DiveR-CT: Diversity-enhanced Red Teaming Large Language Model Assistants with Relaxing Constraints
作者: Andrew Zhao, Quentin Xu, Matthieu Lin, Shenzhi Wang, Yong-jin Liu, Zilong Zheng, Gao Huang
分类: cs.LG, cs.AI, cs.CL, cs.CR
发布日期: 2024-05-29 (更新: 2024-12-20)
备注: Accepted by the 39th Annual AAAI Conference on Artificial Intelligence (AAAI-25)
💡 一句话要点
DiveR-CT:通过放宽约束增强多样性的大语言模型助手红队测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 红队测试 大语言模型 安全性 多样性 强化学习 对抗样本 安全评估
📋 核心要点
- 现有红队测试方法侧重于最大化攻击成功率,忽略了生成对抗样本的多样性,导致测试覆盖范围有限。
- DiveR-CT通过放宽目标和语义奖励的约束,赋予策略更大的自由度,从而生成更多样化的对抗样本。
- 实验证明,DiveR-CT在多样性指标、蓝队模型弹性增强和攻击成功率控制方面均优于现有方法。
📝 摘要(中文)
大型语言模型助手(LLM)的快速发展使其变得不可或缺,但也引发了对其安全性的担忧。自动红队测试为人工漏洞探测提供了一种有前景的替代方案,它更一致且可扩展。然而,现有方法通常以牺牲多样性为代价来最大化攻击成功率。此外,通过降低与历史嵌入的余弦相似度来获得语义多样性奖励的方法,会随着历史的增长而导致新颖性停滞。为了解决这些问题,我们提出了DiveR-CT,它放宽了对目标和语义奖励的传统约束,从而为策略提供了更大的自由度来增强多样性。实验表明,DiveR-CT明显优于基线,具体体现在:1)生成的数据在不同攻击成功率水平下,在各种多样性指标上表现更好;2)通过基于收集的数据进行安全调整,更好地增强了蓝队模型的弹性;3)允许动态控制目标权重,以实现可靠且可控的攻击成功率;4)降低了对奖励过度优化的敏感性。总而言之,我们的方法为LLM红队测试提供了一种有效且高效的方法,加速了实际部署。
🔬 方法详解
问题定义:现有的大语言模型红队测试方法,为了追求高攻击成功率,往往会生成相似的对抗样本,导致测试的多样性不足,无法充分挖掘模型的潜在漏洞。此外,基于降低历史嵌入相似度来鼓励多样性的方法,会随着历史样本的积累而陷入新颖性停滞。
核心思路:DiveR-CT的核心思路是通过放宽对目标函数和语义奖励的约束,允许红队策略探索更广阔的对抗样本空间,从而生成更多样化的攻击。这种方法旨在打破传统红队测试中“一味追求成功率”的局限,鼓励策略探索更具创造性和新颖性的攻击方式。
技术框架:DiveR-CT的整体框架基于强化学习,红队策略作为Agent,与大语言模型助手(LLM)进行交互。Agent生成对抗性提示,LLM给出回应,然后根据攻击是否成功以及生成提示的多样性给予Agent奖励。DiveR-CT的关键在于对奖励函数的改进,通过放宽约束,鼓励Agent探索更多样化的提示。
关键创新:DiveR-CT的关键创新在于放宽了对目标函数和语义奖励的约束。具体来说,传统方法通常会严格限制目标函数,例如要求攻击必须成功,而DiveR-CT允许一定程度的攻击失败,只要生成的提示具有足够的多样性。此外,DiveR-CT还改进了语义奖励的计算方式,避免了因历史样本积累而导致的新颖性停滞。
关键设计:DiveR-CT的关键设计包括:1) 对目标函数的约束放宽程度,例如允许一定比例的攻击失败;2) 语义奖励的计算方式,例如使用更鲁棒的语义相似度度量方法,或者引入探索奖励;3) 强化学习算法的选择,例如使用PPO等算法来训练红队策略;4) 动态调整目标权重,以便在攻击成功率和多样性之间进行权衡。
🖼️ 关键图片

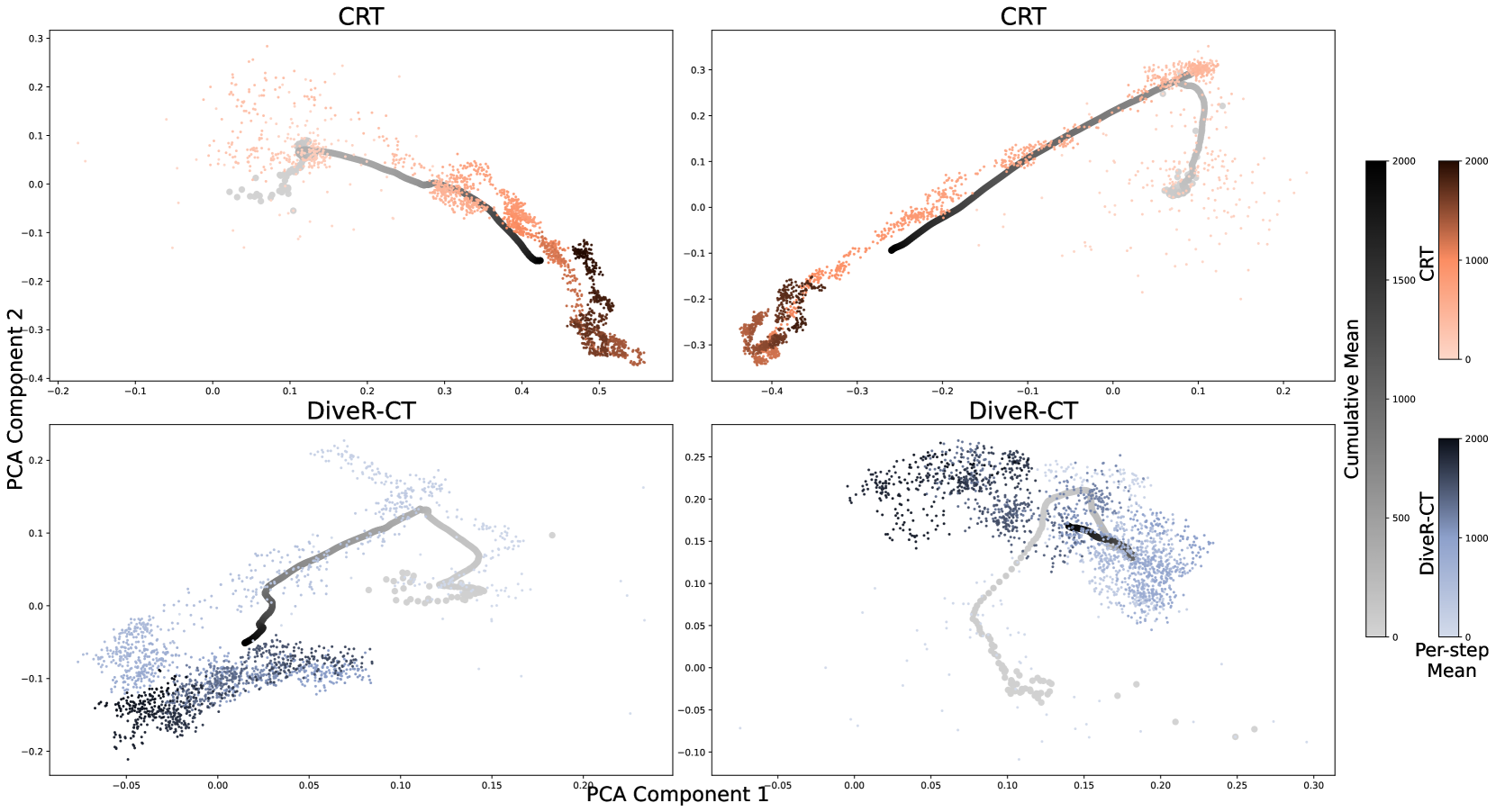
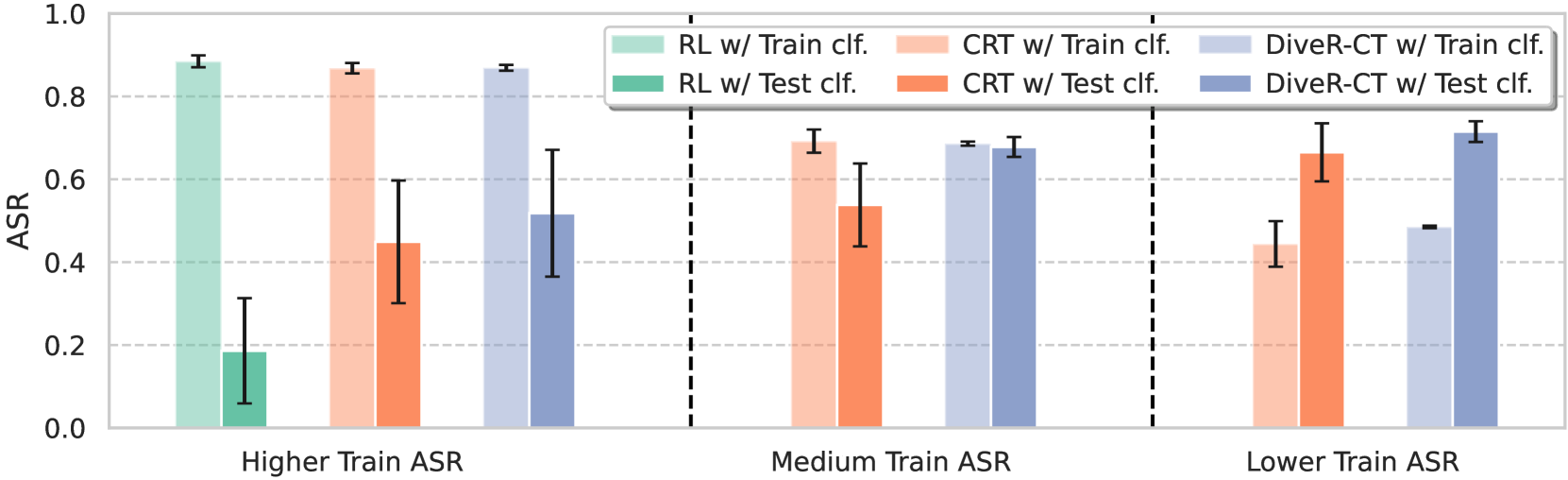
📊 实验亮点
实验结果表明,DiveR-CT在生成对抗样本的多样性方面显著优于现有方法。具体来说,DiveR-CT在不同的攻击成功率水平下,在各种多样性指标(例如,Self-BLEU、Pairwise-BLEU)上均取得了更好的表现。此外,基于DiveR-CT生成的数据进行安全调整后,蓝队模型的弹性得到了显著提升。DiveR-CT还允许动态控制目标权重,从而实现可靠且可控的攻击成功率。
🎯 应用场景
DiveR-CT可应用于各种大语言模型助手的安全评估和红队测试,帮助开发者发现和修复潜在的安全漏洞,提高模型的鲁棒性和安全性。该方法还可以用于生成更具挑战性的对抗训练数据,从而提升模型的防御能力。此外,该方法可以扩展到其他类型的AI系统,例如图像识别和语音识别系统。
📄 摘要(原文)
Recent advances in large language model assistants have made them indispensable, raising significant concerns over managing their safety. Automated red teaming offers a promising alternative to the labor-intensive and error-prone manual probing for vulnerabilities, providing more consistent and scalable safety evaluations. However, existing approaches often compromise diversity by focusing on maximizing attack success rate. Additionally, methods that decrease the cosine similarity from historical embeddings with semantic diversity rewards lead to novelty stagnation as history grows. To address these issues, we introduce DiveR-CT, which relaxes conventional constraints on the objective and semantic reward, granting greater freedom for the policy to enhance diversity. Our experiments demonstrate DiveR-CT's marked superiority over baselines by 1) generating data that perform better in various diversity metrics across different attack success rate levels, 2) better-enhancing resiliency in blue team models through safety tuning based on collected data, 3) allowing dynamic control of objective weights for reliable and controllable attack success rates, and 4) reducing susceptibility to reward overoptimization. Overall, our method provides an effective and efficient approach to LLM red teaming, accelerating real-world deployment.