Preferred-Action-Optimized Diffusion Policies for Offline Reinforcement Learning
作者: Tianle Zhang, Jiayi Guan, Lin Zhao, Yihang Li, Dongjiang Li, Zecui Zeng, Lei Sun, Yue Chen, Xuelong Wei, Lusong Li, Xiaodong He
分类: cs.LG, cs.AI
发布日期: 2024-05-29
💡 一句话要点
提出基于偏好动作优化的扩散策略,提升离线强化学习性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 扩散模型 策略优化 偏好动作 抗噪声优化
📋 核心要点
- 现有离线强化学习方法依赖加权回归优化扩散策略,易受Q值影响,限制了性能提升。
- 提出偏好动作优化扩散策略,利用critic函数生成偏好动作,并进行抗噪声优化。
- 实验表明,该方法在稀疏奖励任务中表现优异,超越现有方法,并验证了抗噪声优化的有效性。
📝 摘要(中文)
离线强化学习旨在从预先收集的数据集中学习最优策略。最近,由于其强大的表征能力,扩散模型作为离线强化学习策略模型展现出巨大潜力。然而,先前基于扩散策略的离线强化学习算法通常采用加权回归来改进策略。这种方法仅使用收集到的动作来优化策略,并且对Q值敏感,限制了进一步性能提升的潜力。为此,我们提出了一种新颖的偏好动作优化扩散策略用于离线强化学习。特别地,利用一个富有表现力的条件扩散模型来表示行为策略的多样化分布。同时,基于扩散模型,通过critic函数自动生成同一行为分布内的偏好动作。此外,设计了一种抗噪声偏好优化,通过使用偏好动作来实现策略改进,该优化可以适应噪声偏好动作以实现稳定训练。大量实验表明,与先前的最先进的离线强化学习方法相比,所提出的方法提供了有竞争力的或更优越的性能,尤其是在稀疏奖励任务中,例如Kitchen和AntMaze。此外,我们通过实验证明了抗噪声偏好优化的有效性。
🔬 方法详解
问题定义:论文旨在解决离线强化学习中,现有基于扩散模型的策略优化方法对Q值敏感,导致策略改进受限的问题。现有方法通常采用加权回归,直接依赖数据集中的动作进行策略优化,忽略了同一状态下可能存在更优动作的可能性。
核心思路:论文的核心思路是利用critic函数评估状态-动作对的价值,从而在行为策略的分布中识别并生成“偏好动作”。通过优化策略使其更倾向于这些偏好动作,从而实现策略的改进。同时,为了应对critic函数可能存在的噪声,引入抗噪声优化机制,提高训练的稳定性。
技术框架:整体框架包含以下几个主要模块:1) 条件扩散模型:用于表示行为策略的动作分布;2) Critic网络:用于评估状态-动作对的价值,并生成偏好动作;3) 偏好动作生成模块:基于扩散模型和Critic网络,生成同一行为分布内的偏好动作;4) 抗噪声偏好优化模块:通过优化策略,使其更倾向于偏好动作,并抑制噪声动作的影响。
关键创新:论文的关键创新在于提出了偏好动作优化的概念,并将其应用于扩散策略的离线强化学习中。与传统的加权回归方法不同,该方法不直接依赖数据集中的动作,而是通过Critic网络生成偏好动作,从而实现更有效的策略改进。此外,抗噪声优化机制进一步提高了训练的鲁棒性。
关键设计:论文的关键设计包括:1) 使用条件扩散模型来表示行为策略,能够捕捉动作分布的多样性;2) 利用Critic网络生成偏好动作,为策略优化提供更有效的目标;3) 设计抗噪声偏好优化损失函数,例如通过clip Q value或者使用其他鲁棒的损失函数,以减少噪声动作的影响。具体的网络结构和参数设置需要参考论文原文。
🖼️ 关键图片
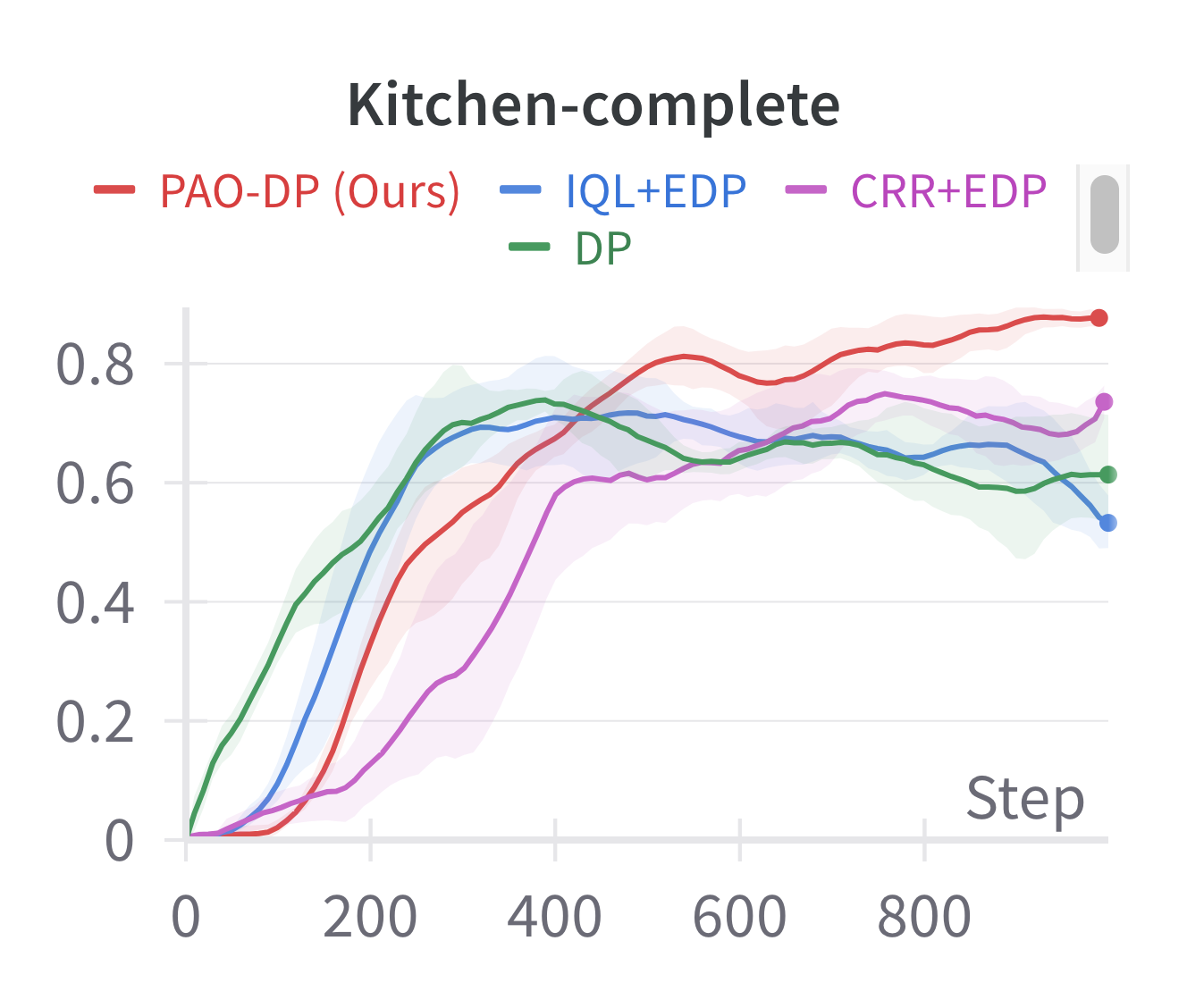


📊 实验亮点
实验结果表明,该方法在多个离线强化学习benchmark上取得了显著的性能提升,尤其是在稀疏奖励任务(如Kitchen和AntMaze)中表现突出,超越了现有的state-of-the-art方法。此外,实验还验证了抗噪声偏好优化的有效性,证明其能够提高训练的稳定性和鲁棒性。
🎯 应用场景
该研究成果可应用于各种需要离线策略学习的场景,例如机器人控制、自动驾驶、推荐系统等。在这些场景中,通常难以进行在线探索,只能依赖预先收集的数据集进行策略学习。该方法能够有效利用离线数据,学习到更优的策略,提高系统的性能和效率,具有重要的实际应用价值。
📄 摘要(原文)
Offline reinforcement learning (RL) aims to learn optimal policies from previously collected datasets. Recently, due to their powerful representational capabilities, diffusion models have shown significant potential as policy models for offline RL issues. However, previous offline RL algorithms based on diffusion policies generally adopt weighted regression to improve the policy. This approach optimizes the policy only using the collected actions and is sensitive to Q-values, which limits the potential for further performance enhancement. To this end, we propose a novel preferred-action-optimized diffusion policy for offline RL. In particular, an expressive conditional diffusion model is utilized to represent the diverse distribution of a behavior policy. Meanwhile, based on the diffusion model, preferred actions within the same behavior distribution are automatically generated through the critic function. Moreover, an anti-noise preference optimization is designed to achieve policy improvement by using the preferred actions, which can adapt to noise-preferred actions for stable training. Extensive experiments demonstrate that the proposed method provides competitive or superior performance compared to previous state-of-the-art offline RL methods, particularly in sparse reward tasks such as Kitchen and AntMaze. Additionally, we empirically prove the effectiveness of anti-noise preference optimization.