Hardware-Aware Parallel Prompt Decoding for Memory-Efficient Acceleration of LLM Inference
作者: Hao Mark Chen, Wayne Luk, Ka Fai Cedric Yiu, Rui Li, Konstantin Mishchenko, Stylianos I. Venieris, Hongxiang Fan
分类: cs.LG, cs.CL
发布日期: 2024-05-28 (更新: 2025-09-29)
备注: Accepted at EMNLP 2025. The code for this implementation is available at https://github.com/hmarkc/parallel-prompt-decoding
🔗 代码/项目: GITHUB
💡 一句话要点
提出硬件感知并行Prompt解码(PPD),加速LLM推理并降低内存占用。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 LLM推理 并行解码 硬件感知 内存优化
📋 核心要点
- LLM自回归解码计算开销大,现有推测解码方法侧重速度,忽略了内存和训练成本。
- 提出并行Prompt解码(PPD),通过少量可训练参数,并行预测未来token,降低条件依赖损失。
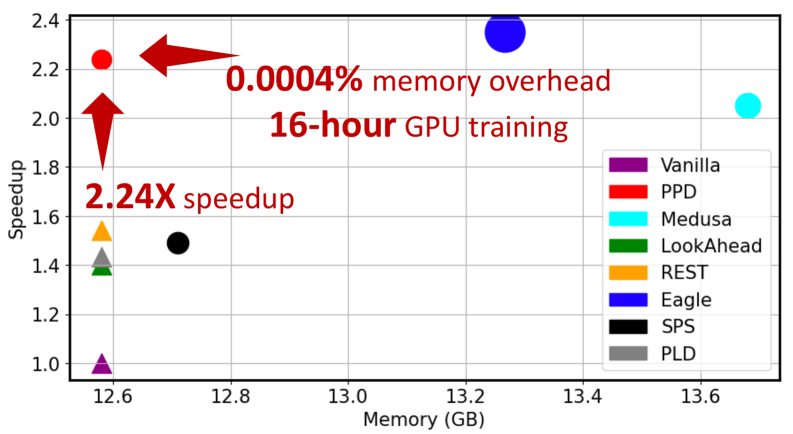
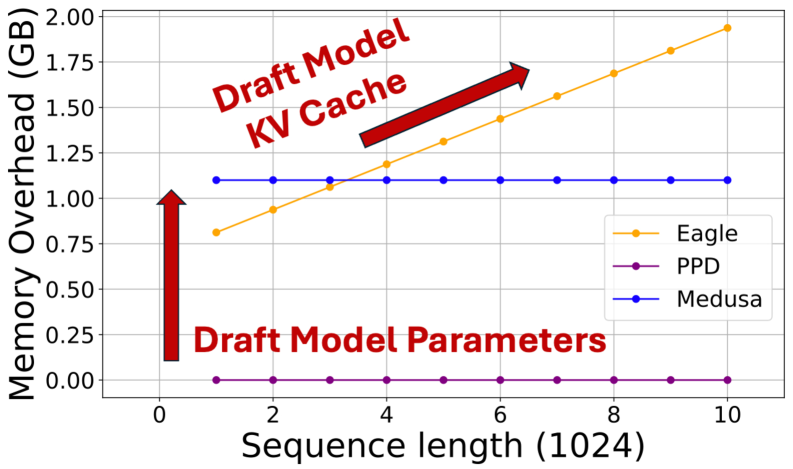
- 实验表明,PPD在多种LLM上实现了显著加速,内存开销极小,且可与现有推测解码方法结合。
📝 摘要(中文)
大型语言模型(LLM)的自回归解码导致硬件性能显著开销。现有推测解码技术主要关注吞吐量等处理速度的提升,忽略了内存消耗和训练成本等实际部署的关键指标。为克服这些限制,我们提出了一种新型并行prompt解码(PPD),仅需0.0002%的可训练参数,即可在单个A100-40GB GPU上高效训练,耗时仅16小时。PPD受人类自然语言生成过程启发,通过使用多个prompt token并行近似未来时间步生成的输出,部分恢复多token生成所需的条件依赖信息,从而使长程预测的接受率提高28%。此外,我们提出了一种硬件感知的动态稀疏树技术,自适应地优化解码方案,充分利用不同GPU的计算能力。在MobileLlama到Vicuna-13B等LLM以及各种基准测试中,我们的方法实现了高达2.49倍的加速,并保持了仅0.0004%的最小运行时内存开销。更重要的是,我们的并行prompt解码可以作为现有推测解码的正交优化,实现高达1.22倍的进一步加速。代码已开源。
🔬 方法详解
问题定义:大型语言模型(LLM)的自回归解码过程计算量大,严重影响硬件性能。现有的推测解码方法主要关注提高吞吐量,但忽略了实际部署中至关重要的内存消耗和训练成本问题。这些方法通常需要大量的计算资源和内存空间,限制了它们在资源受限环境中的应用。
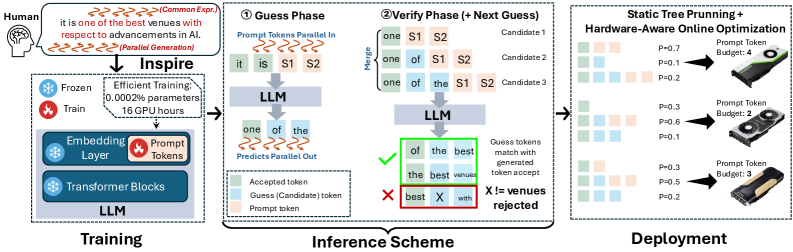
核心思路:本论文的核心思路是提出一种并行Prompt解码(PPD)方法,该方法通过使用多个prompt token并行地预测未来时间步的输出,从而减少自回归解码的依赖性。PPD旨在通过近似模拟人类的自然语言生成过程,部分恢复多token生成所需的条件依赖信息,从而在保证生成质量的同时,显著提高解码速度和降低内存占用。
技术框架:PPD的技术框架主要包括以下几个阶段:1) Prompt Token生成:使用少量可训练参数生成多个prompt token,这些token用于并行地预测未来的输出。2) 并行解码:利用生成的prompt token,并行地解码多个token,从而减少自回归解码的串行依赖性。3) 硬件感知动态稀疏树优化:根据不同GPU的计算能力,自适应地优化解码方案,充分利用硬件资源。4) 结果验证与整合:验证并行解码的结果,并将其整合到最终的输出序列中。
关键创新:PPD最重要的技术创新点在于其并行解码的思路,它与传统的自回归解码和现有的推测解码方法有着本质的区别。传统的自回归解码是串行的,而PPD通过并行预测多个token,显著减少了计算量。现有的推测解码方法通常需要大量的计算资源和内存空间,而PPD仅需少量可训练参数,即可实现高效的解码。此外,硬件感知动态稀疏树优化也是一个重要的创新点,它可以根据不同的硬件环境,自适应地调整解码策略,从而充分利用硬件资源。
关键设计:PPD的关键设计包括:1) Prompt Token生成器的设计:使用少量可训练参数,以降低训练成本和内存占用。2) 并行解码策略的设计:平衡并行度和生成质量,以实现最佳的性能。3) 硬件感知动态稀疏树的优化策略:根据不同GPU的计算能力,自适应地调整解码策略。4) 损失函数的设计:用于训练Prompt Token生成器,以保证生成的prompt token能够有效地预测未来的输出。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PPD在多种LLM(MobileLlama到Vicuna-13B)和基准测试中实现了显著的性能提升。具体来说,PPD实现了高达2.49倍的加速,并保持了仅0.0004%的最小运行时内存开销。此外,PPD可以与现有推测解码方法结合使用,实现高达1.22倍的进一步加速。该方法仅需0.0002%的可训练参数,即可在单个A100-40GB GPU上高效训练,耗时仅16小时。
🎯 应用场景
该研究成果可应用于各种需要加速LLM推理并降低内存占用的场景,例如移动设备、边缘计算设备和资源受限的服务器。它能够提升LLM在这些场景下的部署效率,并降低部署成本。此外,该方法还可以与其他推测解码技术结合使用,进一步提高LLM的推理速度。
📄 摘要(原文)
The auto-regressive decoding of Large Language Models (LLMs) results in significant overheads in their hardware performance. While recent research has investigated various speculative decoding techniques for multi-token generation, these efforts have primarily focused on improving processing speed such as throughput. Crucially, they often neglect other metrics essential for real-life deployments, such as memory consumption and training cost. To overcome these limitations, we propose a novel parallel prompt decoding that requires only $0.0002$% trainable parameters, enabling efficient training on a single A100-40GB GPU in just 16 hours. Inspired by the human natural language generation process, $PPD$ approximates outputs generated at future timesteps in parallel by using multiple prompt tokens. This approach partially recovers the missing conditional dependency information necessary for multi-token generation, resulting in up to a 28% higher acceptance rate for long-range predictions. Furthermore, we present a hardware-aware dynamic sparse tree technique that adaptively optimizes this decoding scheme to fully leverage the computational capacities on different GPUs. Through extensive experiments across LLMs ranging from MobileLlama to Vicuna-13B on a wide range of benchmarks, our approach demonstrates up to 2.49$\times$ speedup and maintains a minimal runtime memory overhead of just $0.0004$%. More importantly, our parallel prompt decoding can serve as an orthogonal optimization for synergistic integration with existing speculative decoding, showing up to $1.22\times$ further speed improvement. Our code is available at https://github.com/hmarkc/parallel-prompt-decoding.