Offline-Boosted Actor-Critic: Adaptively Blending Optimal Historical Behaviors in Deep Off-Policy RL
作者: Yu Luo, Tianying Ji, Fuchun Sun, Jianwei Zhang, Huazhe Xu, Xianyuan Zhan
分类: cs.LG, cs.AI
发布日期: 2024-05-28
💡 一句话要点
提出离线增强的Actor-Critic算法,自适应融合历史最优行为以提升深度离线策略强化学习性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 在线强化学习 Actor-Critic 策略优化 自适应约束
📋 核心要点
- 现有离线策略强化学习算法未能充分利用回放缓冲区信息,导致样本效率和策略性能受限。
- OBAC通过价值比较识别出表现优异的离线策略,并将其作为自适应约束,提升在线策略学习性能。
- 实验结果表明,OBAC在多个任务中优于其他无模型RL基线,并可与先进的基于模型的RL方法竞争。
📝 摘要(中文)
离线策略强化学习(RL)通过利用先前收集的数据进行策略学习,在解决许多复杂的现实世界任务中取得了显著的成功。然而,大多数现有的离线策略RL算法未能最大限度地利用回放缓冲区中的信息,从而限制了样本效率和策略性能。本文发现,基于共享的在线回放缓冲区并发训练一个离线RL策略有时可以优于原始的在线学习策略,尽管这种性能提升的发生仍然不确定。这激发了一种新的可能性,即利用涌现的、表现优异的离线最优策略来改善在线策略学习。基于这一洞察,我们提出了离线增强的Actor-Critic (OBAC),这是一个无模型的在线RL框架,它通过价值比较优雅地识别出表现优异的离线策略,并将其用作自适应约束,以保证更强的策略学习性能。我们的实验表明,在跨越6个任务套件的53个任务中,OBAC在样本效率和渐近性能方面优于其他流行的无模型RL基线,并且可以与先进的基于模型的RL方法相媲美。
🔬 方法详解
问题定义:现有离线策略强化学习算法在利用回放缓冲区中的历史数据时存在不足,无法充分挖掘数据中的信息,导致样本效率低下,最终影响策略的性能。虽然离线RL可以利用历史数据,但如何有效地将离线学习的优势融入到在线学习中,从而提升整体性能,是一个关键问题。
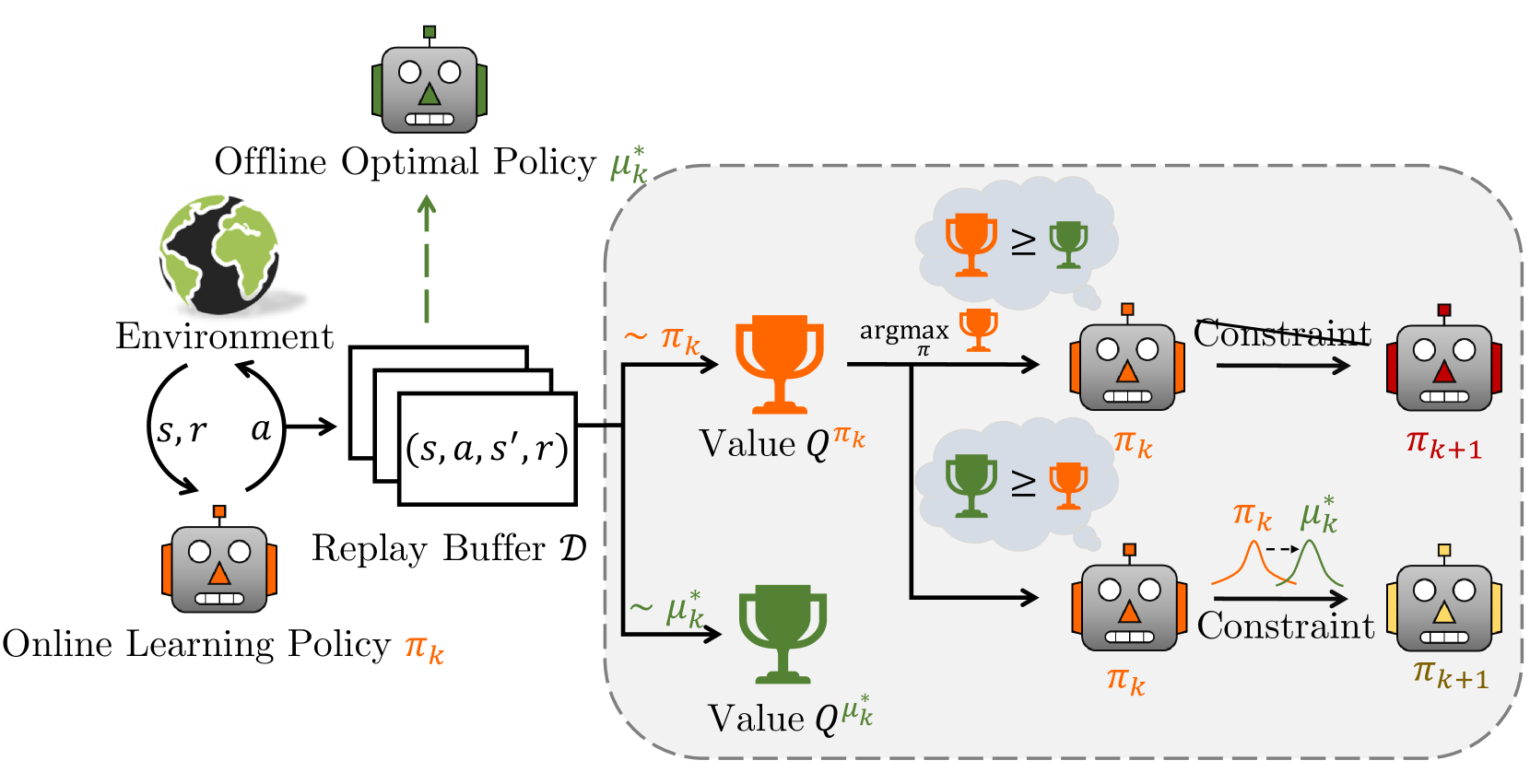
核心思路:论文的核心思路是同时训练一个在线策略和一个离线策略,并利用离线策略的优势来指导在线策略的学习。具体来说,通过价值比较来判断离线策略是否优于在线策略,如果离线策略更优,则将其作为一种约束,引导在线策略向更好的方向发展。这种自适应地融合离线策略的方式,可以在保证在线学习效率的同时,充分利用历史数据中的信息。
技术框架:OBAC框架包含一个在线Actor-Critic网络和一个离线Actor-Critic网络。在线网络负责与环境交互并收集数据,离线网络则利用回放缓冲区中的历史数据进行学习。框架通过价值比较模块来判断离线策略是否优于在线策略。如果离线策略更优,则通过一个自适应约束模块,将离线策略的信息融入到在线策略的学习过程中。整个框架采用Actor-Critic结构,通过优化Actor和Critic网络来提升策略性能。
关键创新:OBAC的关键创新在于自适应地融合离线策略。与传统的离线RL方法不同,OBAC不是简单地使用离线数据进行预训练或微调,而是动态地评估离线策略的性能,并根据评估结果来调整离线策略对在线策略的影响。这种自适应融合的方式可以更有效地利用离线数据,并避免离线策略的偏差对在线学习产生负面影响。
关键设计:OBAC的关键设计包括价值比较模块和自适应约束模块。价值比较模块通过比较在线和离线策略的Q值来判断离线策略的优劣。自适应约束模块则根据离线策略的Q值和在线策略的Q值之间的差异,来调整离线策略对在线策略的影响程度。具体的损失函数设计中,可能包含在线Actor-Critic的损失函数,以及一个用于约束在线策略接近离线策略的正则化项。网络结构方面,在线和离线Actor-Critic网络可以采用相同的结构,例如多层感知机或卷积神经网络。
🖼️ 关键图片


📊 实验亮点
实验结果表明,OBAC在53个任务中,样本效率和渐近性能均优于其他流行的无模型RL基线,并且可以与先进的基于模型的RL方法相媲美。具体来说,OBAC在某些任务中能够达到比基线方法更高的平均奖励,并且收敛速度更快,证明了其在利用离线数据方面的优势。
🎯 应用场景
OBAC算法可应用于机器人控制、自动驾驶、游戏AI等领域。在这些领域中,通常存在大量的历史数据,但直接使用这些数据进行离线学习可能效果不佳。OBAC算法通过自适应地融合离线策略,可以更有效地利用历史数据,提升策略学习的效率和性能,从而加速这些领域的智能化进程。
📄 摘要(原文)
Off-policy reinforcement learning (RL) has achieved notable success in tackling many complex real-world tasks, by leveraging previously collected data for policy learning. However, most existing off-policy RL algorithms fail to maximally exploit the information in the replay buffer, limiting sample efficiency and policy performance. In this work, we discover that concurrently training an offline RL policy based on the shared online replay buffer can sometimes outperform the original online learning policy, though the occurrence of such performance gains remains uncertain. This motivates a new possibility of harnessing the emergent outperforming offline optimal policy to improve online policy learning. Based on this insight, we present Offline-Boosted Actor-Critic (OBAC), a model-free online RL framework that elegantly identifies the outperforming offline policy through value comparison, and uses it as an adaptive constraint to guarantee stronger policy learning performance. Our experiments demonstrate that OBAC outperforms other popular model-free RL baselines and rivals advanced model-based RL methods in terms of sample efficiency and asymptotic performance across 53 tasks spanning 6 task suites.