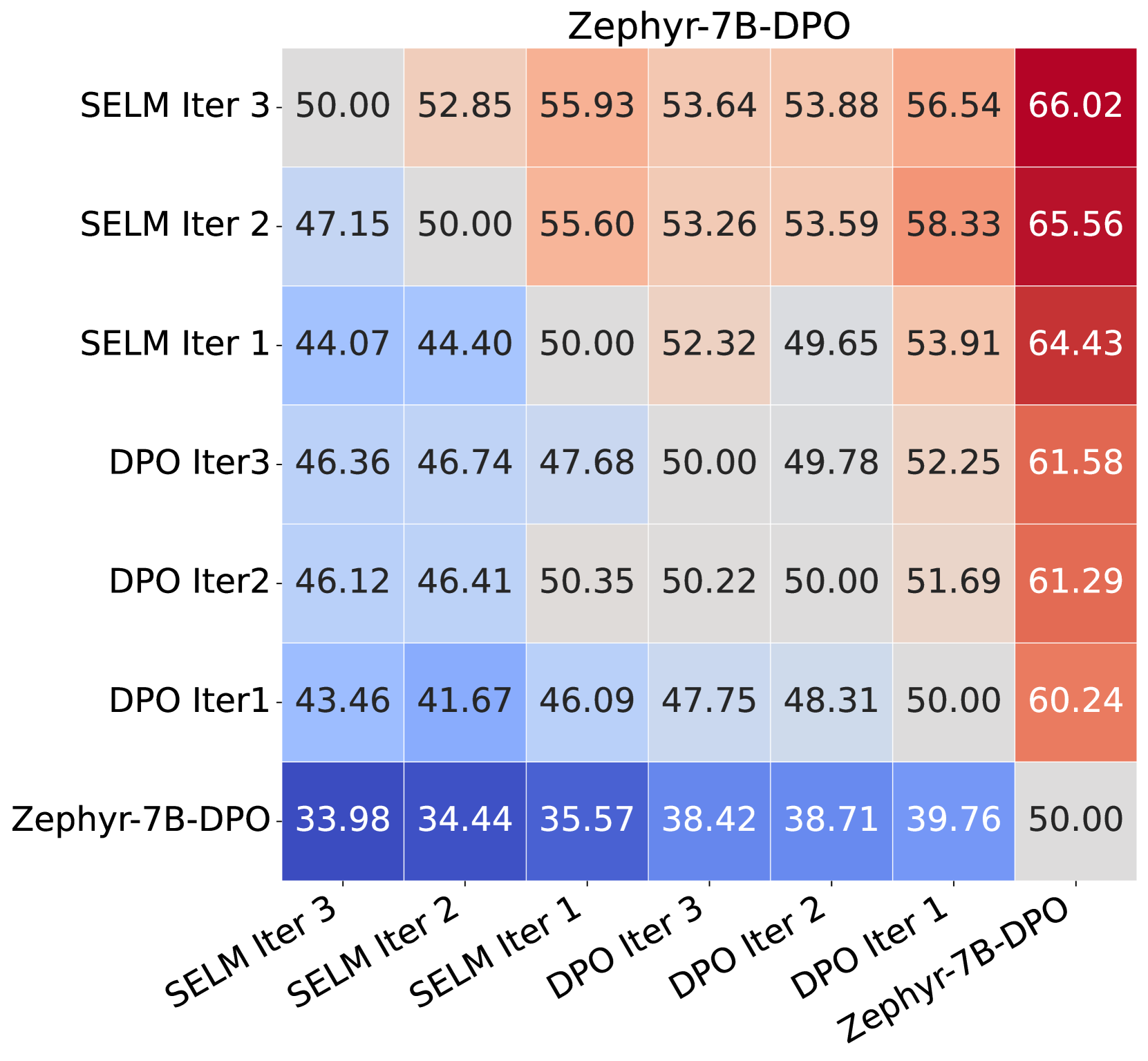
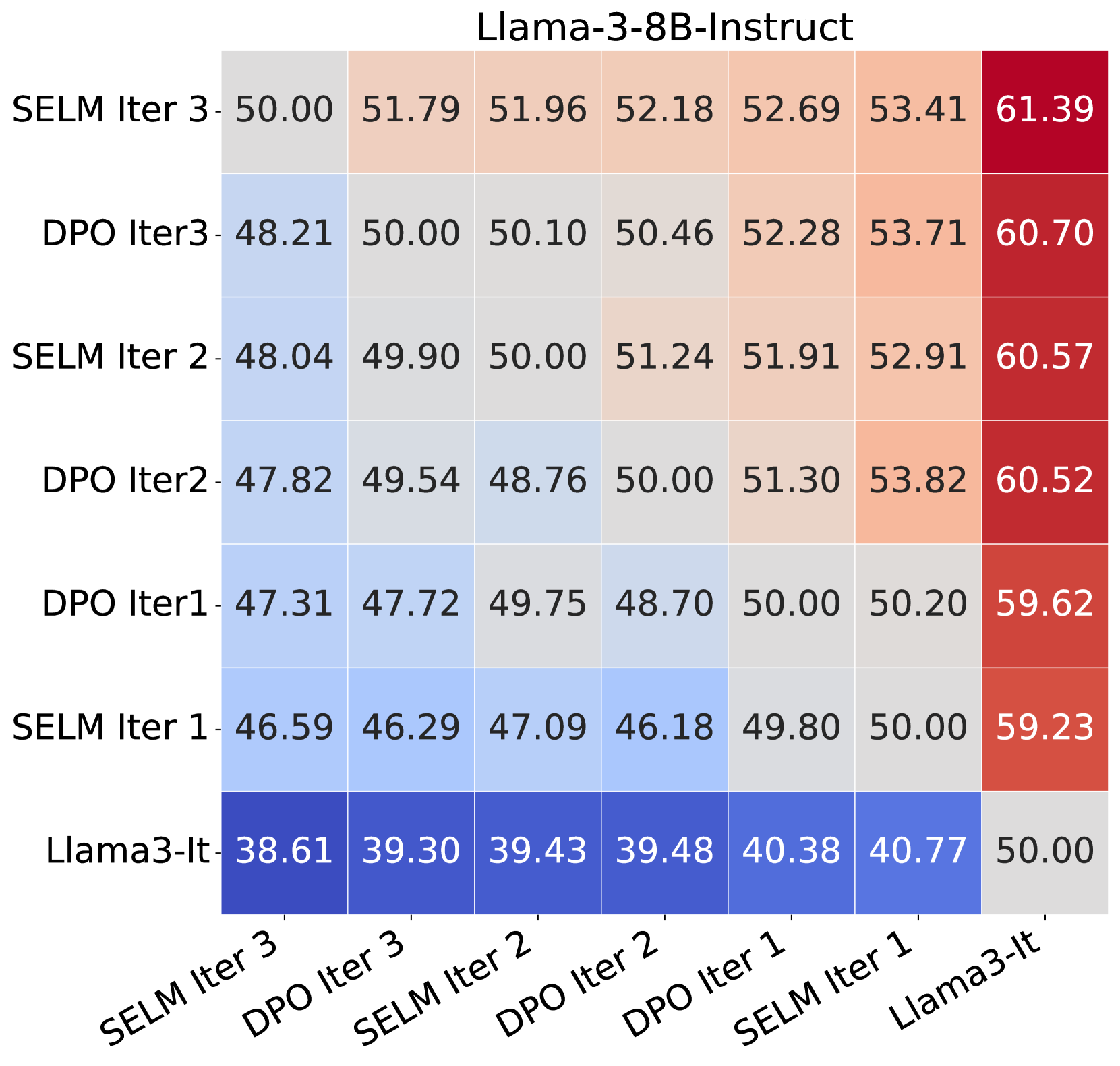
实验结果表明,在Zephyr-7B-SFT和Llama-3-8B-Instruct模型上进行微调后,SELM在MT-Bench和AlpacaEval 2.0等指令遵循基准上取得了显著提升。与DPO相比,SELM能够更有效地探索未知的、可能高奖励的区域,从而提高奖励模型的准确性和LLM的对齐效果。具体性能提升数据需要在论文中查找。
🎯 应用场景
SELM可应用于各种需要LLM与人类意图对齐的场景,例如智能助手、对话系统、内容生成等。通过主动探索和优化,SELM能够使LLM更好地理解用户需求,生成更符合人类偏好和价值观的回复,从而提高用户满意度和信任度。此外,SELM还可以应用于教育、医疗等领域,帮助LLM更好地服务于人类社会。
📄 摘要(原文)
Preference optimization, particularly through Reinforcement Learning from Human Feedback (RLHF), has achieved significant success in aligning Large Language Models (LLMs) to adhere to human intentions. Unlike offline alignment with a fixed dataset, online feedback collection from humans or AI on model generations typically leads to more capable reward models and better-aligned LLMs through an iterative process. However, achieving a globally accurate reward model requires systematic exploration to generate diverse responses that span the vast space of natural language. Random sampling from standard reward-maximizing LLMs alone is insufficient to fulfill this requirement. To address this issue, we propose a bilevel objective optimistically biased towards potentially high-reward responses to actively explore out-of-distribution regions. By solving the inner-level problem with the reparameterized reward function, the resulting algorithm, named Self-Exploring Language Models (SELM), eliminates the need for a separate RM and iteratively updates the LLM with a straightforward objective. Compared to Direct Preference Optimization (DPO), the SELM objective reduces indiscriminate favor of unseen extrapolations and enhances exploration efficiency. Our experimental results demonstrate that when fine-tuned on Zephyr-7B-SFT and Llama-3-8B-Instruct models, SELM significantly boosts the performance on instruction-following benchmarks such as MT-Bench and AlpacaEval 2.0, as well as various standard academic benchmarks in different settings. Our code and models are available at https://github.com/shenao-zhang/SELM.