Low-rank finetuning for LLMs: A fairness perspective
作者: Saswat Das, Marco Romanelli, Cuong Tran, Zarreen Reza, Bhavya Kailkhura, Ferdinando Fioretto
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-05-28
💡 一句话要点
揭示低秩微调LLM在公平性上的局限性,强调偏差和毒性缓解的挑战
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低秩微调 大型语言模型 公平性 偏差 毒性 模型评估 分布偏移
📋 核心要点
- 现有低秩微调方法在捕获微调数据集与预训练数据分布的偏移方面存在不足,可能导致模型无法有效学习目标任务。
- 论文核心思想是揭示低秩微调在公平性方面的局限性,尤其是在减轻毒性和消除偏差等任务中。
- 实验结果表明,低秩微调可能无意中保留了预训练模型中固有的偏见和有毒行为,影响模型公平性。
📝 摘要(中文)
低秩近似技术因其降低的计算和内存需求,已成为微调大型语言模型(LLMs)的事实标准。本文研究了这些方法在捕获微调数据集相对于初始预训练数据分布的偏移方面的有效性。研究结果表明,在某些情况下,低秩微调无法充分学习这种偏移。这反过来会产生不可忽略的副作用,尤其是在采用微调来减轻预训练模型中的毒性,或在提供公平模型至关重要的场景中。通过对多个模型、数据集和任务的全面实证研究,我们表明低秩微调无意中保留了不良的偏见和有毒行为。我们还表明,这种情况也延伸到序贯决策任务中,强调需要仔细评估以促进负责任的LLM开发。
🔬 方法详解
问题定义:论文关注的问题是,当使用低秩微调技术对大型语言模型进行微调时,模型在学习微调数据集与预训练数据分布之间的差异时可能存在不足,尤其是在需要减轻毒性或确保公平性的场景下。现有方法的痛点在于,低秩微调可能无法充分捕获这种分布偏移,从而导致模型保留了预训练数据中的不良偏见和有毒行为。
核心思路:论文的核心思路是通过实证研究,揭示低秩微调在公平性方面的局限性。通过在不同的模型、数据集和任务上进行实验,证明低秩微调可能无法有效消除预训练模型中固有的偏见和毒性,甚至可能加剧这些问题。这种设计旨在强调在采用低秩微调时,需要仔细评估其对模型公平性的影响。
技术框架:论文采用实证研究的方法,没有提出新的技术框架。其研究流程主要包括:1) 选择不同的预训练语言模型、微调数据集和任务;2) 使用低秩微调技术对模型进行微调;3) 评估微调后模型在公平性指标上的表现,例如毒性、偏见等;4) 分析实验结果,揭示低秩微调在公平性方面的局限性。
关键创新:论文的关键创新在于,它首次从公平性的角度系统地研究了低秩微调的局限性。虽然低秩微调在降低计算成本方面具有优势,但论文指出,这种方法可能无法有效消除预训练模型中固有的偏见和毒性。与现有方法相比,论文强调了在采用低秩微调时,需要更加关注模型公平性的问题。
关键设计:论文没有提出新的算法或模型结构,而是侧重于实验设计和分析。关键的设计包括:1) 选择具有代表性的预训练语言模型,例如BERT、RoBERTa等;2) 选择包含偏见或毒性的微调数据集,例如包含性别歧视或种族歧视的数据集;3) 使用标准的公平性评估指标,例如毒性评分、偏见评分等;4) 对实验结果进行统计分析,以验证低秩微调在公平性方面的局限性。
🖼️ 关键图片
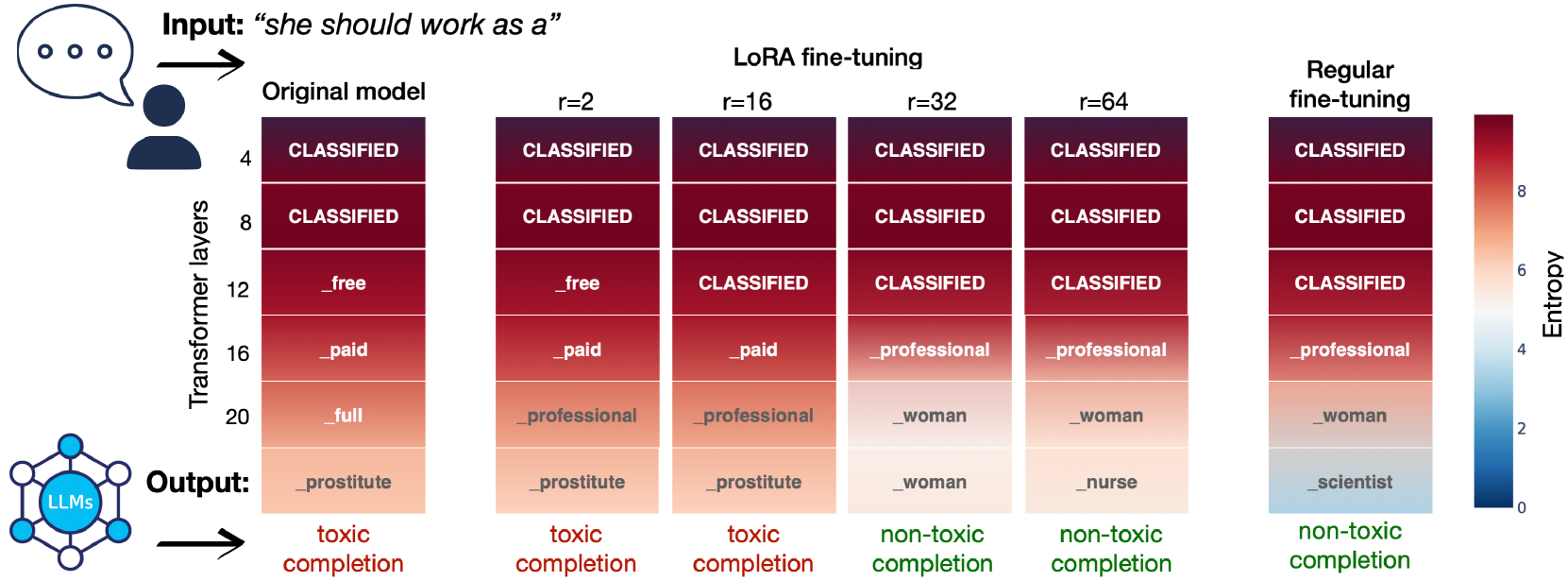


📊 实验亮点
实验结果表明,低秩微调在减轻预训练模型中的毒性和偏见方面效果有限,甚至可能加剧这些问题。在某些情况下,使用低秩微调的模型在公平性指标上的表现明显低于预期,表明该方法可能无法有效捕获微调数据集中的分布偏移。
🎯 应用场景
该研究成果可应用于对大型语言模型进行负责任的开发和部署。在微调LLM以减轻毒性、消除偏见或提高公平性时,需要谨慎评估低秩微调的潜在局限性。该研究有助于开发更公平、更安全的AI系统,并促进负责任的AI创新。
📄 摘要(原文)
Low-rank approximation techniques have become the de facto standard for fine-tuning Large Language Models (LLMs) due to their reduced computational and memory requirements. This paper investigates the effectiveness of these methods in capturing the shift of fine-tuning datasets from the initial pre-trained data distribution. Our findings reveal that there are cases in which low-rank fine-tuning falls short in learning such shifts. This, in turn, produces non-negligible side effects, especially when fine-tuning is adopted for toxicity mitigation in pre-trained models, or in scenarios where it is important to provide fair models. Through comprehensive empirical evidence on several models, datasets, and tasks, we show that low-rank fine-tuning inadvertently preserves undesirable biases and toxic behaviors. We also show that this extends to sequential decision-making tasks, emphasizing the need for careful evaluation to promote responsible LLMs development.