Zipper: A Multi-Tower Decoder Architecture for Fusing Modalities
作者: Vicky Zayats, Peter Chen, Melissa Ferrari, Dirk Padfield
分类: cs.LG, cs.AI, cs.CL, eess.AS
发布日期: 2024-05-29 (更新: 2024-05-31)
备注: Under review at NeurIPS
💡 一句话要点
Zipper:一种用于融合多模态信息的多塔解码器架构
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态融合 生成模型 交叉注意力 语音识别 语音合成 多塔解码器 预训练模型
📋 核心要点
- 现有方法难以有效融合不同模态的生成模型,尤其是在对齐数据有限的情况下,且容易损害单模态生成能力。
- Zipper架构通过交叉注意力机制,灵活组合独立预训练的单模态解码器,实现多模态生成模型的构建。
- 实验表明,Zipper在有限对齐数据下表现出色,并能选择性保持单模态性能,在ASR和TTS任务中取得优异结果。
📝 摘要(中文)
将多个生成式预训练模型,特别是那些在不同模态上训练的模型,整合以实现大于各部分之和的效果,面临着重大挑战。两个关键障碍是:对齐数据的可用性(即在不同模态中以不同方式表达但含义相似的概念),以及在跨域生成任务中有效利用单模态表示,而不损害其原始的单模态能力。我们提出了Zipper,一种多塔解码器架构,通过使用交叉注意力灵活地组合来自独立预训练的单模态解码器的多模态生成模型,从而解决这些问题。在融合语音和文本模态的实验中,我们表明所提出的架构在对齐的文本-语音数据有限的情况下表现出很强的竞争力。我们还展示了我们模型选择性地保持单模态(例如,文本到文本生成)生成性能的灵活性,通过冻结相应的模态塔(例如,文本)。在诸如自动语音识别(ASR)等输出模态为文本的跨模态任务中,我们表明冻结文本骨干网络会导致可忽略不计的性能下降。在诸如文本到语音生成(TTS)等输出模态为语音的跨模态任务中,我们表明使用预训练的语音骨干网络会产生优于基线的性能。
🔬 方法详解
问题定义:论文旨在解决多模态融合中,尤其是在数据对齐有限的情况下,如何有效利用多个预训练的单模态生成模型,同时避免损害其原始单模态能力的问题。现有方法在处理模态差异和数据稀疏性方面存在痛点,难以充分发挥各模态的优势。
核心思路:论文的核心思路是利用多塔解码器架构,每个塔对应一个模态,并通过交叉注意力机制实现模态间的信息交互。这种设计允许模型灵活地组合来自独立预训练的单模态解码器,从而实现多模态生成,同时保留各模态的独立性。
技术框架:Zipper架构包含多个解码器塔,每个塔负责处理一种模态。每个塔都是一个独立的预训练解码器,例如文本解码器或语音解码器。在多模态生成过程中,通过交叉注意力机制,每个塔可以访问其他塔的表示,从而实现模态间的信息融合。整个框架可以端到端训练,也可以选择性地冻结某些塔,以保持其单模态性能。
关键创新:Zipper的关键创新在于其多塔解码器架构和交叉注意力机制。这种架构允许模型灵活地组合来自独立预训练的单模态解码器,从而避免了从头开始训练多模态模型的需要。交叉注意力机制则实现了模态间的有效信息融合,同时保留了各模态的独立性。
关键设计:Zipper的关键设计包括:1) 使用预训练的单模态解码器作为塔,从而利用了已有的知识;2) 使用交叉注意力机制实现模态间的信息融合,具体实现方式未知;3) 允许选择性地冻结某些塔,以保持其单模态性能,具体冻结策略未知;4) 损失函数的设计未知,但应包含多模态生成和单模态生成的损失项。
🖼️ 关键图片

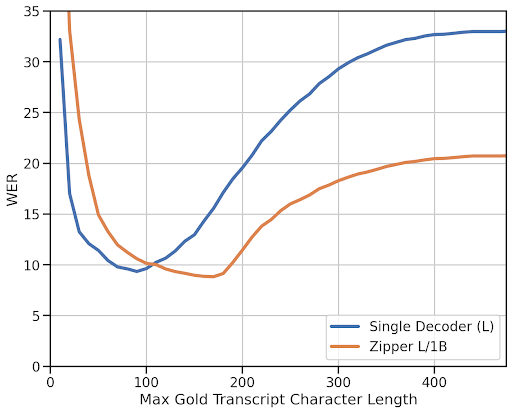

📊 实验亮点
论文在语音和文本模态融合的实验中,展示了Zipper架构在有限对齐数据下的竞争力。在自动语音识别(ASR)任务中,冻结文本骨干网络几乎没有造成性能下降。在文本到语音生成(TTS)任务中,使用预训练的语音骨干网络获得了优于基线的性能,具体提升幅度未知。
🎯 应用场景
Zipper架构可应用于多种多模态生成任务,如语音翻译、图像描述、视频字幕等。它能够有效利用不同模态的信息,提升生成质量和鲁棒性。该研究的实际价值在于降低了多模态模型训练的成本,并为跨模态信息融合提供了新的思路,未来可能促进更智能的人机交互和内容创作。
📄 摘要(原文)
Integrating multiple generative foundation models, especially those trained on different modalities, into something greater than the sum of its parts poses significant challenges. Two key hurdles are the availability of aligned data (concepts that contain similar meaning but is expressed differently in different modalities), and effectively leveraging unimodal representations in cross-domain generative tasks, without compromising their original unimodal capabilities. We propose Zipper, a multi-tower decoder architecture that addresses these concerns by using cross-attention to flexibly compose multimodal generative models from independently pre-trained unimodal decoders. In our experiments fusing speech and text modalities, we show the proposed architecture performs very competitively in scenarios with limited aligned text-speech data. We also showcase the flexibility of our model to selectively maintain unimodal (e.g., text-to-text generation) generation performance by freezing the corresponding modal tower (e.g. text). In cross-modal tasks such as automatic speech recognition (ASR) where the output modality is text, we show that freezing the text backbone results in negligible performance degradation. In cross-modal tasks such as text-to-speech generation (TTS) where the output modality is speech, we show that using a pre-trained speech backbone results in superior performance to the baseline.